一、GlusterFS介绍
GlusterFS是一个高层次的分布式文件系统解决方案。通过增加一个逻辑层,对上层使用者掩盖了下面的实现,使用者不用了解也不需知道,文件的存储形式、分布。内部实现是整合了许多存储块并通过Infiniband RDMA或者 tcp/ip方式互联的一个并行的网络文件系统,这样的许多存储块可以通过许多廉价的x86主机,通过网络搭建起来。
二、适用场景
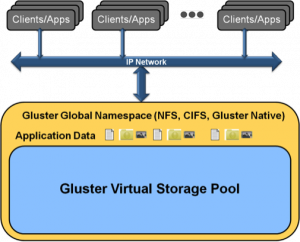
GlusterFS支持运行在任何标准IP网络上标准应用程序的标准客户端,如下图所示,用户可以在全局统一的命名空间中使用NFS/CIFS等标准协议来访问应用数据。GlusterFS采用弹性哈希算法数据分布策略,移除了元数据依赖,优化了数据分布,提高数据访问并行性,能够大幅提高大文件存储的性能。对于小文件,无元数据服务设计解决了元数据的问题。但GlusterFS并没有在I/O方面作优化,在存储服务器底层文件系统上仍然是大量小文件,本地文件系统元数据访问是一个瓶颈,数据分布和并行性也无法充分发挥作用。因此,GlusterFS适合存储大文件,小文件性能较差,还存在很大优化空间。
三、设计理念
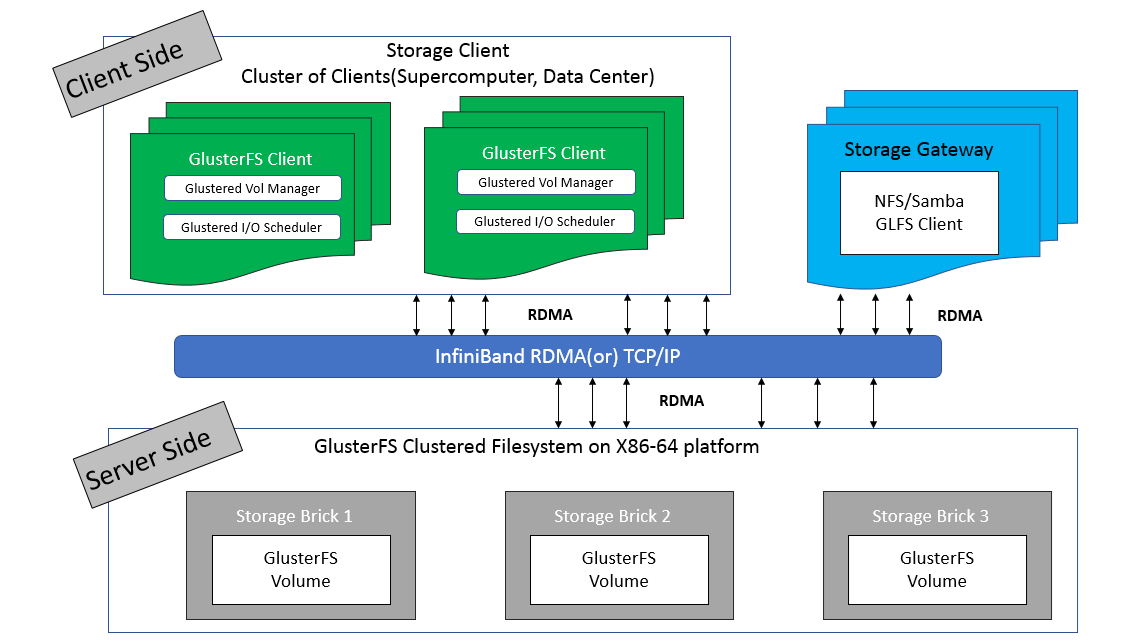
如下图所示GlusterFS主要由存储服务器、客户端以及 NFS/SAMBA 存储网关组成。不难发现,GlusterFS 架构中没有元数据服务器组件,这是其最大的设计点,对于提升整个系统的性能、可靠性和稳定性都有着决定性的意义。无元数据服务器设计的好处是没有单点故障和性能瓶颈问题,可提高系统扩展性、性能、可靠性和稳定性。对于海量小文件应用,这种设计能够有效解决元数据的难点问题。它的负面影响是,数据一致问题更加复杂,文件目录遍历操作效率低下,缺乏全局监控管理功能。同时也导致客户端承担了更多的职能,比如文件定位、名字空间缓存、逻辑卷视图维护等等,这些都增加了客户端的负载,占用相当的CPU和内存。
四、卷的模式
为了满足不同应用对高性能、高可用的需求,GlusterFS 支持 7 种卷,即 distribute 卷、stripe 卷、replica 卷、distribute stripe 卷、distribute replica 卷、stripe Replica 卷、distribute stripe replica 卷。其实不难看出,GlusterFS的卷类型实际上可以分为3种基本卷和4种复合卷,每种类型的卷都有其自身的特点和适用场景。在企业生产环境中使用最多的是复合卷中的distribute replica 卷,即分布式复制卷。下面简单介绍一下分布式复制卷,如图:

类似于RAID10,其中Brick server 数量是镜像数的倍数,兼具 distribute 和 replica 卷的特点,可以在 2 个或多个节点之间复制数据。分布式的复制卷,volume 中 brick 所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。
五、搭建部署
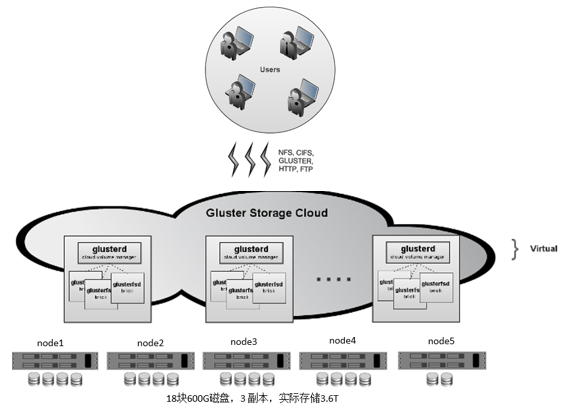
测试环境如下,配置5台服务器,除去系统盘,共使用18块600G数据盘,在每台服务器上部署Glusterfs-Server系列服务,并将数据盘均格式化为XFS文件系统,为保证数据安全,在测试中卷类型采用distribute replica卷,并提供3副本冗余模式,如图:
服务器IP分配:
node1:192.168.0.100
node2:192.168.0.101
node3:192.168.0.102
node4:192.168.0.103
node5:192.168.0.104
以上服务器均为Centos6.9版本,且每台对外提供四块600G数据盘,下面来看:
我这五台服务器需要在/etc/hosts中均加入IP对应服务器名称的解析,并且每台服务器上的硬盘均是/sda、/sdb、/sdc、/sdd
之后进行格式化:
mkfs.xfs /dev/sda mkfs.xfs /dev/sdb mkfs.xfs /dev/sdc mkfs.xfs /dev/sdd
然后创建挂载目录,并挂载结果如下所示,每台都一样:

在每台服务器上均安装glusterfs的一些软件包如下:
yum install centos-release-gluster312 -y yum install glusterfs-server -y
这里我使用的是3.12版本,版本有点老,截止2018年11月已经出到5.x版本了,其中centos6 不能支持glusterfs的4和5版本。
首先每台服务器上启动glusterfs,执行:
service glusterfsd start
然后每台服务器进行互相探测,例如在node1上执行:

每台执行完后才能后可以使用 gluster peer status 进行查看状态。
下面就可以进行配置分布式复制卷了,我们起名字叫test1,执行如下:(在任意节点执行都可以的)
gluster volume create test replica 3 transport tcp node1:/data1 node2:/data1 node3:/data1 node4:/data1 node5:/data1 node1:/data2 node2:/data2 node3:/data2 node4:/data2 node5:/data2 node1:/data3 node2:/data3 node3:/data3 node4:/data3 node5:/data3 node1:/data4 node2:/data4 node3:/data4 force
其中需要注意的一些事项在介绍分布式复制卷的时候已经阐明了,比如复制的份数和磁盘的关系,以及数据分布的一些需要注意的事项,
详细的可以参考官方文档:https://docs.gluster.org/en/latest/Administrator%20Guide/Setting%20Up%20Volumes/
之后可以启动进行查看:
gluster volume start test1
执行:
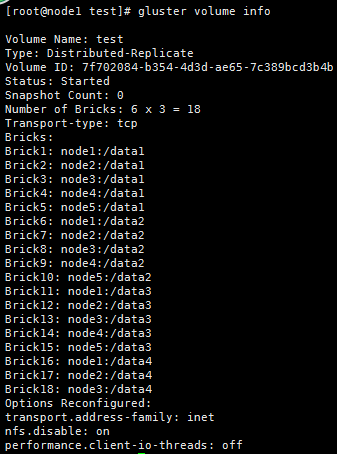
gluster volume info
或者执行:
gluster volume status
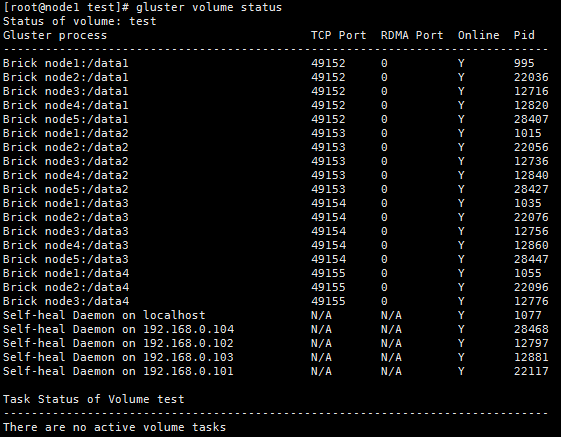
这时就可以在其他服务器上进行挂载并测试了:
mount -t glusterfs node4:test1 /test/ 在这里面写成node 几都是可以的
总的来说搭建是比较简单的。