pathlib 对象化路径管理,配合动态库解决import依赖
当import导入模块式,默认情况下python解析器遍历存放在sys.path中的搜索路径,在写代码时可以使用动态引用,配合pathlib对象化的管理文件系统路径,如:
import os import sys import pathlib __dir__ = pathlib.Path(os.path.abspath(__file__)) sys.path.append(str(__dir__.parent.parent))
- __file__表示当前文件的相对路径
- pathlib是python自带的标准库,相比于os.path可以更简单快捷的进行文件路径操作:
- 将文件地址抽象化为一个pathlib.Path的对象,它允许我们链式操作 Path 对象上的方法和属性,以获得等效的路径表示;
- 使用str函数可以把一个Path对象转化成字符串
- 可以使用 / 进行路径的拼接,如:
In : Path('/') / 'home' / 'dongwm/code' Out: PosixPath('/home/dongwm/code') In : '/' / Path('home') / 'dongwm/code' Out: PosixPath('/home/dongwm/code')
- Path还有许多自带的属性,如parent/parents属性获得父目录,如suffix/stem获得后缀名或者文件名
- 其他的内容可以参考:https://zhuanlan.zhihu.com/p/87940289
glob模块 筛选特定规则的文件列表
glob模块提供了方便的文件模式匹配方法,它可以支持以下格式的语法:
- * 匹配1个或多个字符
- ? 匹配任意单个字符
[]匹配指定范围内的字符,如:[0-9]匹配数字。- ** 匹配任意文件、0个或多个文件夹(当 recursive = true)
>>> import glob >>> glob.glob('./[0-9].*') ['./1.gif', './2.txt']
>>> glob.glob('**/*.txt', recursive=True) ['2.txt', 'sub/3.txt']
pathlib.Path也有glob方法,如列出当前目录树下所有的python源文件:
>>> list(p.glob('**/*.py')) [PosixPath('test_pathlib.py'), PosixPath('docs/conf.py')]
值得注意的是,glob库返回的顺序是不确定的,在使用中最好使用natsort.natsorted进行排序,这个库可以用更自然的方式进行排序,如
file_list = [x for x in glob.glob(folder_path + '/**/*.*', recursive=True) if os.path.splitext(x)[-1] in p_postfix] return natsorted(file_list)
pickle模块,序列化Python对象
pickle模块可以将任意python对象转化为二进制字节,并将字节重构为具有相同特征的对象,进而实现python对象的传递和保存。具体来看,该模块内使用pickle.dump()/dumps()进行编码,使用pickle.load()/loads()进行解码,前者转换为pkl文件形式,后者保存为字符串形式;
data_string = pickle.dumps(data) data_from_string = pickle.loads(data_string) with open("data.pkl", "wb") as f: pickle.dump(data, f) data_from_file = pickle.load(f)
值得注意的是,在编码时隐藏了一个protocol参数,这个参数默认为0,它定义了不同的编码方式:
- 0:原始的ASCII码编码
- 1:二进制编码格式
- 2:更有效的二进制码编码
而在使用load进行解码时,无需指定使用的协议。
Json模块
json是一种轻量级的数据交换格式,他的基础结构有两种:键值对(对象 dict)和数组结构,即其内部存储为以下的形式,可以使用json.dumps()将其转化为Json String,并使用loads()从字符串中解析。
可以将下述的类型转化为json: dict list tuple string int float True False None; 使用用indent参数定义缩进; 使用sort_keys参数能够将json的属性排序;
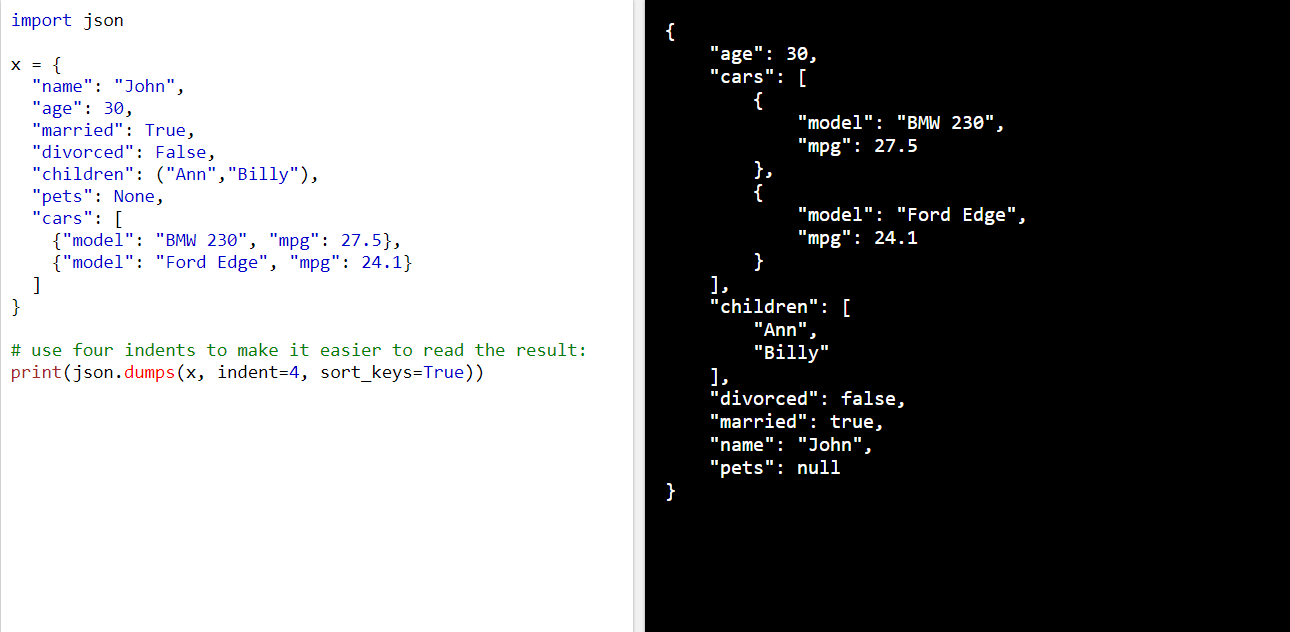
与pickle模块类似,使用json,dump()和json.load(),将对象保存为json形式的文件,起接口具体定义如链接
具体实例如下,其中ensure_ascii用来保证所有输入的非ASCII字符都被转义。如果 ensure_ascii 为 false,这些字符将按原样输出。
with open(file_path, 'w', encoding='utf-8') as json_file: json.dump(data, json_file, ensure_ascii=False, indent=4) with open(file_path, 'r', encoding='utf8') as f: content = json.load(f)
shutil模块删除和复制文件夹
当需要对文件进行复制和删除等操作时,之前常使用subprocess模块调用子进程来实现,具体见链接https://www.jianshu.com/p/e5880de429f2
但python自带的shutil库提供了对文件和文件夹的高阶操作,可以弥补os模块的不足,如使用os.remove可以删除文件,使用os.removedirs可以删除空文件夹,但对非空文件夹的删除操作是复杂的。
shutil就能解决这样的问题,具体来看,使用shutil.copy进行文件复制,使用shutil.copytree进行文件夹的复制,使用shutil.rmtree删除非空文件夹,使用shutil.make_archive生成压缩文件;
>>>shutil.copy("test.file", "test.copy.file") >>>print("test.copy.file" in os.listdir(os.curdir)) True >>>shutil.copytree("test_dir/", "test_dir_copy/") >>>shutil.rmtree("test_dir_copy")
补充1:os.getcwd()与os.curdir都是用于获取当前执行python文件的文件夹,不过os.curdir时会返回‘.’(当前工作目录的字符串名称),后者返回的是当前执行python文件的文件夹,而不是python文件所在的文件夹。
>>> print(os.curdir) >>> print(os.getcwd()) . /home/yhm/OCR_DataSet/det
补充2:os.renames(old,new)、os.makedirs(name)进行重命名和创建文件夹时,若中间路径不存在,则创建文件夹;
补充3:os.listdir(path)但会给定目录下所有的文件夹和文件名,不包含'..'和子目录下的目录;
gzip zipfile tarfile模块处理压缩文件
在一般情况下,我们常使用Linux命令来解压缩文件,常见的文件压缩格式如下所示:
- zip,公开的一种压缩算法,但压缩比不高
- tar,本身只是打包工具,但可以在打包之后调用压缩算法进行压缩,这就是我们常见的tar.gz格式,常在linux内使用
- gz,是GNU组织开发的一个开源压缩程序
gzip模块可以解析 .gz 格式的文件,其压缩方式由zlib模块提供,gzip.open可以以二进制或文本方式打开gzip格式的压缩文件,返回一个file object,并将二进制字符串写入;
import gzip import shutil content = b"Lots of content here" with gzip.open('file.txt.gz', 'wb') as f: f.write(content) with gzip.open('file.txt.gz', 'rb') as f: file_content = f.read() with open('file.txt', 'rb') as f_in: with gzip.open('file.txt.gz', 'wb') as f_out: shutil.copyfileobj(f_in, f_out)
zipfile模块可以解析zip格式的文件,下面以一个综合的需求为例 整合上述内容;
# 复制file.txt文件 for i in range(10): shutil.copy("file.txt", "file"+str(i)+".txt") f = zipfile.ZipFile('files.zip', 'w') for name in glob.glob("*[0-9].txt"): f.write(name) os.remove(name) print(f.namelist()) f.close()
tarfile模块支持格式文件的读写,如下进行读入
f = tarfile.open("file.txt.tar", "w") f.add("file.txt") f.close()
logging模块记录日志
logging模块默认定义了以下几个日志等级,级别排序为 Critical > error > warning > info > debug, 只有warning及以上的记录会在命令行显示
- logging.critical(msg):
- logging.error(msg):
- logging.warning(msg):应用程序正常运行但发生不期望的事情时的信息
- logging.info(msg):只记录关键节点信息
- logging.debug(msg):包含最详细的日志信息
一个时间通常包括如下内容:事件发生时间、事件发生位置、事件的严重程度、事件内容,而在logging模块中通过logging.basicConfig(filename='my.log' , format=‘%(asctime)s : %(levelname)s’)函数对日志系统做一些基本配置,format参数下定义了下述属性名:
- %(asctime)s 日志事件发生的时间--人类可读时间,如:2003-07-08 16:49:45,896
- %(levelname)s 该日志记录的文字形式的日志级别('DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL')
- %(message)s 日志记录的文本内容,通过 msg % args计算得到的
- %(filename)s pathname的文件名部分,包含文件后缀
- %(process)d 进程ID
import logging logging.basicConfig(filename='my.log' , format='%(asctime)s : %(levelname)s: %(message)s') logging.critical('This is critical message') logging.error('This is error message') logging.warning('This is warning message') # 不会显示 logging.info('This is info message') logging.debug('This is debug message')
具体内容如链接所示:https://www.cnblogs.com/yyds/p/6901864.html
断言和异常
检查先验条件用断言,检查后验条件用异常;如在读取本地文件时,先判断filepath是否是str类型的,这时就是用assert来判断;而当在文件读取被执行后判断用户权限,则用异常来处理:
def read_file(file_path):
assert isinstance(file_path, str)
if not check_exist(file_path):
raise FileNotFoundError()
if not has_privilege(file_path):
raise PermissionError()
相比于assert语句只能抛出AssertionError,使用异常可以抛出更细致的错误,方便上层代码针对不同错误执行不同的逻辑。
pprint更美观的打印
import pprint
data = ("Hello", [1,2,3,4], (123,4,56))
pprint.pprint(data)
Immutable data
不可变数据类型:integer、float、long、complex、string、tuple(tuple只有不可变方法如用count计算元素数 用index获得元素位置)
String类型的替换:string.replace(' world', ' python'),或者使用 bytearray代替字符串;
>>> s= 'hello world' >>> s= s.replace('world', 'python') >>> b = bytearray(s, 'utf-8') >>> print(b[:-1:2]) bytearray(b'hlopto')
List Tuple Dictionary Set 和 collections模块
List 使用[]表示,元素可重复,元素类型可不同,list.append在列表末尾追加任意类型的元素,list.insert(3,'d')在索引位置插入元素,list.extend([2,3])来连接list,list.index()可以进行搜索,参数可以是坐标或者元素值;
Tuple 使用()表示,不可变类型,不能修改,元组的生成速度比列表快很多,遍历速度差不多,内置enumerate函数;
Dictionart 使用{ : , : }表示,可是使用多种数据类型混用
Set 必须使用set([1,1,0])创建,无序不重复元素集,不支持索引、分片等操作,
Lamada匿名函数
lambda函数也叫匿名函数,它允许快速定义单行函数,类似于C语言的宏,其语法规则如下:
lambda [arg1, arg2,...] : expression(只能有一个表达式) # Example: 删除字符串的指定开头 f = lambda x: x.split(prefix, 1)[-1] if x.startswith(prefix) else x
lambda表达式会返回一个函数对象,这个对象不会赋给一个标识符,但它可以直接作为list和dict的成员。
删除所有python进程
ps -ef | grep python | cut -c 9-15| xargs kill -s 9
vim中查找
在normal模式下按下/即可进入查找模式,输入要查找的字符串并按下回车。 Vim会跳转到第一个匹配。按下n查找下一个,按下N查找上一个。
Vim查找支持正则表达式,例如/vim$匹配行尾的"vim"。 需要查找特殊字符需要转义,例如/vim$匹配"vim$"。
切换CUDA版本
export PATH=/home/yhm/cuda/cuda100/bin:${PATH} export LD_LIBRARY_PATH=/home/yhm/cuda/cuda100/lib64:$LD_LIBRARY_PATH export CUDA_HOME=/home/yhm/cuda/cuda100/
nvidia-smi
watch -n 0.1 -d nvidia-smi
gpu_tensorflow_data_dump
scp -P 6448 dump_gpu_mask.zip root@183.129.171.130:/home/train_use/hagongda/gpu_data
timestamp=$[$(date +%s%N)/1000] ; cat tensor_name | awk '{print "pt",$4,$4}' | awk '{gsub("/", "_", $3);gsub(":", ".", $3);print($1,$2,"-n 0 -w ./dump_result_1215/"$3".""'$timestamp'"".npy")}' > tensor_name_cmd.txt