请详细介绍下TCP的三次握手机制,为什么要三次握手?
为什么要有握手?
为了的是可靠:同步序列号
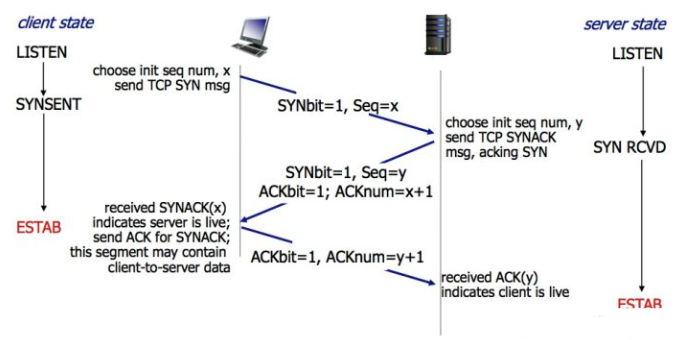
为什么是三次?
假如在只有两次"握手"的情形下,
假设Client想跟Server建立连接,但是却因为中途连接请求的数据报丢失了,故Client端不得不重新发送一遍;
这个时候Server端仅收到一个连接请求,因此可以正常的建立连接,但是,有时候Client端重新发送请求不是因为数据报丢失了,而是有可能数据传输过程因为网络并发量很大在某结点被阻塞了,这种情形下Server端将先后收到2次请求,并持续等待两个Client请求向他发送数据...问题就在这里,Cient端实际上只有一次请求,而Server端却有2个响应,极端的情况可能由于Client端多次重新发送请求数据而导致Server端最后建立了N多个响应在等待,因而造成极大的资源浪费!所以,"三次握手"很有必要!
假如四次的情况下,
想一下,假如现在你是客户端你想断开跟Server的所有连接该怎么做?
第一步,你自己先停止向Server端发送数据,并等待Server的回复。
但事情还没有完,虽然你自身不往Server发送数据了,但是因为你们之前已经建立好平等的连接了,所以此时他也有主动权向你发送数据;
这里就有一个半打开的状态,他可以持续发送消息。
只要故Server端还得终止主动向你发送数据,并等待你的确认。

简单介绍下HTTP协议中缓存的处理流程?
缓存的应用流程是什么?
请求处理过程:
当一个用户发起一个静态资源请求的时候,浏览器会通过以下几步来获取资源
1.本地缓存阶段:先在本地查找该资源,如果有发现该资源,而且该资源还没有过期,就使用这一个资源,完全不会发送http请求到服务器
2.协商缓存阶段:如果在本地缓存找到对应的资源,但是不知道该资源是否过期或者已经过期, 则发一个http请求到服务器,然后服务器判断这个请求,如果请求的资源在服务器上没有改动过,则返回304, 让浏览器使用本地找到的那个资源
3.缓存失败阶段:当服务器发现请求的资源已经修改过,或者这是一个新的请求(在本来没有找到资源),服务器则返回该资源的数据,并且返回200, 当然这个是指找到资源的情况下,如果服务器上没有这个资源,则返回404
与缓存相关的HTTP头部有哪些?
cache-control:
cache-control是http协议中常用的头部之一,顾名思义, 他是负责控制页面的缓存机制,如果该头部指示缓存, 缓存的内容也会存在本地, 操作流程和expire相似,但也有不同的地方, cache-control有更多的选项, 而且也有更多的处理方式.
该头部有过个值,下面我们来看下各个值的作用
1.Public
指示响应可被任何缓存区缓存。
2.Private
指示对于单个用户的整个或部分响应消息,不能被共享缓存处理。这允许服务器仅仅描述当用户的部分响应消息,此响应消息对于其他用户的请求无效。
3.no-cache
指示请求或响应消息不能缓存
4.no-store
用于防止重要的信息被无意的发布。在请求消息中发送将使得请求和响应消息都不使用缓存
5.max-age
指示客户机可以接收生存期不大于指定时间(以秒为单位)的响应。
6.no-transform
不允许转换存储系统
在地址栏键入URL后,网络世界发生么什么?
先查IP地址
查询ip地址
①浏览器解析出url中的域名。
②查询浏览器的DNS缓存。
③浏览器中没有DNS缓存,则查找本地客户端hosts文件有无对应的ip地址。
④hosts中无,则查找本地DNS服务器(运营商提供的DNS服务器)有无对应的DNS缓存。
⑤若本地DNS没有DNS缓存,则向根服务器查询,进行递归查找。
⑥递归查找从顶级域名开始(如.com),一步步缩小范围,最终客户端取得ip地址
tcp连接与http连接
①http协议建立在tcp协议之上,http请求前,需先进行tcp连接,形成客户端到服务器的稳定的通道。俗称TCP的三次握手。
②tcp连接完成后,http请求开始,请求有多种方式,常见的有get,post等。
③http请求包含请求头,也可能包含请求体两部分,请求头中包含我们希望对请求文件的操作的信息,请求体中包含传递给后台的参数。
④服务器收到http请求后,后台开始工作,如负载平衡,跨域等,这里就是后端的工作了。
⑤文件处理完毕,生成响应数据包,响应也包含两部分,响应头和相应体,响应体就是我们所请求的文件。
⑥经过网络传输,文件被下载到本地客户端,客户端开始加载。
html渲染
①客户端浏览器加载了html文件后,由上到下解析html为DOM树(DOM Tree)。
②遇到css文件,css中的url发起http请求。
③这是第二次http请求,由于http1.1协议增加了Connection: keep-alive声明,故tcp连接不会关闭,可以复用。
④http连接是无状态连接,客户端与服务器端需要重新发起请求--响应。
在请求css的过程中,解析器继续解析html,然后到了script标签。
⑤由于script可能会改变DOM结构,故解析器停止生成DOM树,解析器被js阻塞,等待js文件发起http请求,然后加载。这是第三次http请求。js执行完成后解析器继续解析。
⑥由于css文件可能会影响js文件的执行结果,因此需等css文件加载完成后再执行。
⑦浏览器收到css文件后,开始解析css文件为CSSOM树(CSS Rule Tree)。
⑧CSSOM树生成后,DOM Tree与CSS Rule Tree结合生成渲染树(Render Tree)。
⑨Render Tree会被css文件阻塞,渲染树生成后,先布局,绘制渲染树中节点的属性(位置,宽度,大小等),然后渲染,页面就会呈现信息。
⑩继续边解析边渲染,遇到了另一个js文件,js文件执行后改变了DOM树,渲染树从被改变的dom开始再次渲染。
⑪继续向下渲染,碰到一个img标签,浏览器发起http请求,不会等待img加载完成,继续向下渲染,之后再重新渲染此部分。
⑫DOM树遇到html结束标签,停止解析,进而渲染结束。
使用HTTP长连接有哪些优点?
实际说的TCP协议,
减少握手次数
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
减少慢启动的影响
CLOSE_WAIT状态产生的原因?
如果我们的服务器程序处于CLOSE_WAIT状态的话,说明套接字是被动关闭的!
介绍下多播是怎样实现的?
tcp 单播
udp 广播 多播
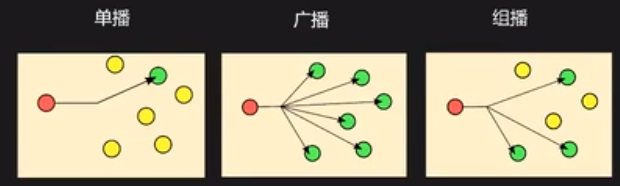
单播,转发一百次 都是用一个主机进行的复制100次
但是,多播一般是由网络设备交换机和路由器来做这个事情,可以提升发送端的性能
服务器的最大并发连接数是多少?
首先,问题中描述的65535个连接指的是客户端连接数的限制,而你作为服务器,别人来连你,理论上是没有限制的。注意,仅仅理论上。
65535是怎么来的?
是TCP协议规定的端口字段的最大范围,2个字节,16比特,每一比特有0和2种状态,按照排列组合,2的16次方,一共就是65536,端口0预留不用,就是65535。

TCP和UDP协议该如何选择?
TCP 与 UDP 的区别:TCP是面向连接的,可靠的字节流服务;UDP是面向无连接的,不可靠的数据报服务。

TLS/SSL协议是如何保障信息安全的?
加密分为“对称加密”和“非对称加密”两种:
对称加密:所谓的“对称加密”,意思就是说:“加密”和“解密”使用相同的密钥。
非对称加密::所谓的“非对称加密”,意思就是说:“加密”和“解密”使用不同的密钥。
HTTP2协议有哪些优点?
http1 的head太长了浪费带宽
多路复用
单一 TCP 连接的问题在于,一次只能发出一个请求,所以客户端必须等到收到响应后才能发出另一个请求。这就是 “线头阻塞” 问题。正如之前讨论的,典型的变通方案是打开多个连接;每个请求一个连接。但是,如果可以将消息分解为更小的独立部分并通过连接发送,此问题就会迎刃而解。
这正是 HTTP/2 希望达到的目标。将消息分解为帧,为每帧分配一个流标识符,然后在一个 TCP 连接上独立发送它们。此技术实现了完全双向的请求和响应消息复用。

图解显示在一个连接上快速传输了 3 个流。服务器发送两个响应,客户端发送一个请求。
在流 1 中,服务器为一个响应发送 HEADERS 帧;在流 2 中,它为另一个响应发送 HEADERS 帧,随后为两个响应发送 DATA 帧。两个响应按如图所示的方式交织。在服务器发送响应的过程中,客户端发送一条新消息的 HEADERS 和 DATA 帧作为请求。这些帧也与响应帧交织在一起,如下图所示。
图 HTTP/2 将请求/响应帧交织在一起

消息推送
可以考虑一个包含图像和其他依赖项(比如 CSS 和 JavaScript 文件)的网页。客户端发出一个针对该网页的请求。服务器然后分析所请求的页面,确定呈现它所需的资源,并主动将这些资源发送到客户端的缓存。在执行所有这些操作的同时,服务器仍在处理原始网页请求。客户端收到原始网页请求的响应时,它需要的资源已经位于缓存中。