原文章:复制and粘贴?Python脚本1分钟解决了我1小时的事!
https://mp.weixin.qq.com/s/NeawdsRjws9vzsYfwvUIjg
需求:将word格式json内容的问题和答案整理成整段,人类可读模式

看到上面的内容,手工操作是不是很麻烦。
别忘了有Python啥都不是事。下面是原作者的代码
from docx import Document import re import pandas as pd import json # 1.读取word文档,获取word文档里面的内容 x = "" doc = Document(r"G:1Pycharm_Project3572(1).docx") for paragraph in doc.paragraphs: text = paragraph.text # 读取word里面的内容有一个特点:每一页会返回一个字符串,共3页,一共返回了3个单独的字符串。 # 但是这是一个完整的json字符串,我们不能将他分开呀。因此,使用字符串拼接,将其合并起来。 x += text # 2.使用json.loads()将json字符串 转换为 字典格式的数据。 r = json.loads(x) # 3.对于字典,我们可以利用键,获取里面的值。 x = [] z = [] for i in r["data"]["ques"]: x.append(i["content"]) y = "" for j in i["options"]: y += j["answer"] + " " + j["option"] y += ";" z.append(y) # 4.将获取到的数据,保存成一个DataFrame格式的数据,并导出为excel表格。 data = {"content":x,"options":z} df = pd.DataFrame(data) display(df) df.to_excel("text.xlsx")
效果如下
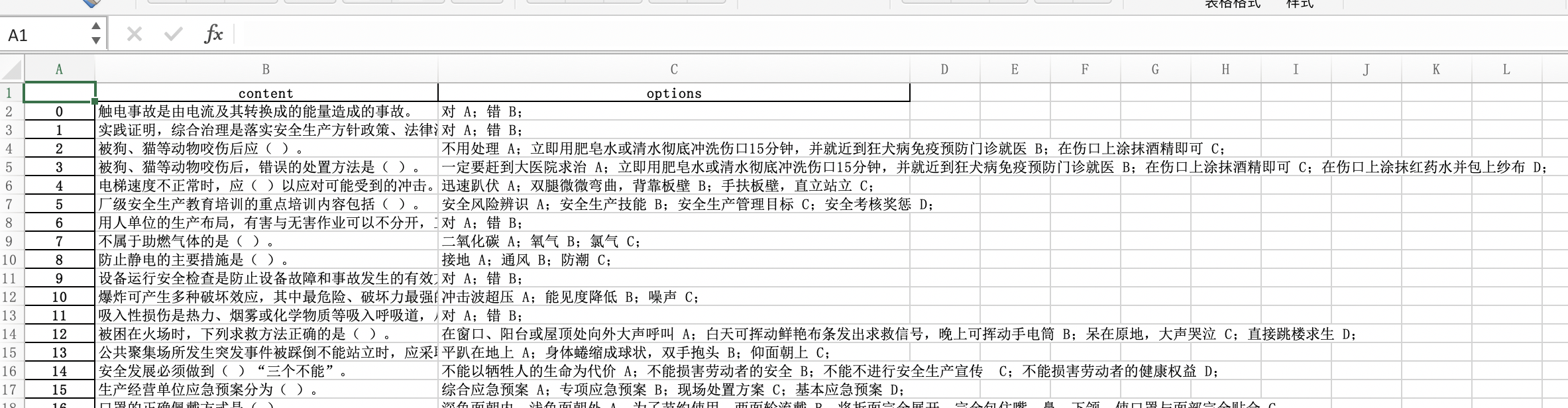
感谢群主提供原文件和思路,升级优化才得以实现。
前面和原创一致,后面数据整理略微差异。
安装库文件
# 关于from docx import Document报错问题,docx库比较老,安装python-docx就可以解决问题。 !pip install python-docx
解析文本
from docx import Document import re import pandas as pd import json # 1.读取word文档,获取word文档里面的内容 x = "" doc = Document("jsonfile.docx") for paragraph in doc.paragraphs: text = paragraph.text # 读取word里面的内容有一个特点:每一页会返回一个字符串,共3页,一共返回了3个单独的字符串。 # 但是这是一个完整的json字符串,我们不能将他分开呀。因此,使用字符串拼接,将其合并起来。 x += text # 2.使用json.loads()将json字符串 转换为 字典格式的数据。 r = json.loads(x) r
输出内容

解析处理,调整格式
# 3.对于字典,利用键获取里面的值。 queslst=[] optlst=[] n=1 for i in r['data']['ques']: question=str(n)+'、'+i['content'].rstrip() n+=1 ops=[] for option in i['options']: j = option["option"]+"、"+ option["answer"].rstrip() ops.append(j) ops=' '.join(ops) queslst.append(question) optlst.append(ops)
写入excel
# 4.将获取到的数据,保存成一个DataFrame格式的数据,并导出为excel表格。 data = {"question":queslst,"options":optlst} df = pd.DataFrame(data) display(df) df.to_excel("output2.xlsx",index=None)
输出格式

excel内容

新增点,存为word格式,需要重新排版
效果预览
# 5、写入docx from docx.enum.text import WD_ALIGN_PARAGRAPH from docx.oxml.ns import qn from time import strftime, localtime timestr=strftime('%Y-%m-%d %H:%M:%S',localtime()) doc1 = Document() #生成一个空的docx对象 head=doc1.add_heading('安全测试题', level=1) # 添加标题 head.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中 p1=doc1.add_paragraph('edit by:HuaBro update time: {}'.format(timestr)) # 添加段落 p1.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中 for i,j in zip(queslst,optlst): doc1.add_paragraph(i) doc1.add_paragraph(j) doc1.styles['Normal'].font.name = '宋体' doc1.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体') # 字体 doc1.styles['Normal'].font.name = 'Times New Roman' # 数字字体 doc1.save('output1.docx')
输出word内容

学会了没,是不是很简单。