SparkRDD实现自定义排序实现Order接口,
原始方法:元组输出
部分代码如下:
方法一:自定义一个类, 实现Ordered自定义的排序
代码如下:
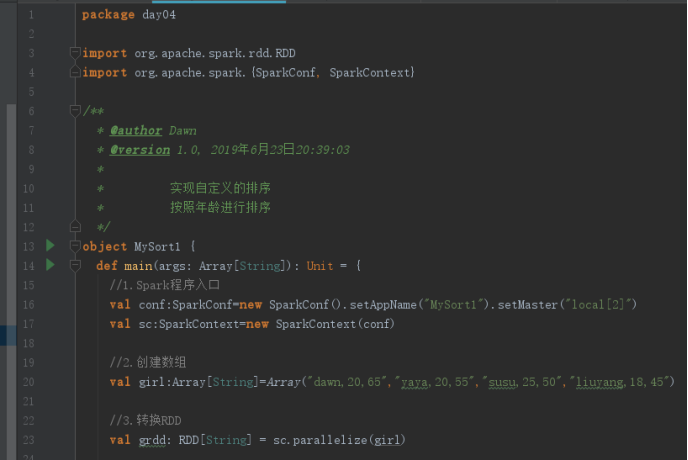
package day04
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Dawn
* @version 1.0, 2019年6月23日20:39:03
*
* 实现自定义的排序
* 按照年龄进行排序
*/
object MySort1 {
def main(args: Array[String]): Unit = {
//1.Spark程序入口
val conf:SparkConf=new SparkConf().setAppName("MySort1").setMaster("local[2]")
val sc:SparkContext=new SparkContext(conf)
//2.创建数组
val girl:Array[String]=Array("dawn,20,65","yaya,20,55","susu,25,50","liuyang,18,45")
//3.转换RDD
val grdd: RDD[String] = sc.parallelize(girl)
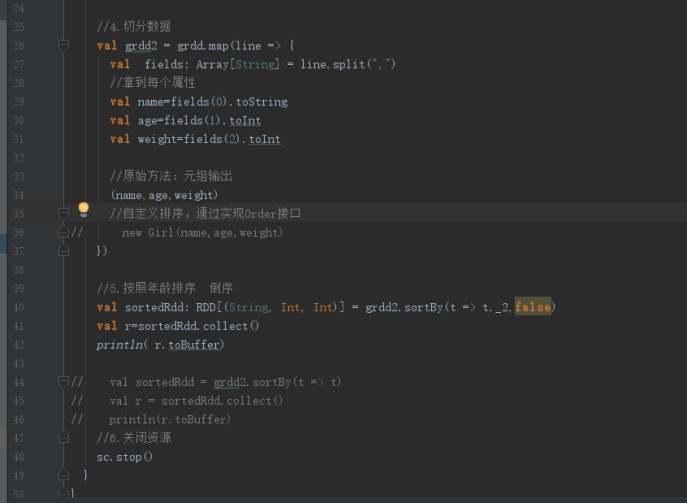
//4.切分数据
val grdd2 = grdd.map(line => {
val fields: Array[String] = line.split(",")
//拿到每个属性
val name=fields(0).toString
val age=fields(1).toInt
val weight=fields(2).toInt
//原始方法:元组输出
// (name,age,weight)
//自定义排序,通过实现Order接口
new Girl(name,age,weight)
})
//5.按照年龄排序 倒序
// val sortedRdd: RDD[(String, Int, Int)] = grdd2.sortBy(t => t._2,false)
// val r=sortedRdd.collect()
// println( r.toBuffer)
val sortedRdd = grdd2.sortBy(t => t)
val r = sortedRdd.collect()
println(r.toBuffer)
//6.关闭资源
sc.stop()
}
}
//自定义类 scala Ordered
class Girl(val name:String,val age:Int,val weight:Int)extends Ordered[Girl] with Serializable {
override def compare(that: Girl): Int = {
//如果年龄相同 体重重的往前排
if (this.age==that.age){
//如果正数 正序 负数 倒序
-(this.weight-that.weight)
}else{
//年龄小的往前排
this.age-that.age
}
}
override def toString: String = s"名字:$name,年龄:$age,体重:$weight"
}
方法二:模式匹配方式进行排序
代码如下:
package day04
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Dawn
* @version 1.0, 2019年6月23日21:03:30
* 模式匹配方式进行排序
*/
object MySort2 {
def main(args: Array[String]): Unit = {
//1.spark程序入口
val conf:SparkConf = new SparkConf().setAppName("MySort2").setMaster("local[2]")
val sc:SparkContext=new SparkContext(conf)
//2.创建数组
val girl:Array[String]=Array("dawn,20,65","yaya,20,55","susu,25,50","liuyang,18,45")
//3.装换成RDD
val grdd=sc.parallelize(girl)
//4.切分数据
val grdd1 = grdd.map(line => {
val fields: Array[String] = line.split(",")
val name:String=fields(0).toString
val age:Int=fields(1).toInt
val weight:Int=fields(2).toInt
//元组输出
(name,age,weight)
})
//5.模式匹配方式进行排序
val sortedRdd=grdd1.sortBy(s => Girl1(s._1,s._2,s._3))
val r = sortedRdd.collect()
println(r.toBuffer)
sc.stop()
}
}
case class Girl1(val name:String,val age:Int,val weight:Int) extends Ordered[Girl1]{
override def compare(that: Girl1) = {
//如果年龄相同 体重重的往前排
if (this.age==this.age){
-(this.weight-that.weight)
}else{
this.age-that.age
}
}
override def toString: String = s"名字:$name,年龄:$age,体重:$weight"
}
方法三:专门定义一个隐世类来排序
建议写成隐式类,应为可以将你需要的隐世装换全写在一个隐式类中,直接导入就行了!!
编写隐式类:
package day04
//定义一个专门处理隐式的类
object ImplicitRules{
//定义隐世规则
implicit object OrderingGirl extends Ordering[Girl2]{
override def compare(x: Girl2, y: Girl2): Int = {
if(x.age==y.age){
//体重重的往前排
-(x.weight-y.weight)
}else{
//年龄小的往前排
x.age-y.age
}
}
}
}
编写主程序:
package day04
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Hunter
* @version 1.0, 20:55 2019/1/16
* 专门定义一个隐世类来排序
* 建议写成隐式类,应为可以将你需要的隐世装换全写在一个隐式类中,直接导入就行了
*/
object MySort3 {
def main(args: Array[String]): Unit = {
//1.spark程序的入口
val conf:SparkConf=new SparkConf().setAppName("MySort3").setMaster("local[2]")
val sc:SparkContext=new SparkContext(conf)
//2.创建数组
val girl:Array[String]=Array("dawn,20,65","yaya,20,55","susu,25,50","liuyang,18,45")
//3.转换RDD
val grdd1=sc.parallelize(girl)
//4.切分数据
val grdd2 = grdd1.map(line => {
val fields = line.split(",")
val name:String=fields(0).toString
val age:Int=fields(1).toInt
val weight:Int=fields(2).toInt
//元祖输出
(name,age,weight)
})
import ImplicitRules.OrderingGirl
val sortedRdd=grdd2.sortBy(s => Girl2(s._1,s._2,s._3))
val r=sortedRdd.collect()
println(r.toBuffer)
}
}
case class Girl2(val name:String,val age:Int,val weight:Int)