案例一:计算网页访问量前三名
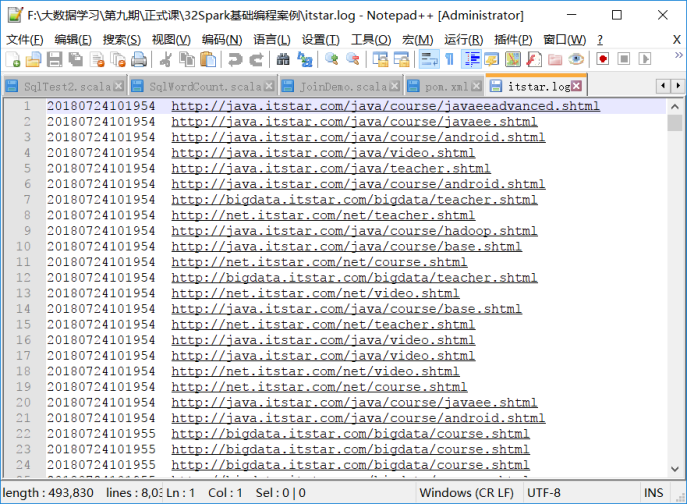
源数据大致预览:
编写Scala代码:
package day02
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author dawn
* @version 1.0, 2019年6月21日11:40:16
*
* 需求:计算网页访问量前三名
* 用户:喜欢视频 直播
* 帮助企业做经营和决策
*
* 看数据
*/
object UrlCount {
def main(args: Array[String]): Unit = {
//1.加载数据
val conf: SparkConf = new SparkConf().setAppName("UrlCount").setMaster("local[2]")
//Spark程序入口
val sc: SparkContext = new SparkContext(conf)
//加载数据
val rdd1: RDD[String] = sc.textFile("itstar.log")
//2.对数据进行计算
val rdd2:RDD[(String,Int)]=rdd1.map(line => {
val s = line.split(" ")
//标注出现1次
(s(1), 1)
})
//3.将相同的网址进行累加求和 网页,201
val rdd3:RDD[(String,Int)] = rdd2.reduceByKey(_+_)
//4.排序 取出前三
val rdd4:Array[(String,Int)] = rdd3.sortBy(_._2,false).take(3)
//5.遍历打印
rdd3.foreach(x => {
println("网址为:"+x._1+"访问量为:"+x._2)
})
//6.转换 toString toBuffer
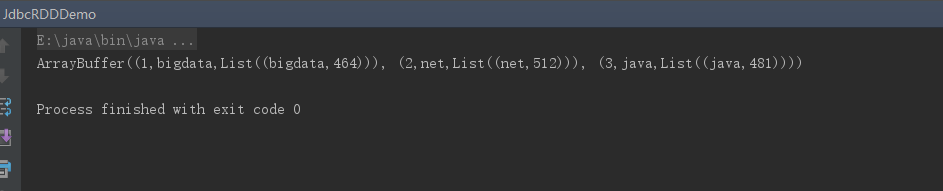
println(rdd4.toBuffer)
sc.stop()
}
}
运行结果:
案例二:求出每个学院 访问第一位的网址,分组
编写Scala代码:
package day02
import java.net.URL
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author dawn
* @version 1.0, 2019年6月21日12:25:44
* 需求:求出每个学院 访问第一位的网址,分组
* bigdata:video(直播)
* java:video
* python:teacher
*/
object UrlGoupCount {
def main(args: Array[String]): Unit = {
//1.创建SparkConText
val conf:SparkConf=new SparkConf().setAppName("UrlGoupCount").setMaster("local[2]")
val sc:SparkContext=new SparkContext(conf)
//2.加载数据
val rdd1:RDD[String]=sc.textFile("itstar.log")
//3.切分
val rdd2:RDD[(String,Int)] = rdd1.map(line =>{
val s=line.split(" ")
(s(1),1)
})
//4.求出总的访问量 网址,总的访问量
val rdd3:RDD[(String,Int)] = rdd2.reduceByKey((x,y) => x+y )
//5.取出学院
val rdd4:RDD[(String,String,Int)] = rdd3.map(x =>{
//拿到url
val url:String=x._1
//用java的方式拿到主机名
val host:String =new URL(url).getHost.split("[.]")(0)
//元组输出
(host,url,x._2)
})
//6.按照学院进行分组 groupBy返回的结果是:RDD[(k,iterator[(String,Stirng,Int)])]
val rdd5:RDD[(String,List[(String,String,Int)])]=rdd4.groupBy(_._1).mapValues(it => {
//倒序,记得要将iterator[(String,Stirng,Int)]转成List再排序
it.toList.sortBy(_._3).reverse.take(1)
})
//7.遍历打印
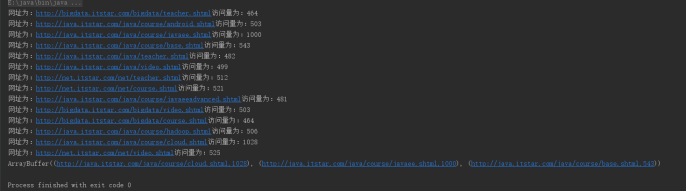
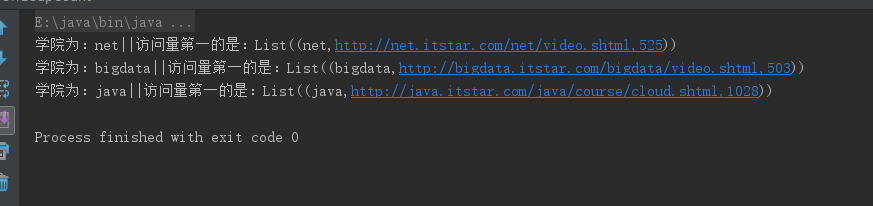
rdd5.foreach(x =>{
println("学院为:"+x._1+"||"+"访问量第一的是:"+x._2)
})
sc.stop()
}
}
运行结果:
案例三:加入自定义分区 按照学院分区,相同的学院分为一个结果文件
编写Scala代码:
package day02
import java.net.URL
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import scala.collection.mutable
/**
* @author Dawn
* @version 1.0, 2019年6月21日12:25:49
* 需求:加入自定义分区
* 按照学院分区,相同的学院分为一个结果文件
*/
object UrlParCount {
def main(args: Array[String]): Unit = {
//1.创建SparkContext对象
val conf:SparkConf=new SparkConf().setAppName("").setMaster("local[2]")
val sc:SparkContext=new SparkContext(conf)
//2.加载数据
val rdd1:RDD[(String,Int)] = sc.textFile("itstar.log").map(line => {
val s=line.split(" ")
(s(1),1)
})
//3.聚合
val rdd2:RDD[(String,Int)] = rdd1.reduceByKey(_+_)
//4.自定义格式
val rdd3:RDD[(String,(String,Int))]=rdd2.map(t =>{
val url=t._1
val host=new URL(url).getHost
val XHost=host.split("[.]")(0)
//元组输出
(XHost,(url,t._2))
})
//5.加入自定义分区
val xueyuan:Array[String] = rdd3.map(_._1).distinct().collect()//去重只剩下net bigdata java
val xueYuanPartitioner:XueYuanParititioner=new XueYuanParititioner(xueyuan)
//6.加入分区规则
val rdd4:RDD[(String,(String,Int))]=rdd3.partitionBy(xueYuanPartitioner).mapPartitions(it =>{
//将rdd3的结果进行自定义分区,再遍历分区中的元素,并将元素进行toList,再按照访问量排序,
//在倒叙,再取出第一个元素,返回类型是(String,(String,Int)),不是(String,List[(String,String,Int)])
it.toList.sortBy(_._2._2).reverse.take(1).iterator
})
//7.把结果存储
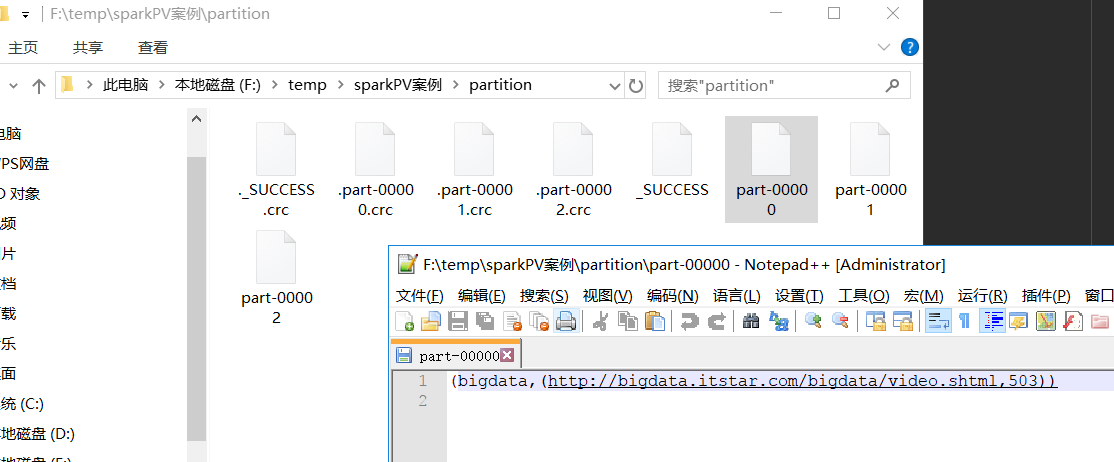
rdd4.saveAsTextFile("f:/temp/sparkPV案例/partition")
sc.stop()
}
}
class XueYuanParititioner(xy:Array[String]) extends Partitioner{
//自定义规则 学院 分区号
val rules: mutable.HashMap[String,Int]=new mutable.HashMap[String,Int]()
var number=0
//遍历学院
for(i <- xy){
//学院与分区号对应,rules是一个HashMap,加一个元素
rules += (i -> number)
//分区号递增
number += 1
}
//总的分区个数=学院中的长度为分区个数
override def numPartitions = xy.length
//拿到分区
override def getPartition(key: Any):Int = {
rules.getOrElse(key.toString,0)
}
}
运行结果:
案例四:Spark访问数据库
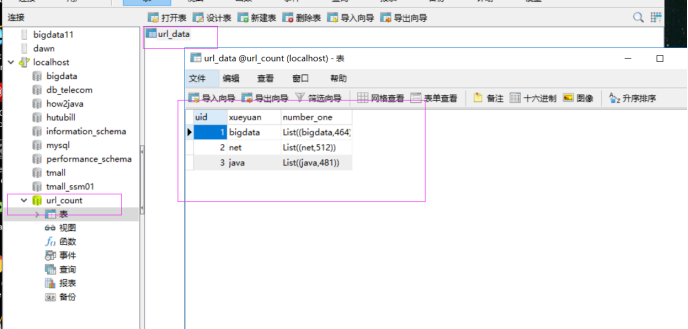
把分组排名第一的学院结果存储在mysql中,
编写代码如下:
package day03
import java.net.URL
import java.sql.{Connection, DriverManager}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Hunter
* @version 1.0, 2019年6月21日21:10:30
* 把最终的结果存储在mysql中
*/
object UrlGroupCount1 {
def main(args: Array[String]): Unit = {
val conf:SparkConf=new SparkConf().setAppName("UrlGroupCount1").setMaster("local[2]")
val sc:SparkContext=new SparkContext(conf)
//加载数据
val rdd1:RDD[String] =sc.textFile("itstar.log")
val rdd2:RDD[(String,Int)]=rdd1.map(line =>{
val s:Array[String]=line.split(" ")
(s(1),1)
})
//累加求和
val rdd3:RDD[(String,Int)]=rdd2.reduceByKey(_+_)
//取出分组的学院
val rdd4:RDD[(String,Int)]=rdd3.map(x =>{
val url=x._1
val host=new URL(url).getHost.split("[.]")(0)
//元组输出
(host,x._2)
})
//6.根据学院分组
val rdd5:RDD[(String,List[(String,Int)])]=rdd4.groupBy(_._1).mapValues(it => {
//根据访问量排序 倒序
it.toList.sortBy(_._2).take(1)
})
//7.把计算结果保存到mysql中
rdd5.foreach(x => {
//把数据写到mysql
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/url_count?charatorEncoding=utf-8","root","199902")
//把spark结果插入到mysql中
val sql="INSERT INTO url_data (xueyuan,number_one) VALUES (?,?)"
//执行Sql
val statement=conn.prepareStatement(sql)
statement.setString(1,x._1)
statement.setString(2,x._2.toString())
statement.executeUpdate()
statement.close()
conn.close()
})
//8.关闭资源 应用停掉
sc.stop()
}
}
运行结果:
案例五:Spark提供jdbcRDD,操作MySQL
编写代码如下:
package day03
import java.sql.DriverManager
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Dawn
* @version 1.0, 2019年6月22日11:25:30
* spark提供的连接mysql的方式
* jdbcRDD
*/
object JdbcRDDDemo {
def main(args: Array[String]): Unit = {
val conf:SparkConf=new SparkConf().setAppName("JdbcRDDDemo").setMaster("local[2]")
val sc:SparkContext=new SparkContext(conf)
//匿名函数
val connection=() =>{
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://localhost:3306/url_count?charatorEncoding=utf-8","root","199902")
}
//查询数据
val jdbcRdd:JdbcRDD[(Int,String,String)]=new JdbcRDD(
//指定sparkcontext
sc,
connection,
"SELECT * FROM url_data where uid >= ? AND uid <= ?",
//2个任务并行
1,4,2,
r =>{
val uid = r.getInt(1)
val xueyuan = r.getString(2)
val number_one = r.getString(3)
(uid, xueyuan, number_one)
}
)
val jrdd = jdbcRdd.collect()
println(jrdd.toBuffer)
sc.stop()
}
}
运行结果: