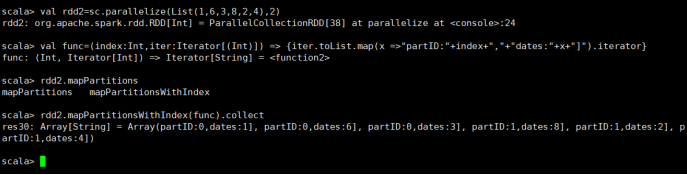
1)mapPartionWithIndex(func)
设置分区,并且查看每个分区中存放的元素
查看每个分区中元素
需要传递函数作为参数
val func = (index:Int,iter:Iterator[(Int)]) =>
{iter.toList.map(x => "partID:" + index + "," + "datas:" + x +
"]").iterator}
2)aggregate
聚合,先局部后全局
max 取最大值
min 取最小值
每个分区内先局部相加,再全局相加,
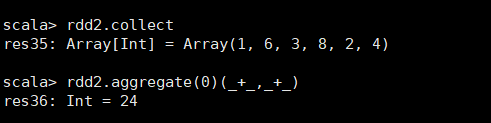
务必理解这些列子


这个案例充分体现了并行化的结果
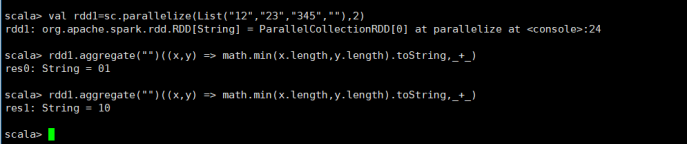
分析: math.min("".length, "12".length ) 的结果是:0 ,
math.min("0".length, "23".length ) 的结果是:1
math.min("".length, "345".length) 的结果是:0 ,
math.min("0".length, "".length) 的结果是:0
误区:不要以为初始值为"",然后进行简单的比较,比较出来的结果为:0,然后toStringj就是1,记得逐个比较

和上面分析一样的!!!
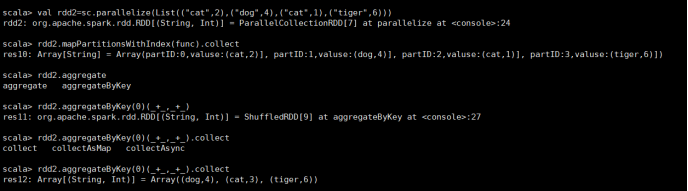
3)aggregateByKey
根据key聚合,先局部再全局
编写查看分区的func:
def func(index:Int,iter:Iterator[(String,Int)]):Iterator[String] = {iter.toList.map(x => "partID:"+index+","+"valuse:"+x+"]").iterator}
4)combineByKey
aggregateByKey和reduceByKey底层调用都是combineByKey
最底层的方法,先局部累加,再全局累加

5)coalesce
coalesce(4,true)
分区数4
是否shuffle
repartition的实现,已默认加了shuffle

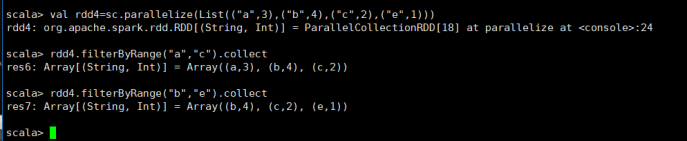
6)filterByRange
过滤出指定范围的元素
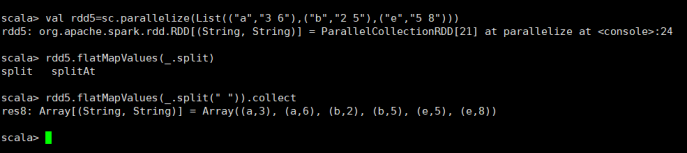
7)flatMapValues
切分出每个元素
8)foldByKey
需求:根据key来拼接字符串

9)foreach
遍历元素
10)keyBy
以什么为key
这里以元素的长度为key

keys values
拿到key 拿到value