一:分区
1:自定义一个Partition类(直接使用上次那个流量统计那个代码)
package it.dawn.YARNPra.flow流量汇总序列化.partition;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author Dawn
* @date 2019年5月3日22:03:08
* @version 1.0
* 自定义一个分区
*/
public class PhonenumPartitioner extends Partitioner<Text, FlowBean>{
//根据手机号前三位进行分区
@Override
public int getPartition(Text key, FlowBean value, int numpartitions) {
//1.获取手机号前三位
String phoneNum=key.toString().substring(0, 3);
//2:分区
int partitioner=4;
if("135".equals(phoneNum)) {
return 0;
}else if("137".equals(phoneNum)){
return 1;
}else if("138".equals(phoneNum)) {
return 2;
}else if("139".equals(phoneNum)) {
return 3;
}
return partitioner;
}
}
2:在Driver类中添加Partiton的分区个数
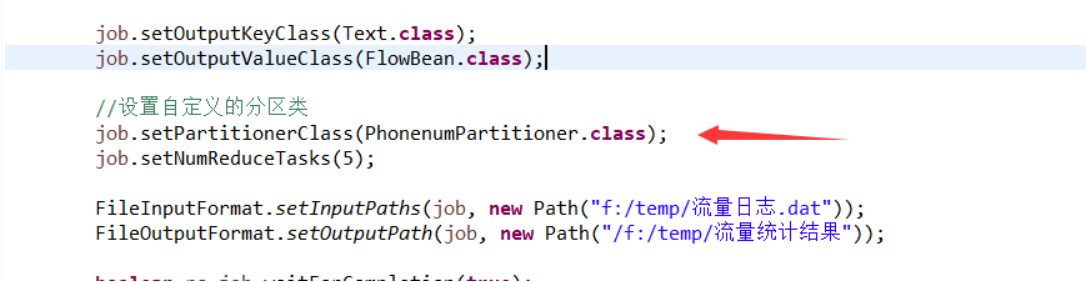
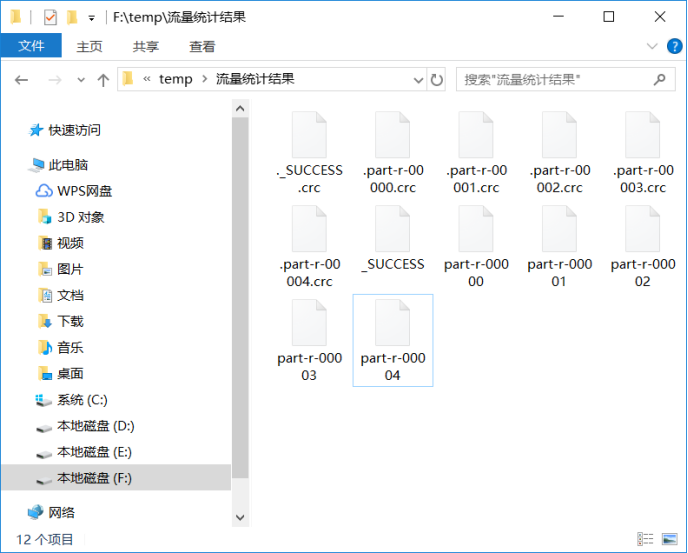
3:运行结果
一:合并(mapTask的合并)
原理图:
1:maptask并行度与决定机制
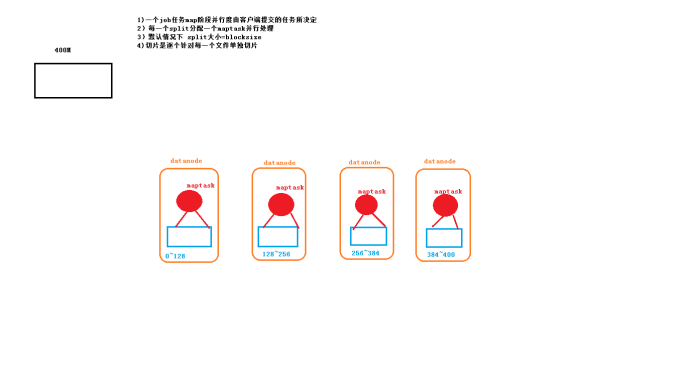
2 maptask工作机制
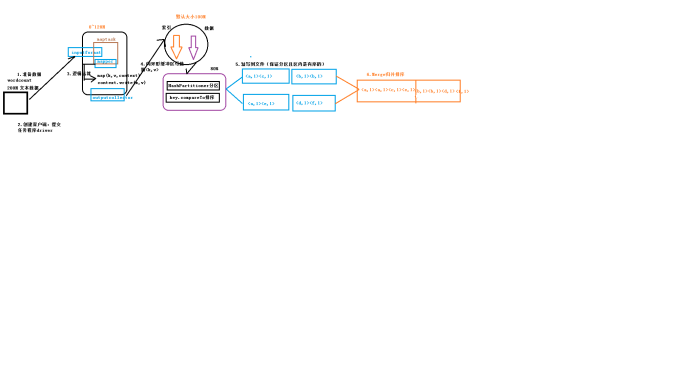
3:运用场景
1:多个小文件合并优化(减少mapTask任务)
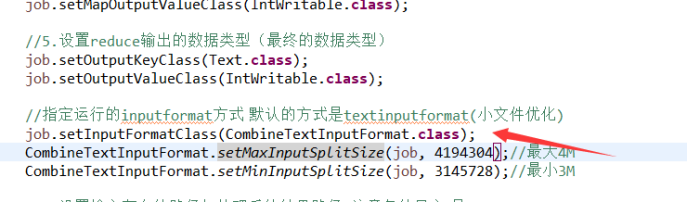
2:Combiner 合并(使用上回的wordcount程序)
父类Reducer
局部汇总 ,减少网络传输量 ,进而优化程序。
注意:求平均值?
3 5 7 2 6
mapper: (3 + 5 + 7)/3 = 5
(2 + 6)/2 = 4
reducer:(5+4)/2
前提: 只能应用在不影响最终业务逻辑的情况下
使用:只需添加一行代码即可
//添加combiner
job.setCombinerClass(WordCountReducer.class);