一:统计所给出文件中英文字母出现的频率(区分大小写),并且按着出现频率倒序输出
思路: 1、将文件内容存入StringBuffer中;
2、将读入的内容进行分割;
3、遍历数组,将其放入一个TreeMap <String,Integer>中;
4、对其计算出来的频率进行排序;
package file; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.math.BigInteger; import java.text.DecimalFormat; import java.util.ArrayList; import java.util.Comparator; import java.util.TreeMap; import java.util.TreeSet; public class zimupaixu { public static void main(String [] args) throws IOException { //读取文件 BufferedReader br=new BufferedReader(new FileReader("F:\\\\备用\\\\english.txt")); TreeMap<Character,Integer> tm=new TreeMap<>();//打开哈希表 int key; while((key=br.read())!=-1) { if((key>='A'&&key<='Z')||(key>'a'&&key<='z')) { tm.put((char)key,tm.containsKey((char)key)?tm.get((char)key)+1:1);//累计不同字母出现的次数 } } br.close(); int max=0; int sum=0; int t=0; for(Character k: tm.keySet()) { sum=sum+tm.get(k); } TreeSet<Character> ts=new TreeSet<>(new Comparator<Character>() { public int compare(Character a,Character b) { int num=tm.get(a)-tm.get(b); return num==0?1:(-num); } }); for(Character k: tm.keySet()) { ts.add(k); } DecimalFormat df = new DecimalFormat("0.00%"); for (Character c : ts) { float bai=(float)tm.get(c)/sum; System.out.println(c+" "+"出现的百分比"+" "+df.format(bai)); } //System.out.println(sum); }}
二、输出单个文件的前N个最常出现的英文单词
思路:1、从头到尾遍历文件,从文件中读取遍历到的每一个单词。
2、把遍历到的单词放到TreeHasp中,并统计这个单词出现的次数。
3、定义全局变量N控制输出多少个单词
4、循环对全部单词次数进行比较获取出现次数最多的那个,循环N次。
package file; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.util.*; public class danci { class Word//定义单词类 { String value;//具体的单词 int count;//出现的个数 Word next;//将单词链起来 public Word(String value,int geshu)//带参构造函数 { this.value=value; this.count=geshu; next=null; } public Word()//构造函数 { this.value=""; this.count=0; next=null; } } /* * 读取指定路径下的文件名和目录名 */ public void getFileList() throws IOException { BufferedReader br=new BufferedReader(new FileReader("F:\\备用\\english.txt")); TreeMap<Character,Integer> hm=new TreeMap<>(); int key; while((key=br.read())!=-1) { Word word=new Word(); //单词的链头 Word lian,xin; String str=""; char[] c=new char[1];//每次读取一个字母 int b=0; boolean exist=false;//判断单词是否存在于 word 链中 while((b=br.read(c))!=-1)//读取字母 { //分割 if(String.valueOf(c).equals("\r")||String.valueOf(c).equals("\n")||String.valueOf(c).equals(" ")||String.valueOf(c).equals(",")||String.valueOf(c).equals(".")||String.valueOf(c).equals("\"")||String.valueOf(c).equals("'")) { lian=word; while(lian!=null) { if(lian.value.equalsIgnoreCase(str))//累计不同单词的个数 { lian.count++;exist=true; break; } else { lian=lian.next; } } if(exist==false)//如果不存在,则在单词链中添加 { xin=new Word(str,1); xin.next=word.next; word.next=xin; str=""; } else { exist=false; str=""; } } else { str+=String.valueOf(c); } } System.out.print("前N个最长出现的单词的数量:"); Scanner scan=new Scanner(System.in); int N=scan.nextInt(); System.out.println(""); for(int i=1;i<=N;i++) {//根据输入的N输出相应的单词以及其个数 xin=new Word("",0); lian=word.next; while(lian!=null) { if(lian.count>xin.count) { xin=lian; } lian=lian.next; } System.out.println(+i+" :"+xin.value+" "+xin.count); lian=word; //删除单词链中单词个数最多的 while(lian.next!=null) { if(lian.next.value.equalsIgnoreCase(xin.value)) { lian.next=lian.next.next; break; } lian=lian.next; } } } } public static void main(String[] args) throws IOException { danci rf = new danci(); rf.getFileList(); }
代码截图:
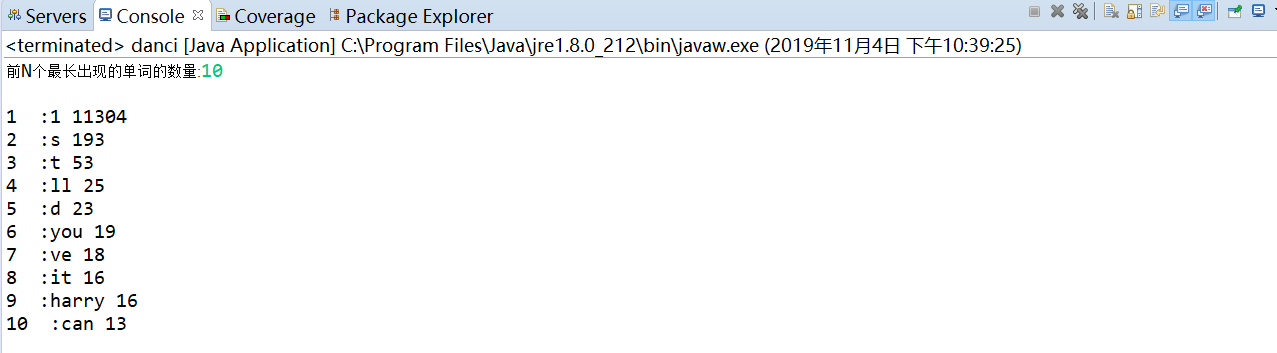
三:指定文件目录,但是会递归目录下的所有子目录,每个文件执行统计单词的数量以及百分比
package file; import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.text.DecimalFormat; import java.util.Comparator; import java.util.Scanner; import java.util.TreeMap; import java.util.TreeSet; public class dancichachong { //F:\\\\\\\\备用\\\\\\\\english.txt public static void main(String[] args) throws IOException { System.out.println("请输入所要遍历的文件的路径:"); Scanner sc=new Scanner(System.in); File file=getfile(); bianli(file); System.out.println("请选择要查询的文档"); String name=sc.next(); display(name); } public static void bianli(File file) { File [] yue=file.listFiles(); for(File fi:yue) { if(!fi.isDirectory()) { if(fi.getName().endsWith(".txt")) { System.out.println(fi.getPath()); } } else { bianli(fi); } } } public static void display(String path) throws IOException { Scanner sc=new Scanner (System.in); BufferedReader br=new BufferedReader(new FileReader(path)); int c; TreeMap<String,Integer> tm=new TreeMap<>(); String line; int kt=0; while((line=br.readLine())!=null) { String [] str=line.split("[^a-zA-Z]"); for(int i=0;i<str.length;i++) { if(!str[i].equals("")) { tm.put(str[i],tm.containsKey(str[i])?tm.get(str[i])+1:1);} } } br.close(); int max=0; int sum=0; int t=0; for(String k: tm.keySet()) { sum=sum+tm.get(k); if(max<=tm.get(k)) { max=tm.get(k); } } TreeSet<String> ts=new TreeSet<>(new Comparator<String>() { public int compare(String a,String b) { int num=tm.get(a)-tm.get(b); return num==0?1:(-num); } }); for(String k: tm.keySet()) { ts.add(k); } DecimalFormat df = new DecimalFormat("0.00%"); System.out.println("请输入要查询的个数"); int count=sc.nextInt(); int q=0,i=1; for (String s : ts) { if(q==count) { break; } else { q++; float bai=(float)tm.get(s)/sum; System.out.println(i+" "+s+" "+tm.get(s)+" "+df.format(bai)); } i++; } } public static File getfile() { Scanner sc=new Scanner(System.in); while(true) { String line=sc.nextLine(); File kk=new File(line); if(!kk.exists()) { System.out.println("输入的不是文件夹,请重新输入"); } else if(kk.isFile()) { System.out.println("输入的是文件路径,请重新输入"); } else { return kk; } } } }
代码测试截图:
