Overview:
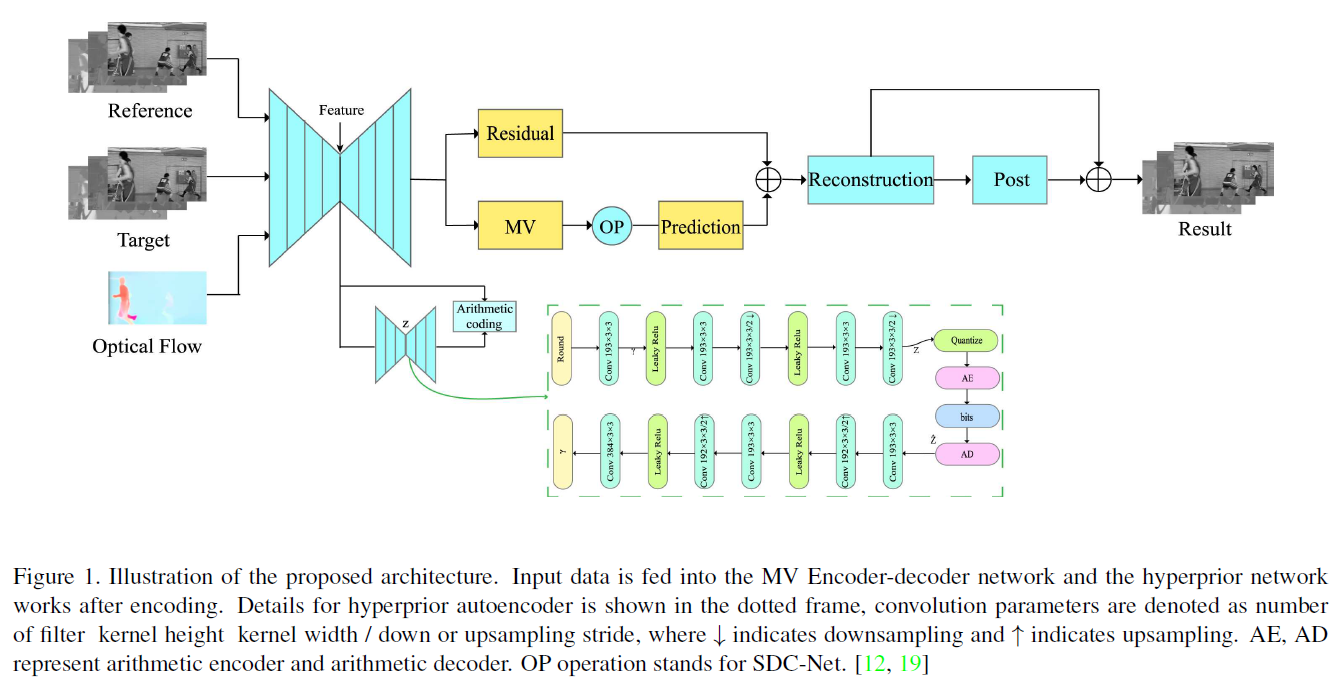
主要步骤:
- 数据预处理: Simply up-sampled the given pictures with format of YUV420 to YUV444 as reference frame and target frame. 用预训练好的PWC-Net来得到光流
- MV Encoder-decoder网络: 为了对运动信息进行编码,设计了一种自动编码方式的CNN,以达到更好的编码效果。在这一步中,经过一系列的卷积运算和非线性变换,将生成运动的表示。然后,对潜变量进行量化,并将其输入超先验自编码器,以获得先验概率(运动压缩?)后面再详细聊这个
- 运动估计: 设计OP运算为从前面一个网络计算出的MV来得到预测结果,用SDC-net来实现,是完全可微的,所以网络可以端到端的训练。后面会详细说
- 后处理: 把残差和预测加起来就得到重建结果,然后用了一个ResNet style network来优化得到最终输出 (Q: 还要优化?怎么优化?)
- 可变速率(Variable rate): 用速率控制模块Variable rate deep image compression with a conditional autoencoder,通过一组权值来使模型能够适应不同的压缩率,速率控制参数(Lagrange乘子)加进loss,作为端到端模型的conditional input
运动估计之空间位移卷积:
运动估计(应该是运动估计+运动补偿?)中的OP操作(通过前一个网络计算出的运动向量得到预测帧)用SDC-Net来实现的。不用向量变换来实现,因为SDC-net里说这样来表示运动不够充分,还会导致结果模糊。所以抄过来就完事儿了
(I_t) reference frame
(F_i) decoded optical flow
(mathcal{G}) is a fully convolutional network,输出像素级可分离卷积核(K_u,K_v)
空间位移卷积

运动压缩网络之速率估计模块:
用Laplacian分布和单位宽度的均匀分布的卷积来建模每个潜变量(hat{y}_i), 参数为(mu_i,sigma_i)
基于End-to-end optimized image compression with attention mechanism(CVPRW 2019)(他们自己的解答?), 超先验和(hat{y}_i)的因果上下文都用来预测Laplacian参数
速率估计模块是一个参数为(Theta_h)的超先验网络(H),预测的Laplacian参数是学到的参数(Theta_h)的函数
(mu_{i}, sigma=h_{d}left(hat{z} ; Theta_{h} ight))是超先验网络的输出
超先验网络:
把降采样特征(y)喂到超先验编码器中,得到(z=h_e(y))中标准差的分布,然后将(z)量化得到(hat{z}=Q(z)),超先验网络最后输出每个潜变量的Laplacian distribution的参数。而对于(hat{z})的分布,因为没有先验知识,所以用一个A non-parametric, fully factorized density model来建模,抄了Variational image compression with a scale hyperprior中的方法
向量(psi_i)表示每个单变量分布(P_{z_i|psi_i})的参数
压缩率包括两方面:
- rate (R_y) of compressed representation (hat{y})
- rate (R_z) of compressed side information (hat{z})
后处理:
在重构帧后接了这么个网络来进行图像增强
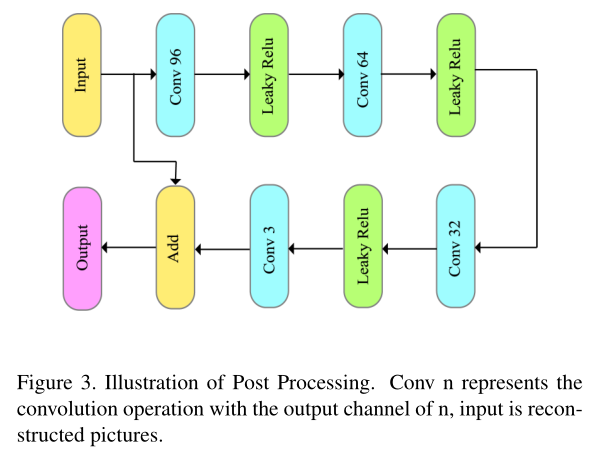
输入输出都是3通道,对应于YUV444的三个维度
速率控制优化:
用了End-to-end optimized image compression with attention mechanism(CVPRW 2019)中一样的速率控制策略
速率控制优化问题就是怎么把比特位分配给每一帧
(M)是向量集合,包含了帧集合的所有可能的quality configurations
(N)表示第几帧
(MS_j)是在configuration (j)下的MS-SSIM performance
(R_j)是在configuration (j)下的rates
说人话:所有帧的速率之和够用的情况下,使效果最好
用dp求解