11.Mapreduce实例——MapReduce自定义输出格式小
实验目的
1.了解Hadoop自带的几种输出格式
2.准确理解MapReduce自定义输出格式的设计原理
3.熟练掌握MapReduce自定义输出格式程序代码编写
4.培养自己编写MapReduce自定义输出格式程序代码解决问题的能力
实验原理
1.输出格式:提供给OutputCollector的键值对会被写到输出文件中,写入的方式由输出格式控制。OutputFormat的功能跟前面描述的InputFormat类很像,Hadoop提供的OutputFormat的实例会把文件写在本地磁盘或HDFS上。在不做设置的情况下,计算结果会以part-000*输出成多个文件,并且输出的文件数量和reduce数量一样,文件内容格式也不能随心所欲。每一个reducer会把结果输出写在公共文件夹中一个单独的文件内,这些文件的命名一般是part-nnnnn,nnnnn是关联到某个reduce任务的partition的id,输出文件夹通过FileOutputFormat.setOutputPath() 来设置。你可以通过具体MapReduce作业的JobConf对象的setOutputFormat()方法来设置具体用到的输出格式。下表给出了已提供的输出格式:
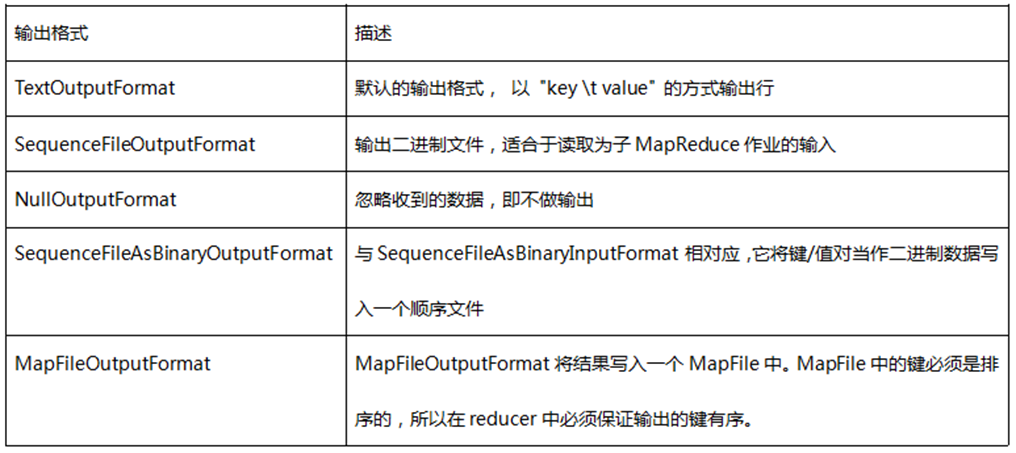
Hadoop提供了一些OutputFormat实例用于写入文件,基本的(默认的)实例是TextOutputFormat,它会以一行一个键值对的方式把数据写入一个文本文件里。这样后面的MapReduce任务就可以通过KeyValueInputFormat类简单的重新读取所需的输入数据了,而且也适合于人的阅读。还有一个更适合于在MapReduce作业间使用的中间格式,那就是SequenceFileOutputFormat,它可以快速的序列化任意的数据类型到文件中,而对应SequenceFileInputFormat则会把文件反序列化为相同的类型并提交为下一个Mapper的输入数据,方式和前一个Reducer的生成方式一样。NullOutputFormat不会生成输出文件并丢弃任何通过OutputCollector传递给它的键值对,如果你在要reduce()方法中显式的写你自己的输出文件并且不想Hadoop框架输出额外的空输出文件,那这个类是很有用的。
RecordWriter:这个跟InputFormat中通过RecordReader读取单个记录的实现很相似,OutputFormat类是RecordWriter对象的工厂方法,用来把单个的记录写到文件中,就像是OuputFormat直接写入的一样。
2.与IntputFormat相似, 当面对一些特殊情况时,如想要Reduce支持多个输出,这时Hadoop本身提供的TextOutputFormat、SequenceFileOutputFormat、NullOutputFormat等肯定是无法满足我们的需求,这时我们需要自定义输出数据格式。类似输入数据格式,自定义输出数据格式同样可以参考下面的步骤:
(1) 自定义一个继承OutputFormat的类,不过一般继承FileOutputFormat即可;
(2)实现其getRecordWriter方法,返回一个RecordWriter类型;
(3)自定义一个继承RecordWriter的类,定义其write方法,针对每个<key,value>写入文件数据;
实验环境
Linux Ubuntu 14.04
jdk-7u75-linux-x64
hadoop-2.6.0-cdh5.4.5
hadoop-2.6.0-eclipse-cdh5.4.5.jar
eclipse-java-juno-SR2-linux-gtk-x86_64
实验内容
当面对一些特殊的<key,value>键值对时,要求开发人员继承FileOutputFormat,用于实现一种新的输出格式。同时还需继承RecordWriter,用于实现新输出格式key和value的写入方法。现在我们有某电商数据表cat_group1,包含(分组id,分组名称,分组码,奢侈品标记)四个字段cat_group1的数据内容如下:
cat_group1(group_id,group_name,group_code,flag)
- 分组id 分组名称 分组码 奢侈品标记
- 512 奢侈品 c 1
- 675 箱包 1 1
- 676 化妆品 2 1
- 677 家电 3 1
- 501 有机食品 1 0
- 502 蔬菜水果 2 0
- 503 肉禽蛋奶 3 0
- 504 深海水产 4 0
10. 505 地方特产 5 0
11. 506 进口食品 6 0
要求把相同奢侈品标记(flag)的数据放入到一个文件里,并且以该字段来命名文件的名称,输出时key与value 以“:”分割,形如"key:value"
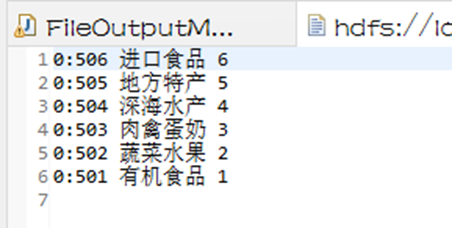
结果输出0.txt和1.txt两文件。
0.txt
- 奢侈品标记:分组ID 分组名称 分组码
- 0:506 进口食品 6
- 0:505 地方特产 5
- 0:504 深海水产 4
- 0:503 肉禽蛋奶 3
- 0:502 蔬菜水果 2
- 0:501 有机食品 1
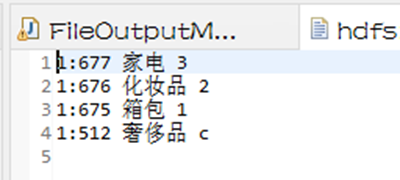
1.txt
- 奢侈品标记:分组ID 分组名称 分组码
- 1:677 家电 3
- 1:676 化妆品 2
- 1:675 箱包 1
- 1:512 奢侈品 c
实验步骤
1.切换到/apps/hadoop/sbin目录下,开启Hadoop。
- cd /apps/hadoop/sbin
- ./start-all.sh
2.在Linux本地新建/data/mapreduce12目录。
- mkdir -p /data/mapreduce12
3.在Linux中切换到/data/mapreduce12目录下,用wget命令从http://192.168.1.100:60000/allfiles/mapreduce12/cat_group1网址上下载文本文件cat_group1。
- cd /data/mapreduce12
- wget http://192.168.1.100:60000/allfiles/mapreduce12/cat_group1
然后在当前目录下用wget命令从http://192.168.1.100:60000/allfiles/mapreduce12/hadoop2lib.tar.gz网址上下载项目用到的依赖包。
- wget http://192.168.1.100:60000/allfiles/mapreduce12/hadoop2lib.tar.gz
将hadoop2lib.tar.gz解压到当前目录下。
- tar zxvf hadoop2lib.tar.gz
4.首先在HDFS上新建/mymapreduce12/in目录,然后将Linux本地/data/mapreduce12目录下的cat_group1文件导入到HDFS的/mymapreduce12/in目录中。
- hadoop fs -mkdir -p /mymapreduce12/in
- hadoop fs -put /data/mapreduce12/cat_group1 /mymapreduce12/in
5.新建Java Project项目,项目名为mapreduce12。
在mapreduce12项目下新建包,包名为mapreduce。
在mapredcue包下新建名为MyMultipleOutputFormat的类。
在mapredcue包下新建名为FileOutputMR的类。
6.添加项目所需依赖的jar包,右键单击项目名,新建一个文件夹hadoop2lib,用于存放项目所需的jar包。
将/data/mapreduce12目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce12项目的hadoop2lib目录下。
选中所有项目hadoop2lib目录下所有jar包,并添加到Build Path中。
7.编写程序代码,并描述设计思路
自定义FileRecordWriter类命名为MyMultipleOutputFormat,它继承了FileRecordWriter类,并且它里面主要包含三部分:类中的getRecordWriter、getTaskOutputPath、generateFileNameForKayValue方法和两个内部类LineRecordWriter、MutiRecordWriter
类中的方法代码:
- private MultiRecordWriter writer=null;
- public RecordWriter<K,V> getRecordWriter(TaskAttemptContext job) throws IOException{
- if(writer==null){
- writer=new MultiRecordWriter(job,getTaskOutputPath(job));
- }
- return writer;
- }
- private Path getTaskOutputPath(TaskAttemptContext conf) throws IOException{
- Path workPath=null;
- 10. OutputCommitter committer=super.getOutputCommitter(conf);
- 11. if(committer instanceof FileOutputCommitter){
- 12. workPath=((FileOutputCommitter) committer).getWorkPath();
- 13. }else{
- 14. Path outputPath=super.getOutputPath(conf);
- 15. if(outputPath==null){
- 16. throw new IOException("Undefined job output-path");
- 17. }
- 18. workPath=outputPath;
- 19. }
- 20. return workPath;
- 21. }
- 22. protected abstract String generateFileNameForKayValue(K key,V value,Configuration conf);
getRecordWriter()方法判断该类实例是否存在,若不存在则创建一个实例。getTaskOutputPath()方法获取工作任务的输出路径。generateFileNameForKayValue()方法是抽象的,通过key、value 和conf三个参数确定key/value输出的文件名,并将其返回。
LineRecordWriter类代码:
- protected static class LineRecordWriter<K,V> extends RecordWriter<K, V> {
- private static final String utf8 = "UTF-8";
- private static final byte[] newline;
- private PrintWriter tt;
- static {
- try {
- newline = "\n".getBytes(utf8);
- } catch (UnsupportedEncodingException uee) {
- throw new IllegalArgumentException("can't find " + utf8 + " encoding");
- 10. }
- 11. }
- 12.
- 13. protected DataOutputStream out;
- 14. private final byte[] keyValueSeparator;
- 15.
- 16. public LineRecordWriter(DataOutputStream out, String keyValueSeparator) {
- 17. this.out = out;
- 18. try {
- 19. this.keyValueSeparator = keyValueSeparator.getBytes(utf8);
- 20. } catch (UnsupportedEncodingException uee) {
- 21. throw new IllegalArgumentException("can't find " + utf8 + " encoding");
- 22. }
- 23. }
- 24.
- 25. public LineRecordWriter(DataOutputStream out) {
- 26. this(out, ":");
- 27. }
- 28. private void writeObject(Object o) throws IOException {
- 29. if (o instanceof Text) {
- 30. Text to = (Text) o;
- 31. out.write(to.getBytes(), 0, to.getLength());
- 32. } else {
- 33. out.write(o.toString().getBytes(utf8));
- 34. }
- 35. }
- 36.
- 37. public synchronized void write(K key, V value)
- 38. throws IOException {
- 39. boolean nullKey = key == null || key instanceof NullWritable;
- 40. boolean nullValue = value == null || value instanceof NullWritable;
- 41. if (nullKey && nullValue) {//
- 42. return;
- 43. }
- 44. if (!nullKey) {
- 45. writeObject(key);
- 46. }
- 47. if (!(nullKey || nullValue)) {
- 48. out.write(keyValueSeparator);
- 49. }
- 50. if (!nullValue) {
- 51. writeObject(value);
- 52. }
- 53. out.write(newline);
- 54.
- 55. }
- 56. public synchronized
- 57. void close(TaskAttemptContext context) throws IOException {
- 58. out.close();
- 59. }
- 60. }
LineRecordWriter类主要是为<key,value>输出时定义它的输出格式。通过加线程同步关键字 synchronized对write()方法上锁。write()方法首先从输出流中写入key-value,然后判断键值对是否为空,如果k-v为空,则操作失败返回空,如果key不为空,则写入key,如果key,value 都不为空则,在中间写入k-v分隔符,如果value不为空,则写入value,最后写入换行符。
MutiRecordWriter类代码:
- public class MultiRecordWriter extends RecordWriter<K,V>{
- private HashMap<String,RecordWriter<K,V> >recordWriters=null;
- private TaskAttemptContext job=null;
- private Path workPath=null;
- public MultiRecordWriter(TaskAttemptContext job,Path workPath){
- super();
- this.job=job;
- this.workPath=workPath;
- recordWriters=new HashMap<String,RecordWriter<K,V>>();
- 10.
- 11. }
- 12. public void close(TaskAttemptContext context) throws IOException, InterruptedException{
- 13. Iterator<RecordWriter<K,V>> values=this.recordWriters.values().iterator();
- 14. while(values.hasNext()){
- 15. values.next().close(context);
- 16. }
- 17. this.recordWriters.clear();
- 18. }
- 19. public void write(K key,V value) throws IOException, InterruptedException{
- 20. String baseName=generateFileNameForKayValue(key ,value,job.getConfiguration());
- 21. RecordWriter<K,V> rw=this.recordWriters.get(baseName);
- 22. if(rw==null){
- 23. rw=getBaseRecordWriter(job,baseName);
- 24. this.recordWriters.put(baseName,rw);
- 25. }
- 26. rw.write(key, value);
- 27. }
- 28.
- 29.
- 30. private RecordWriter<K,V> getBaseRecordWriter(TaskAttemptContext job,String baseName)throws IOException,InterruptedException{
- 31. Configuration conf=job.getConfiguration();
- 32. boolean isCompressed=getCompressOutput(job);
- 33. String keyValueSeparator= ":";
- 34. RecordWriter<K,V> recordWriter=null;
- 35. if(isCompressed){
- 36. Class<? extends CompressionCodec> codecClass=getOutputCompressorClass(job,(Class<? extends CompressionCodec>) GzipCodec.class);
- 37. CompressionCodec codec=ReflectionUtils.newInstance(codecClass,conf);
- 38. Path file=new Path(workPath,baseName+codec.getDefaultExtension());
- 39. FSDataOutputStream fileOut=file.getFileSystem(conf).create(file,false);
- 40. recordWriter=new LineRecordWriter<K,V>(new DataOutputStream(codec.createOutputStream(fileOut)),keyValueSeparator);
- 41. }else{
- 42. Path file=new Path(workPath,baseName);
- 43. FSDataOutputStream fileOut=file.getFileSystem(conf).create(file,false);
- 44. recordWriter =new LineRecordWriter<K,V>(fileOut,keyValueSeparator);
- 45. }
- 46. return recordWriter;
- 47. }
- 48. }
write()方法得到输出的文件名0.txt和1.txt并将两文件写到hdfs上,close()方法关闭输出文件的数据流。getBaseRecordWriter()方法首先用getCompressOutput(job) 从配置判断输出是否压缩,根据是否压缩获取相应的LineRecordWriter。
MyMultipleOutputFormat完整代码:
- package mapreduce;
- import java.io.DataOutputStream;
- import java.io.IOException;
- import java.io.PrintWriter;
- import java.io.UnsupportedEncodingException;
- import java.util.HashMap;
- import java.util.Iterator;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FSDataOutputStream;
10. import org.apache.hadoop.fs.Path;
11. import org.apache.hadoop.io.NullWritable;
12. import org.apache.hadoop.io.Text;
13. import org.apache.hadoop.io.Writable;
14. import org.apache.hadoop.io.WritableComparable;
15. import org.apache.hadoop.io.compress.CompressionCodec;
16. import org.apache.hadoop.io.compress.GzipCodec;
17. import org.apache.hadoop.mapreduce.OutputCommitter;
18. import org.apache.hadoop.mapreduce.RecordWriter;
19. import org.apache.hadoop.mapreduce.TaskAttemptContext;
20. import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
21. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
22. import org.apache.hadoop.util.ReflectionUtils;
23. public abstract class MyMultipleOutputFormat <K extends WritableComparable<?>,V extends Writable> extends FileOutputFormat<K,V>{
- 24. private MultiRecordWriter writer=null;
- 25. public RecordWriter<K,V> getRecordWriter(TaskAttemptContext job) throws IOException{
- 26. if(writer==null){
- 27. writer=new MultiRecordWriter(job,getTaskOutputPath(job));
- 28. }
- 29. return writer;
- 30. }
- 31. private Path getTaskOutputPath(TaskAttemptContext conf) throws IOException{
- 32. Path workPath=null;
- 33. OutputCommitter committer=super.getOutputCommitter(conf);
- 34. if(committer instanceof FileOutputCommitter){
- 35. workPath=((FileOutputCommitter) committer).getWorkPath();
- 36. }else{
- 37. Path outputPath=super.getOutputPath(conf);
- 38. if(outputPath==null){
- 39. throw new IOException("Undefined job output-path");
- 40. }
- 41. workPath=outputPath;
- 42. }
- 43. return workPath;
- 44. }
- 45. protected abstract String generateFileNameForKayValue(K key,V value,Configuration conf);
- 46. protected static class LineRecordWriter<K,V> extends RecordWriter<K, V> {
- 47. private static final String utf8 = "UTF-8";
- 48. private static final byte[] newline;
- 49. private PrintWriter tt;
- 50. static {
- 51. try {
- 52. newline = "\n".getBytes(utf8);
- 53. } catch (UnsupportedEncodingException uee) {
- 54. throw new IllegalArgumentException("can't find " + utf8 + " encoding");
- 55. }
- 56. }
- 57.
- 58. protected DataOutputStream out;
- 59. private final byte[] keyValueSeparator;
- 60.
- 61. public LineRecordWriter(DataOutputStream out, String keyValueSeparator) {
- 62. this.out = out;
- 63. try {
- 64. this.keyValueSeparator = keyValueSeparator.getBytes(utf8);
- 65. } catch (UnsupportedEncodingException uee) {
- 66. throw new IllegalArgumentException("can't find " + utf8 + " encoding");
- 67. }
- 68. }
- 69.
- 70. public LineRecordWriter(DataOutputStream out) {
- 71. this(out, ":");
- 72. }
- 73. private void writeObject(Object o) throws IOException {
- 74. if (o instanceof Text) {
- 75. Text to = (Text) o;
- 76. out.write(to.getBytes(), 0, to.getLength());
- 77. } else {
- 78. out.write(o.toString().getBytes(utf8));
- 79. }
- 80. }
- 81.
- 82. public synchronized void write(K key, V value)
- 83. throws IOException {
- 84. boolean nullKey = key == null || key instanceof NullWritable;
- 85. boolean nullValue = value == null || value instanceof NullWritable;
- 86. if (nullKey && nullValue) {//
- 87. return;
- 88. }
- 89. if (!nullKey) {
- 90. writeObject(key);
- 91. }
- 92. if (!(nullKey || nullValue)) {
- 93. out.write(keyValueSeparator);
- 94. }
- 95. if (!nullValue) {
- 96. writeObject(value);
- 97. }
- 98. out.write(newline);
- 99.
- }
- public synchronized
- void close(TaskAttemptContext context) throws IOException {
- out.close();
- }
- }
- public class MultiRecordWriter extends RecordWriter<K,V>{
- private HashMap<String,RecordWriter<K,V> >recordWriters=null;
- private TaskAttemptContext job=null;
- private Path workPath=null;
- public MultiRecordWriter(TaskAttemptContext job,Path workPath){
- super();
- this.job=job;
- this.workPath=workPath;
- recordWriters=new HashMap<String,RecordWriter<K,V>>();
- }
- public void close(TaskAttemptContext context) throws IOException, InterruptedException{
- Iterator<RecordWriter<K,V>> values=this.recordWriters.values().iterator();
- while(values.hasNext()){
- values.next().close(context);
- }
- this.recordWriters.clear();
- }
- public void write(K key,V value) throws IOException, InterruptedException{
- String baseName=generateFileNameForKayValue(key ,value,job.getConfiguration());
- RecordWriter<K,V> rw=this.recordWriters.get(baseName);
- if(rw==null){
- rw=getBaseRecordWriter(job,baseName);
- this.recordWriters.put(baseName,rw);
- }
- rw.write(key, value);
- }
- private RecordWriter<K,V> getBaseRecordWriter(TaskAttemptContext job,String baseName)throws IOException,InterruptedException{
- Configuration conf=job.getConfiguration();
- boolean isCompressed=getCompressOutput(job);
- String keyValueSeparator= ":";
- RecordWriter<K,V> recordWriter=null;
- if(isCompressed){
- Class<?extends CompressionCodec> codecClass=getOutputCompressorClass(job,(Class<?extends CompressionCodec>) GzipCodec.class);
- CompressionCodec codec=ReflectionUtils.newInstance(codecClass,conf);
- Path file=new Path(workPath,baseName+codec.getDefaultExtension());
- FSDataOutputStream fileOut=file.getFileSystem(conf).create(file,false);
- recordWriter=new LineRecordWriter<K,V>(new DataOutputStream(codec.createOutputStream(fileOut)),keyValueSeparator);
- }else{
- Path file=new Path(workPath,baseName);
- FSDataOutputStream fileOut=file.getFileSystem(conf).create(file,false);
- recordWriter =new LineRecordWriter<K,V>(fileOut,keyValueSeparator);
- }
- return recordWriter;
- }
- }
- }
测试程序代码也分为三部分Mapper部分reducer部分还有在里面添加一个静态类AlphabetOutputFormat。另外要注意在主函数里面把job的输出格式类设置为AlphabetOutputFormat类。
Mapper代码:
- public static class TokenizerMapper extends Mapper<Object,Text,Text,Text>{
- private Text val=new Text();
- public void map(Object key,Text value,Context context)throws IOException,InterruptedException{
- String str[]=value.toString().split("\t");
- val.set(str[0]+" "+str[1]+" "+str[2]);
- context.write(new Text(str[3]), val);
- }
- }
用split("\t")把数据截取出来,把代表flag的字段作为key,剩下的字段作为value,用context的write()方法将<key,value>直接输出。
reducer代码:
- public static class IntSumReducer extends Reducer<Text,Text,Text,Text>{
- public void reduce(Text key,Iterable<Text> values,Context context)
- throws IOException,InterruptedException{
- for(Text val:values){
- context.write(key,val);
- }
- }
- }
map输出的<key,value>键值对先经过shuffle,把key相同的value值放到一个迭代器中形成values,在将<key,values>传递给reduce函数,reduce函数将输入的key直接复制给输出的key,将输入的values通过增强版for循环遍历,并把里面的每个元素赋值给输出的value,再用context的write()方法进行逐一输出<key,value>,输出的次数为循环的次数。
AlphabetOutputFormat代码:
- public static class AlphabetOutputFormat extends MyMultipleOutputFormat<Text,Text>{
- protected String generateFileNameForKayValue(Text key,Text value,Configuration conf){
- return key+".txt";
- }
- }
该类继承MyMultipleOutputFormat类并重写generateFileNameForKayValue()抽象方法,令其返回值为key+".txt"。
测试类完整代码:
- package mapreduce;
- import java.io.IOException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
10. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
11. public class FileOutputMR {
- 12. public static class TokenizerMapper extends Mapper<Object,Text,Text,Text>{
- 13. private Text val=new Text();
- 14. public void map(Object key,Text value,Context context)throws IOException,InterruptedException{
- 15. String str[]=value.toString().split("\t");
- 16. val.set(str[0]+" "+str[1]+" "+str[2]);
- 17. context.write(new Text(str[3]), val);
- 18. }
- 19. }
- 20. public static class IntSumReducer extends Reducer<Text,Text,Text,Text>{
- 21. public void reduce(Text key,Iterable<Text> values,Context context)
- 22. throws IOException,InterruptedException{
- 23. for(Text val:values){
- 24. context.write(key,val);
- 25. }
- 26. }
- 27. }
- 28. public static class AlphabetOutputFormat extends MyMultipleOutputFormat<Text,Text>{
- 29. protected String generateFileNameForKayValue(Text key,Text value,Configuration conf){
- 30. return key+".txt";
- 31. }
- 32. }
- 33. public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException{
- 34. Configuration conf=new Configuration();
- 35. Job job=new Job(conf,"FileOutputMR");
- 36. job.setJarByClass(FileOutputMR.class);
- 37. job.setMapperClass(TokenizerMapper.class);
- 38. job.setCombinerClass(IntSumReducer.class);
- 39. job.setReducerClass(IntSumReducer.class);
- 40. job.setOutputKeyClass(Text.class);
- 41. job.setOutputValueClass(Text.class);
- 42. job.setOutputFormatClass(AlphabetOutputFormat.class);
- 43. FileInputFormat.addInputPath(job,new Path("hdfs://localhost:9000/mymapreduce12/in/cat_group1"));
- 44. FileOutputFormat.setOutputPath(job,new Path("hdfs://localhost:9000/mymapreduce12/out"));
- 45. System.exit(job.waitForCompletion(true)?0:1);
- 46. }
- 47. }
8.在FileOutputMR类文件中,右键并点击=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。
9.待执行完毕后,进入命令模式,在HDFS上从mymapreduce12/out中查看实验结果。
- hadoop fs -ls /mymapreduce12/out
- hadoop fs -cat /mymapreduce12/out/0.txt
- hadoop fs -cat /mymapreduce12/out/1.txt