---------Python基础编程---------
Author : AI菌
【内容讲解】
一、需求 根据用户的请求返回指定页面的数据,如果请求的资源没有, 返回404页面 二、实现步骤 1、获取用户请求资源的路径 2、根据请求资源的路径,读取指定文件的数据 3、组装指定文件数据的响应报文,发送给浏览器 4、判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器 三、需要考虑的问题 1、客户端建立连接后没有发送任何数据就下线的情况 2、判断请求的是否是根目录,如果是根目录设置返回的信息 3、打开文件,读取文件中的数据, 使用rb模式,兼容打开图片文件 4、如果请求的资源没有, 返回404页面
【代码演示】
""" 一、需求 根据用户的请求返回指定页面的数据,如果请求的资源没有, 返回404页面 二、实现步骤 1、获取用户请求资源的路径 2、根据请求资源的路径,读取指定文件的数据 3、组装指定文件数据的响应报文,发送给浏览器 4、判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器 三、需要考虑的问题 1、客户端建立连接后没有发送任何数据就下线的情况 2、判断请求的是否是根目录,如果是根目录设置返回的信息 3、打开文件,读取文件中的数据, 使用rb模式,兼容打开图片文件 4、如果请求的资源没有, 返回404页面 """ import socket def main(): # 创建tcp服务端套接字 tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 设置端口号复用, 程序退出端口立即释放 tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True) # 绑定端口号 tcp_server_socket.bind(("", 8000)) # 设置监听 tcp_server_socket.listen(128) # 循环响应客户端请求 while True: # 等待接受客户端的连接请求 new_socket, port = tcp_server_socket.accept() # 代码执行到此,说明连接建立成功 # 接收客户端的数据 recv_client_data = new_socket.recv(4096) # 判断接收的客户端数据是否为0 if len(recv_client_data) == 0: new_socket.close() return # 对二进制数据进行解码 recv_client_content = recv_client_data.decode("utf-8") print("来自客户端的数据:", recv_client_content) # 对数据按照空格进行分割,分割2次 request_list = recv_client_content.split(" ", maxsplit=2) # 获取请求资源的路径 request_path = request_list[1] print("截取的请求资源的路径:", request_path) # 判断请求的是否是根目录,如果是根目录设置返回的信息 if request_path == "/": request_path = "/index.html" try: # 读取文件数据 # rb表示以二进制的方式读取文件数据,图片数据需要以二进制格式打开,使用rb with open("static" + request_path, "rb") as file: file_data = file.read() except Exception as e: # 代码执行到此,说明没有请求的文件,返回404状态信息 # 响应行 response_line = "HTTP/1.1 404 NOT FOUND " # 响应头 response_header = "server:DiamondDownload1.0 " # 读取404页面数据 with open("static/error.html", "rb") as file: file_data = file.read() # 响应体 response_body = file_data # 把数据封装成http响应报文格式的数据 response_data = (response_line + response_header + " ").encode("utf-8") + response_body # 发送给浏览器的响应报文数据 new_socket.send(response_data) else: # 代码执行到此,说明有请求的文件,返回200状态信息 # 响应行 response_line = "HTTP/1.1 200 OK " # 响应头 response_header = "server:DiamondDownload1.0 " # 响应体 response_body = file_data # 把数据封装成http响应报文格式的数据 response_data = (response_line + response_header + " ").encode("utf-8") + response_body # 发送给浏览器的响应报文数据 new_socket.send(response_data) finally: # 关闭服务端与客户端套接字 new_socket.close() if __name__ == '__main__': main()
【运行结果】
服务端程序控制台打印结果:
来自客户端的数据: GET /xxx.html HTTP/1.1 Host: 192.168.1.64:8000 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 截取的请求资源的路径: /xxx.html
浏览器访问:
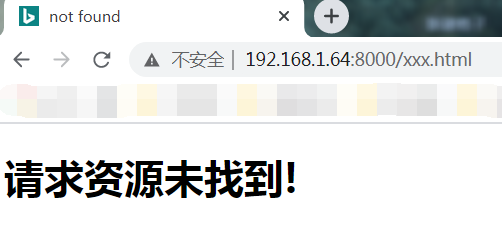 |
【往期精彩】
▷【Python基础编程196 ● 读取文件的4种方式】
▷【Python基础编程197 ● 读取文件的4种方式】
▷【Python基础编程198 ● 读取文件的4种方式】
▷【Python基础编程199 ● Python怎么读/写很大的文件】
▷【Python基础编程200 ● 读取文件的4种方式】
▷【Python基础编程201 ● 读取文件的4种方式】
▷【Python基础编程202 ● 读取文件的4种方式】
▷【Python基础编程203 ● 读取文件的4种方式】
【加群交流】
 |
 |
 |
 |