注:以下是本人对Explain Plan的试分析,有不对的地方希望大家指出。关于如何查看Oracle的解释计划请参考:https://www.cnblogs.com/xiandedanteng/p/12123819.html
例一:
执行的SQL语句:
EXPLAIN plan for select * from hy_emp emp,hy_dept dept where emp.deptno=dept.deptno and emp.empno=1 select * from table(dbms_xplan.display)
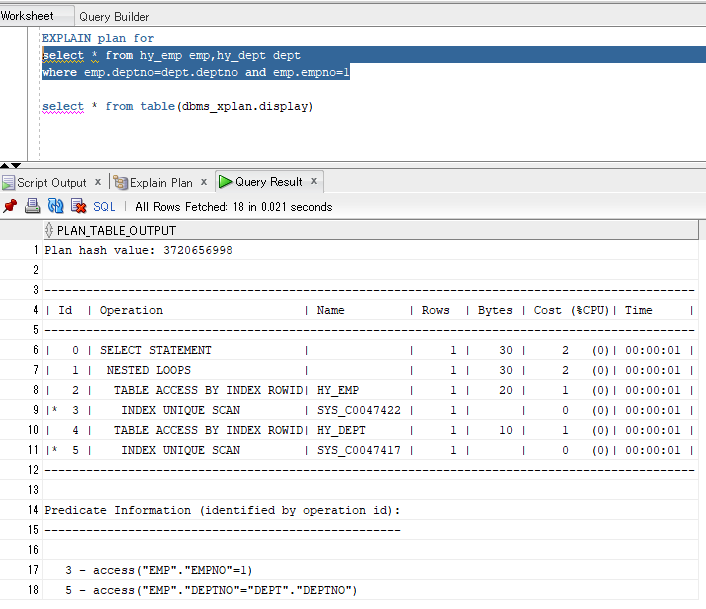
首先执行#3,在HY_EMP表进行empno=1的查找(索引唯一扫描方式);
再执行#5,在HY_DEPT表进行emp.deptno=dept.deptno的连接(索引唯一扫描方式);
然后,把两个结果集进行嵌套循环连接;
最后,把select子句里的字段带上。
例二:
执行的SQL语句:
EXPLAIN plan for select * from hy_emp emp,hy_dept dept where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
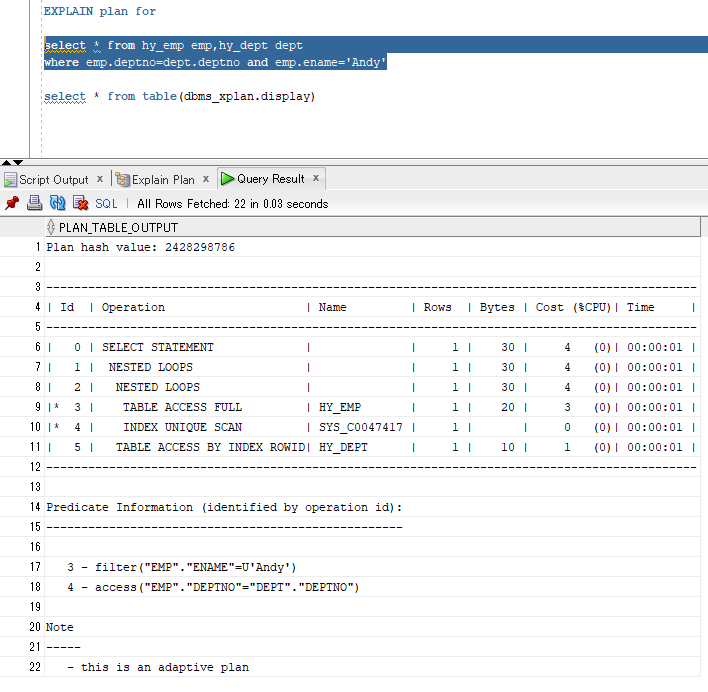
分析:
#9先执行,在emp表进行NAME=Andy的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#10第二执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键);
#8第三执行,将#9,#10两步得到的结果集(两者都是EMP表的子集)进行嵌套循环连接;
接下来,将#8得到的结果集与#11进行嵌套循环连接(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键)
最后执行#6,把select子句都带出来。
例三:
SQL:
EXPLAIN plan for select emp.* from hy_emp emp,hy_dept dept where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
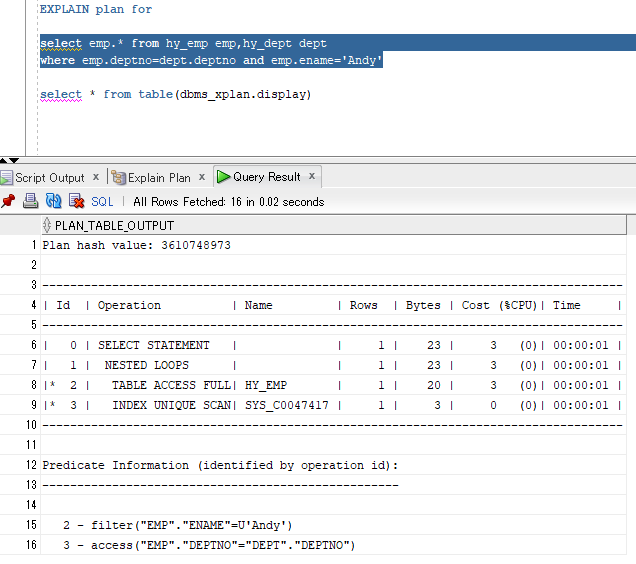
解读:
#8先执行,在emp表进行NAME=Andy的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#9第二执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键)
#7再执行,将#8,#9两步得到的结果集(均为emp的子集)进行嵌套循环连接;
由于select子句中只要emp表的字段,因此#7得到的结果集就是最终结果集;
最后把select子句中字段都带出来。
这一段也印证了前面关于 “#8,#9两步得到的结果集均为emp的子集” 的论断。
例四:
SQL:
EXPLAIN plan for select dept.* from hy_emp emp,hy_dept dept where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
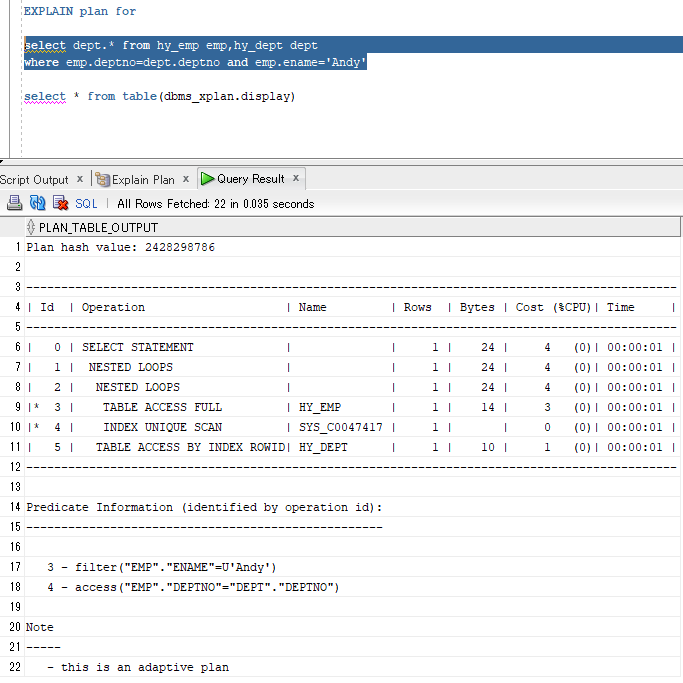
解读:
#9先执行,在emp表进行NAME=Andy的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#10第二执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键)
#8再执行,将#9,#10两步得到的结果集(均为emp的子集)进行嵌套循环连接;
由于select子句中需要dept表的字段,因此#8得到的结果集因为只是emp的子集不足以提供dept表的字段,还需要与dept表做一次连接;
#7执行,将#11得到的结果集(dept表的子集)与#8结果集进行嵌套循环连接;
最后带上select子句的字段。
例五:
SQL:
EXPLAIN plan for select count(*) from hy_emp emp,hy_dept dept where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
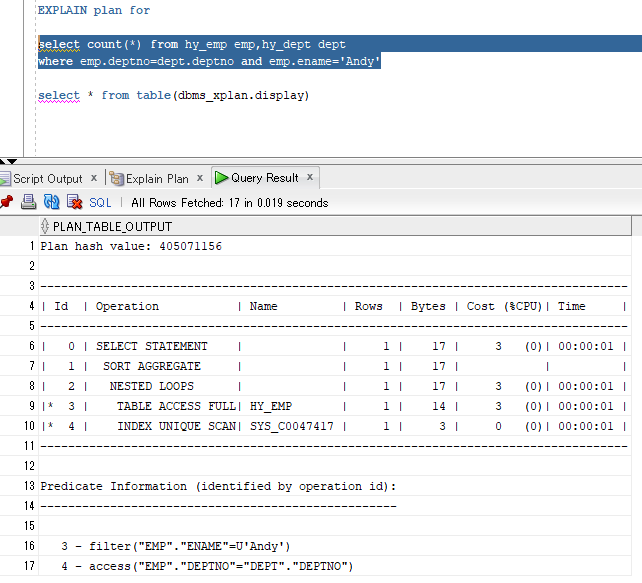
解读:
#9,#10,#8的分析和前面的同类语句类似;
因最终不需要dept表的数据,因此得到#8的结果集就够count(×)的统计了;
#7 的sort aggregate是排序聚合的意思,但这并非动作,而是代表语句类型,从cost看它也未产生消耗;
最后把select子句带出来就够了。
例六:
SQL:
EXPLAIN plan for select * from hy_emp emp,hy_dept dept where emp.deptno=dept.deptno and emp.ename like '%in%' order by emp.empno select * from table(dbms_xplan.display)
截图:
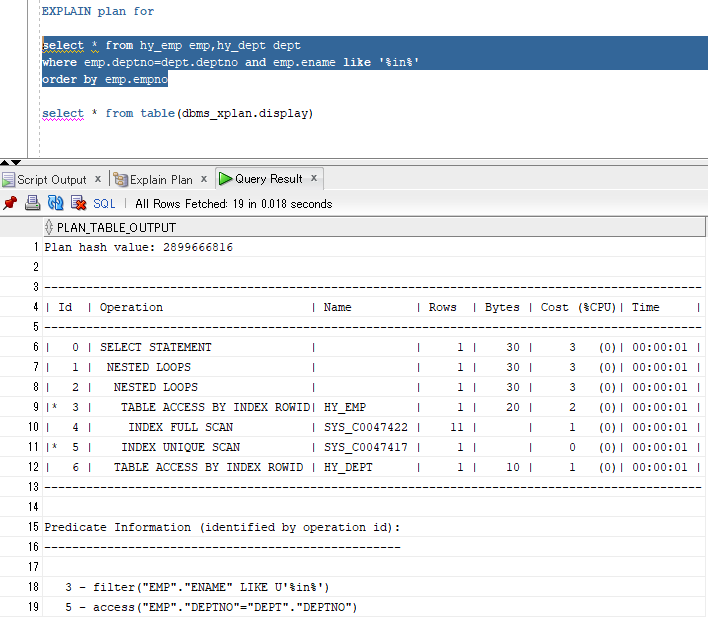
解读:
从缩进层次里来看,#10先执行,这一步走的是emp表的按empno排序(索引全扫描方式) ;
#9之后执行,在emp表进行NAME like ‘%in%’的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#11再执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取数据(ACCESS方式),因为DEPTNO是DEPT表的主键)
#8再执行,将#9,#10两步得到的结果集(均为emp的子集)进行嵌套循环连接;
因为是select *,#8得到的结果集不足以成为最终结果集,它还要与dept表进行连接(从#8结果集找出deptno直接到dept中去找)
最后把select子句带出来。
附:以上SQL涉及到的表及其数据:
CREATE TABLE hy_emp ( empno NUMBER(8,0) not null primary key, ename NVARCHAR2(60) not null, deptno NUMBER(8,0) not null, sal NUMBER(10,0) DEFAULT 0 not null ) CREATE TABLE hy_dept ( deptno NUMBER(8,0) not null primary key, dname NVARCHAR2(60) not null )
数据:
insert into hy_dept(deptno,dname) values('1','Hr'); insert into hy_dept(deptno,dname) values('2','Dev'); insert into hy_dept(deptno,dname) values('3','Qa'); insert into hy_dept(deptno,dname) values('4','Sales'); insert into hy_dept(deptno,dname) values('5','Mng'); insert into hy_emp(empno,ename,deptno,sal) values('1','Andy','1',1000); insert into hy_emp(empno,ename,deptno,sal) values('2','Bill','2',2000); insert into hy_emp(empno,ename,deptno,sal) values('3','Cindy','3',3000); insert into hy_emp(empno,ename,deptno,sal) values('4','Douglas','4',4000); insert into hy_emp(empno,ename,deptno,sal) values('5','Edinburg','5',5000); insert into hy_emp(empno,ename,deptno,sal) values('6','Felix','1',6000); insert into hy_emp(empno,ename,deptno,sal) values('7','Hellen','2',7000); insert into hy_emp(empno,ename,deptno,sal) values('8','Isis','3',8000); insert into hy_emp(empno,ename,deptno,sal) values('9','Jean','4',9000); insert into hy_emp(empno,ename,deptno,sal) values('10','King','5',10000); insert into hy_emp(empno,ename,deptno,sal) values('11','Mac','1',11000);
--END-- 2019-12-31 13:47