
Collection是所有集合的接口,这个接口定义了一些集合统一访问的接口,子类集合根据自己的特点来实现这些接口功能。


集合中通常使用foreach遍历

一、List
List是有序不重复有索引的集合,它用某种特定的插入顺序来维护元素顺序,可以根据索引来访问元素(类似于数组)。
1.ArrayList(有序可重复有索引)
ArrayList是一个用数组实现的集合,可以插入任何类型的元素甚至null也可以。
每个ArrayList的初始容量都是10,但是ArrayList会根据用户所存的元素数量进行扩容。(扩容规则:(原数组长度*3)/2+1)
由于是数组实现的集合,所以插入和删除效率低,查询效率高。
ArrayList是非线程安全的列表,Vector与ArrayList相似,操作几乎一模一样,但是是线程安全的。
Vector在进行默认扩容时的扩容规则:(新数组长度=旧数组长度*2)
1 package com.chinasofti.list;
2
3 import java.util.ArrayList;
4 import java.util.List;
5
6 public class arraylist {
7 public static void main(String[] args) {
8 // 创建ArrayList集合对象 一般都是使用向上造型。用List引用指向ArrayList对象
9 List arrayList = new ArrayList();
10 // 向集合中添加数据
11 arrayList.add(1);
12 arrayList.add("哈哈");
13 arrayList.add('A');
14 arrayList.add(1>2);
15
16 // 遍历集合
17 /*for (Object o:arrayList) {
18 System.out.println(o);
19 }*/
20 // 使用for循环遍历集合内容
21 for (int i = 0; i < arrayList.size(); i++) {
22 // 获取集合中元素的值
23 System.out.println(arrayList.get(i));
24 }
25
26 // 删除索引为1的值
27 arrayList.remove(1);
28 System.out.println("-------------------------");
29 // 查询集合中是否存在'A'
30 System.out.println("集合中是否存在'A':"+arrayList.contains('A'));
31
32 // 删除集合内的所有内容
33 arrayList.clear();
34
35 for (Object o:arrayList) {
36 System.out.println(o);
37 }
38 }
39 }
2.LinkedList(有序可重复)
LinkedList和ArrayList不同,linkedlist是由链表实现的,所以插入和删除效率高,查询效率低。除了ArrayList方法之外,还提供了对队里首位的get,remove,insert方法。
List list = new LinkedList();
// list首尾插入值
list.insertFirst("first");
list.insertLast("last");
// 获取list的首尾值
list.getFirst();
list.getLast();
// 删除list的首尾值
list.removeFirst();
list.removeLast();
LinkedList实现方式不同,所以不能随机访问,所有的查询都是和链表一样,从头或者结尾开始遍历,这样的话损失了查询效率,但是增加了插入和删除的效率。
linkedlist和ArrayList一样,也是非线程安全的。
1 package com.chinasofti.list;
2
3 import java.util.LinkedList;
4 import java.util.List;
5
6 public class LinkedListTest {
7 public static void main(String[] args) {
8 // 创建list集合对象 一般都是使用向上造型。用List引用指向list对象
9 // List list = new LinkedList();
10 LinkedList list = new LinkedList();
11 // 向集合中添加数据
12 list.add(1);
13 list.add("哈哈");
14 list.add('A');
15 list.add(1>2);
16
17 // linkedlist 子类扩展的方法 注意:父类List里没有这些方法
18 list.addFirst("first");
19 list.addLast("last");
20 System.out.println("addFirst:" + list.getFirst());
21 System.out.println("addLast:" + list.getLast());
22
23
24 // 遍历集合
25 /*for (Object o:list) {
26 System.out.println(o);
27 }*/
28 // 使用for循环遍历集合内容
29 for (int i = 0; i < list.size(); i++) {
30 // 获取集合中元素的值
31 System.out.println(list.get(i));
32 }
33
34 // 删除索引为1的值
35 list.remove(1);
36 System.out.println("-------------------------");
37 // 查询集合中是否存在'A'
38 System.out.println("集合中是否存在'A':"+list.contains('A'));
39
40 // 删除集合内的所有内容
41 list.clear();
42
43 for (Object o:list) {
44 System.out.println(o);
45 }
46 }
47 }
3.stack
继承自vector,实现了一个后入先出的栈。
有五个方法:pop(出栈),push(入栈),peek(获得栈顶的元素),empty(判断栈是否为空),search(检测一个元素在栈里的位置)。
stack在刚创建时是空栈。
4.vector,ArrayList,linkedlist的区别
vector: 线程安全 数组实现 效率低
ArrayList:非线程安全 数组实现 查询效率高 插入和删除效率低
linkedlist:非线程安全 链表实现 查询效率低 插入和删除效率高
二、set(无序不重复)
EnumSet:是枚举专用的set,所有的元素类型都是枚举。
HashSet:HashSet是查询速度最快的集合,因为内部是由HashCode来实现的,它内部元素的顺序是由哈希码来决定的,所以他不保证set的顺序问题。
TreeSet:基于TreeMap,生成一个总是处于排队状态的set,内部是由TreeMap实现,它使用元素的自然顺序来排序,或者是创建set时提供comparator进行排序,具体取决于使用的构造方法。
1.HashSet(无序)
根据具体的hashCode方法,来判断是否是可以包含有重复元素,例如:hashcode方法是默认的(依据对象在内存中的地址来计算),并且HashSet存放引用数据类型,就算两个对象相同,但是由于两个对象的内存地址不同,所以可以存放。
集合元素的hashCode方法返回的哈希值对HashSet非常重要,因为HashSet会优先使用这个哈希值判断两个元素是否相同并确定元素的位置。
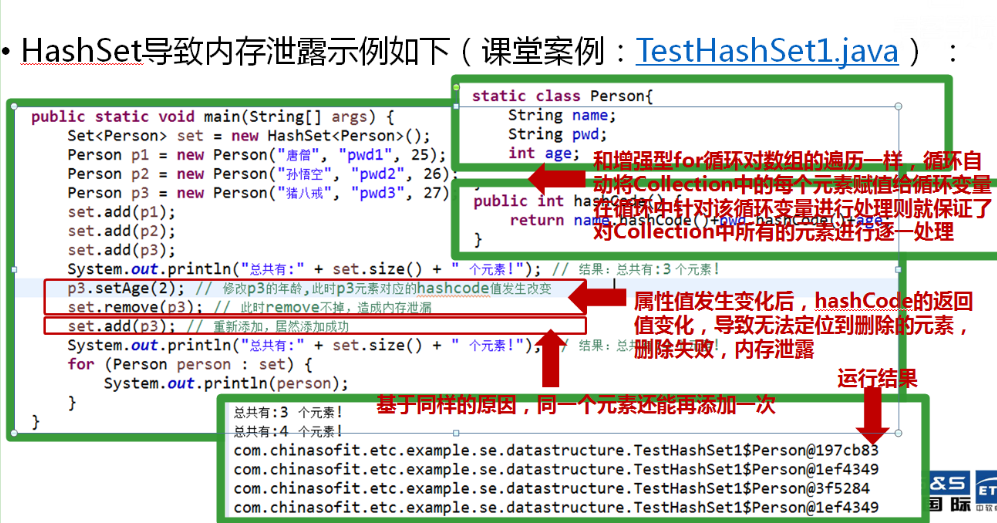
如果我们定义的hashCode方法不够合理,那么就会出现内存泄漏的现象。
造成内存泄漏的原因是remove,当HashSet集合中的某个值发生变化,那么这个值的哈希值也会发生变化,这时如果使用remove删除这个值,那么由于哈希值的变化导致remove无法定位到索要删除的值的位置,所以无法删除这个值。示例:
1 package com.chinasofti.set;
2
3 import java.util.HashSet;
4 import java.util.Set;
5
6 public class HashSetTest {
7 public static void main(String[] args) {
8 /*
9 * 默认的hashCode方法是按照对象的存储地址来进行计算的 如果重写hashcode方法不当,一个对象的hashcode值在修改后,
10 * hashcode值会发生变化,那么使用set.remove方法删除对象,并不会删除到之前的对象,这个过程叫做内存泄漏。
11 * */
12
13 // 创建set集合
14 Set set = new HashSet();
15 // 创建Student对象
16 Student s1 = new Student(1001, "z1", 99);
17 Student s2 = new Student(1002, "z2", 91);
18 Student s3 = new Student(1003, "z3", 92);
19 Student s4 = new Student(1003, "z4", 92);
20 // set集合中添加数据
21 set.add(s1);
22 set.add(s2);
23 set.add(s3);
24 set.add(s4);
25 // 遍历set集合
26 for (Object s:set) {
27 System.out.println(s + "---" + s.hashCode());
28 }
29 // 查看set中的元素个数
30 System.out.println("size:" + set.size());
31 // 查看set集合中是否为空
32 System.out.println("isEmpty"+set.isEmpty());
33
34 System.out.println(s1.hashCode());
35 s1.setId(100001);
36 s1.setName("100001");
37 s1.setScore(100001);
38 System.out.println(s1.hashCode());
39 // 删除remove
40 set.remove(s1);
41 // 遍历set集合
42 for (Object s:set) {
43 System.out.println(s + "---" + s.hashCode());
44 }
45 }
46 }
2.TreeSet(有序不重复)
TreeSet扩展自AbstractSet,并且实现了NavigableSet,AbstractSet扩展自AbstractCollection,TreeSet是一个有序的Set,为了实现排序功能,TreeSet需要实现Comparator。在实例化TreeSet时,我们也可以给TreeSet一个比较器来指定树形中元素的顺序。
注意:例如下列代码中的比较器中设置比较两个student对象的成绩,当compareTo方法返回0时,TreeSet是默认两个对象是相等的,所以默认不添加到TreeSet集合中。
1 package com.chinasofti.data.tree; 2 3 public class TreeTest { 4 private MyTree root; 5 6 public TreeTest() { 7 this.root = null; 8 } 9 10 // 向树中添加节点 11 public void addNode(MyTree myTree) { 12 MyTree current = root; 13 // 如果根节点为null 14 if (root == null) { 15 this.root = myTree; 16 } else { 17 current = this.root; 18 while (true) { 19 if (myTree.getKey() > current.getKey()) { 20 // 如果新节点的值大于父节点 放右子树 21 if (current.getRight() == null) { 22 current.setRight(myTree); 23 break; 24 } 25 current = current.getRight(); 26 } else if (myTree.getKey() < current.getKey()) { 27 // 如果新节点的值小于父节点 放左子树 28 if (current.getLeft() == null) { 29 current.setLeft(myTree); 30 break; 31 } 32 current = current.getLeft(); 33 } 34 } 35 } 36 } 37 38 // 按照某个节点的key查找值 39 public int getValue(int key) { 40 MyTree current = this.root; 41 42 while (true) { 43 // 判断节点是否为所查询节点 44 if (current.getKey() == key) { 45 return current.getValue(); 46 } else { 47 // 判断key值和current节点的左子树和右子树的跟节点key值大小 48 49 if (current.getKey() > key) { 50 // 如果所查的key值大于current的key 将左子树返回 51 current = current.getLeft(); 52 }else { 53 current = current.getRight(); 54 } 55 } 56 } 57 } 58 }
三、Map
Map是由一系列的键值对组成的集合,提供了key到value的映射。Map没有继承Collection。
在Map中保证了key和Value之间的一一对应,也就是说一个key对应一个value,所以key值不能出现重复,如果出现重复,那么就会覆盖。
value可以相同。
1.HashMap(无序):
在之前的版本中,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里(和我们在之前自行实现的哈希表相同)。但是当链表中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
而JDK1.8中,HashMap采用数组+链表+红黑树(一种平衡搜索二叉树)实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间
HashMap是基于哈希表的Map接口的非同步实现,继承自AbstractMap,AbstractMap是部分实现Map接口的抽象类
和vector类似,Map体系也有一个自JDK1.2之前遗留的工具:HashTable,它的操作接口和HashMap相似,和HashMap的区别在于:HashMap是非线程安全的,HashTable是线程安全的。
LinkedHashMap:继承自HashMap,他主要是使用链表来扩展HashMap类,HashMap类中条目是没有顺序的,但是在LinkedHashMap中元素既可以按照他们插入时的顺序,也可以按照他们最后一次被访问的顺序排序。
注意:Map中是根据键值来细算hashcode值。
1 package com.chinasofti.map;
2
3 import com.chinasofti.set.Student;
4
5 import java.util.HashMap;
6 import java.util.Map;
7 import java.util.Set;
8
9 public class HashMapTest {
10 // 必须保证key不重复
11 public static void main(String[] args) {
12 // 创建一个hashmap对象
13 Map<Integer, Student> map = new HashMap<>();
14
15 Student s1 = new Student(1001, "z1", 99);
16 Student s2 = new Student(1002, "z2", 91);
17 Student s3 = new Student(1003, "z3", 92);
18 Student s4 = new Student(1004, "z3", 92);
19
20 map.put(s1.getId(),s1);
21 map.put(s2.getId(),s2);
22 map.put(s3.getId(),s3);
23 map.put(s4.getId(),s4);
24
25 // 遍历需要先获取map中的所有key值 返回一个set集合
26 Set<Integer> keys = map.keySet();
27 // 然后遍历keys 来获取每一个map内的value数据
28 for ( Integer i:keys) {
29 System.out.println(i + "---" + map.get(i));
30 }
31 }
32 }
2.TreeMap
TreeMap是基于红黑树实现的,键值可以使用Comparable或者Comparator接口来排序。TreeMap继承自AbstractMap,同时实现了接口的NavigableMap,而接口NavigableMap则继承自SortedMap。SortedMap是Map的子接口,使用它可以确保树中的条目是排序好。
注意:例如下列代码中的比较器中设置比较两个student对象的成绩,当compareTo方法返回0时,TreeMap是默认两个对象是相等的,所以默认不添加到TreeSet集合中。
1 package com.chinasofti.map;
2
3 import com.chinasofti.set.Student;
4
5 import java.util.Map;
6 import java.util.Set;
7 import java.util.TreeMap;
8
9 public class TreeMapTest {
10 public static void main(String[] args) {
11 // TreeMap的排序是按照key来排序 必须保证key不重复
12 Map<Student, Student> map = new TreeMap<Student, Student>((o1,o2)->{
13 // 按照id的升序排列
14 // return ((Integer)o1.getId()).compareTo((Integer)o2.getId());
15 return ((Double)o1.getScore()).compareTo((Double)o2.getScore());
16 });
17
18 Student s1 = new Student(1001, "z1", 99);
19 Student s2 = new Student(1002, "z2", 91);
20 Student s3 = new Student(1003, "z3", 92);
21 Student s4 = new Student(1004, "z3", 92);
22
23 map.put(s1,s1);
24 map.put(s2,s2);
25 map.put(s3,s3);
26 map.put(s4,s4);
27
28 Set<Student> students = map.keySet();
29
30 for (Student s :students) {
31 System.out.println(map.get(s));
32 }
33 }
34 }
在实际使用中,如果更新Map时不需要保持图中元素的顺序,就使用HashMap,
如果需要保持Map中元素的插入顺序或者访问顺序,就使用LinkedHashMap,
如果需要使图按照键值排序,就使用TreeMap