1、SQL执行的流程
SqlServer会对每一条执行的指令生成一个执行计划并对执行计划进行缓存plan cache,通常情况下执行同样的SQL下次会直接查找plan进行执行跳过编译的过程。新指令通常的执行流程为“收到执行指令——》plan cache中找不到(找到则跳过到编译的流程)——》解释(语法、句法)——》编译——》生成执行计划并加入cache——》执行”。
SQL指令的执行方式如下:
(1)从缓存的执行计划执行
为了避免资源的浪费提高整体执行的效率SqlServer通常会查找plan cache执行,但执行计划的好坏最终决定了执行的效率缓存的plan并非最好的(这点在优化性能时需注意,某些情况下可能需要手工重建执行计划)。
(2)重编译
有些时候,SqlServer为了确保返回正确的值,或者有性能上的顾虑,有意不重用缓存在内存里的执行计划,而现场编译一份,这种行为,被称为重编译(recompile)。包括如下情况:
A、当指令或者批处理所涉及的任何一个对象(表格或者视图)发生了架构(schema)变化
B、运行过sp_recompile
C、有些动作会清除内存里的所有执行计划,迫使大家都要做重编译
D、当下面这些SET 开关值变化后,先前的那些执行计划都不能重用
E、当表格或者视图上的统计信息发生变化后
2、执行计划
(1)作用
当我们的系统上线后数据库的记录不断增加,之前写的一些SQL语句或者一些ORM操作效率变得非常低。我们不得不考虑SQL优化,SQL优化大概是这样一个流程:
A、定位执行效率低的SQL语句(定位)
B、分析为什么这段SQL执行的效率比较低(分析)
C、最后根据第二步分析的结构采取优化措施(解决)
执行计划可以告诉我们SQL的执行情况包括SQL如何使用索引、连接查询的执行顺序、查询的数据行数等。
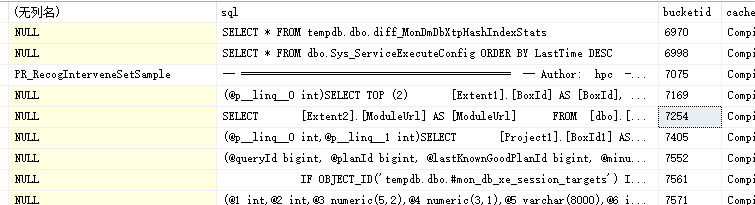
可通过如下语句查看缓存的执行计划
SELECT OBJECT_NAME(objid),sql,* FROM sys.[syscacheobjects] WHERE cacheobjtype='Compiled Plan'
(2)显示执行计划的方式
A、SSMS界面进行选择
B、使用快捷键Ctrl+l
C、通过SET开关控制
.SHOWPLAN_TEXT – 显示了一个基本的基于文本的预估执行计划,而不必执行查询。
.SHOWPLAN_ALL – 显示带有消耗预估值的基于文本的预估执行计划,而不必执行查询。
.SHOWPLAN_XML – 显示带有消耗预估值的基于XML的预估执行计划,而不必执行查询。等于在SQL Server Management Studio中的“Display Estimated Execution Plan…”选项。
.STATISTICS PROFILE – 执行查询并显示基于文本的实际执行计划。
STATISTICS XML – 执行查询并显示基于XML的实际执行计划。等于在SQL Server Management Studio中的“Include Actual Execution Plan”选项。
D、使用SQL Server Profiler
E、通过执行计划缓存获取
查看开销大的执行计划:
按平均 CPU 时间检索有关前五个查询的信息
SELECT TOP 5 total_worker_time/execution_count AS [Avg CPU Time], Plan_handle, query_plan FROM sys.dm_exec_query_stats AS qs CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) ORDER BY total_worker_time/execution_count DESC; GO
3、根据执行计划进行优化
根据执行计划进行优化主要是去找到开销比较大的块进行分析并优化,关注点包括数据访问的操作方式、读取的数据量大小及是否采用临时表等。数据访问的方式无非是扫描、查找及两者的结合。扫描就是读取整个结构,可以访问一个heap或者一个clustered索引或者一个non-clustered索引,而查找则不会读取整个结构,它则是更高效地通过索引访问一行,所以从这个角度来看,查找就只能应用在索引上面了。

(1)访问操作
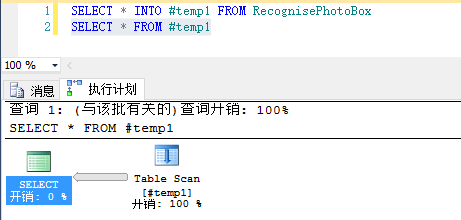
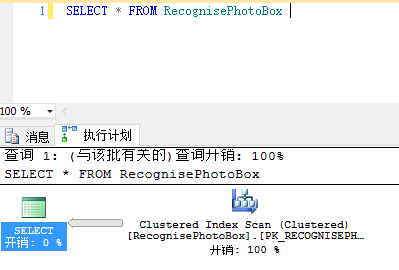
以下讲解相关的概念,以表RecognisePhotoBox为例:
CREATE TABLE [dbo].[RecognisePhotoBox] ( [BoxId] [bigint] NOT NULL IDENTITY(1, 1), [VenderId] [int] NOT NULL, [PhotoId] [varchar] (50) COLLATE Chinese_PRC_CI_AS NOT NULL, [SkuCode] [int] NOT NULL ) ALTER TABLE [dbo].[RecognisePhotoBox] ADD CONSTRAINT [PK_RECOGNISEPHOTOBOX] PRIMARY KEY CLUSTERED ([BoxId]) CREATE NONCLUSTERED INDEX [nci_RecognisePhotoBox_PhotoId_VenderId] ON [dbo].[RecognisePhotoBox] ([PhotoId], [VenderId])
A、表扫描
效率最低,大数据表尽量避免使用(临时表也一样需要建索引)
B、Clustered Index扫描
C、non-Clustered Index扫描
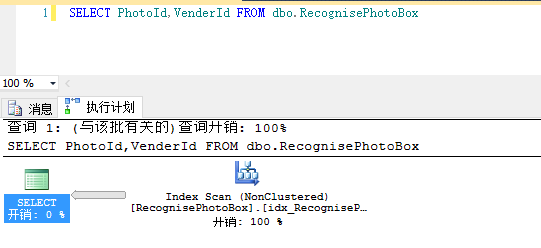
D、Clustered Index查找
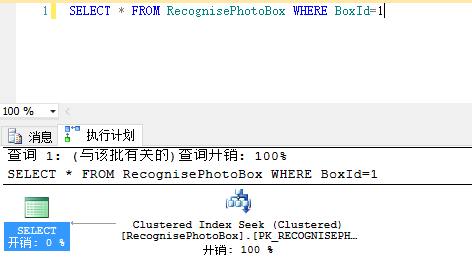
E、non-Clustered Index查找
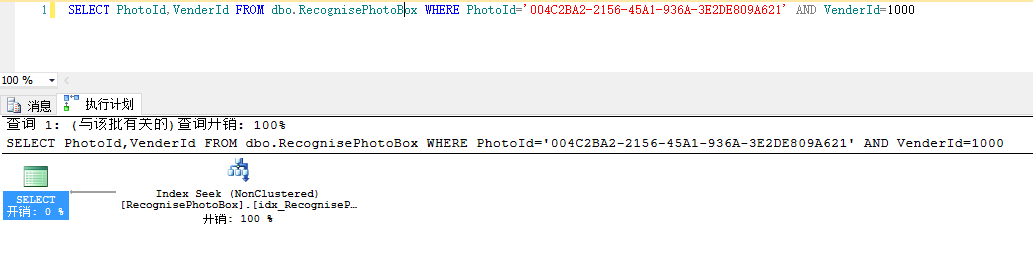
F、书签查询
如下SkuCode没有在非聚集索引中,先会去non-Clustered Index查找一次,然后去Lookup前面查找结果对应的数据表记录。

书签查询可通过Include索引(在索引中包括其它要查找的字段)等进行优化
CREATE NONCLUSTERED INDEX [nci_RecognisePhotoBox_PhotoId_VenderId] ON [dbo].[RecognisePhotoBox] ([PhotoId], [VenderId]) INCLUDE(SkuCode)
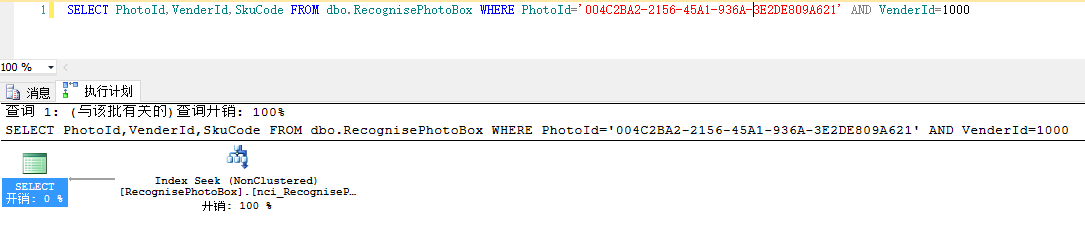
注意:执行计划里用来估计的信息来源于“数据库统计信息”,如 estimated number of rows
4、索引的重要性
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。索引分为聚集索引与非聚集索引,聚集索引表示表中存储的数据按照索引的顺序存储,非聚集索引表示数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置。
(1)索引优点
A、通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
B、可以大大加快 数据的检索速度,这也是创建索引的最主要的原因。
C、可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
D、在使用分组和排序 子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
E、通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
(2)索引缺点
A、创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
B、索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
C、当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
(3)查询索引的层级结构及占用空间了解索引
--查询索引信息
Select id.name,p.index_level,p.page_count,p.index_id, avg_record_size_in_bytes,max_record_size_in_bytes,min_record_size_in_bytes
from sys.dm_db_index_physical_stats(DB_ID('EXEU_TEST_MARK'),Object_id('RecognisePhotoBox'),null,null,'Detailed') as p
Inner Join sys.indexes as id
On p.index_id = id.index_id
And p.object_id = id.object_id
And p.index_id > 1

其中Index_Level为0的表示索引的叶级,为1、2的表示索引的非叶级
5、复杂存储过程的优化
(1)找到生成的执行计划
SELECT OBJECT_NAME(dm_exec_query_plan.objectid),UseCounts, Cacheobjtype, Objtype, TEXT, query_plan FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle) CROSS APPLY sys.dm_exec_query_plan(plan_handle) WHERE objtype='Proc' AND OBJECT_NAME(dm_exec_query_plan.objectid)='pr_createRecogniseCheckBill'

右击query_plan的值另存为,文件的后缀填写“.sqlplan”,保存先用记事本或其它编辑工具打开增加“XML声明”

然后双击在SqlServer打开就可看到执行计划图了
(2) 找到开销大的查询
此处大数据量的临时表走了表扫描
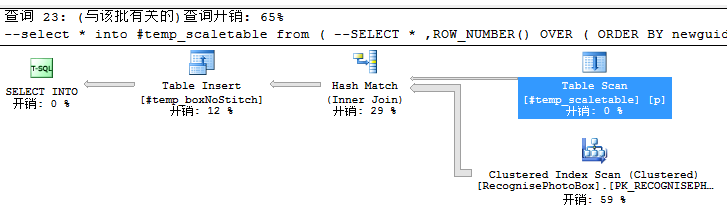
需要给临时表创建索引
CREATE INDEX tidx_1 ON #temp_boxNoStitch(PhotoId) CREATE INDEX tidx_2 ON #temp_scaletable(PhotoId) INCLUDE(rowno,IsStitch)
6、大数据量优化的注意事项
(1)sp_executesql的效率非常低,用exec替换sp_executesql
(2)需在上下文多次使用的大数据关联表结果,采用临时表保存,并根据查询条件对临时表建索引
(3)建索引时需要去掉冗余度太高的字段当索引,可放到索引包含列include里
参考:
【MySQL】SQL执行计划分析
https://blog.csdn.net/da_guo_li/article/details/79008016
SQL Server执行计划详细介绍(一)
https://cloud.tencent.com/developer/news/254038
SQLSERVER编译与重编译
https://www.cnblogs.com/lyhabc/archive/2013/01/17/2865290.html
SQL查询性能优化----解决书签查找
https://www.2cto.com/database/201208/146201.html
数据库索引的作用优点和缺点
https://blog.csdn.net/u013310119/article/details/52527632
对SQL Server索引包含列(Include)的一点认识
https://blog.csdn.net/zhengldg/article/details/9128723
如何获得查询的执行计划?(一)
http://bbs.51cto.com/thread-1317501-1.html
sys.dm_exec_query_plan (Transact-SQL)