1 搭建scrapy项目
# 安装scrpay框架
(base) C:\Users\He>conda install scrapy
安装好之后,我们就可以通过scrapy的相关命令创建项目了。
第1步:命令行创建项目
# startproject命令:创建scrapy项目lianjiaSpider D:\PycharmProjects\python-course\python爬虫\链家租房数据教程>scrapy startproject lianjiaSpider
第2步:创建爬虫
切换到目录lianjiaSpider,执行如下命令:
cd lianjiaSpider # genspider命令,创建scrapy爬虫lianjia.py,指定一个要爬取的域https://www.lianjia.com/city scrapy genspider lianjia https://www.lianjia.com/city
第3步:通过pycharm导入项目
导入项目,因为启动爬虫程序也在命令行操作,比较麻烦,我们在lianjiaSpider目录下新建main.py,代码如下,实现了在运行main.py即可运行该scrapy爬虫。
#爬虫启动 if __name__ == '__main__': from scrapy import cmdline args = "scrapy crawl lianjia".split() cmdline.execute(args)
整体目录结构如下:
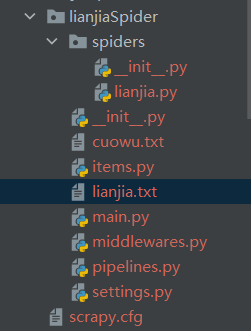
lianjiaSpider:项目名
lianjia.py:上述第2步创建的爬虫文件: --必须
items.py:容器对象,类似于domain对象,保存爬取到的数据 --必须
pipelines.py:处理spaiter提取出来的items,然后持久化数据到文件或数据库 --必须
settings.py:用户自定义相关设置
main.py:自己添加的文件,方便运行爬虫文件
middlewares.py:可以自定义代码,实现爬虫自动更换User-Agent,IP等功能
2 scrapy项目实战
本案例实现lianjia网站的几大城市的租房信息的爬取:
需求分析:
1:每个城市的平均租房价格(每个城市分组)
2:租房最高的前五个小区(根据每个城市分组)
3:合租、整租数量统计(根据每个城市分组)
4:不同房型的出租均价、数量(根据每个城市分组)
以https://cd.lianjia.com/zufang/pg100/#contentList为例:
分析:需要提取网页的如下6个字段: 城市名、居住类型(整租、合租)、区(比如青阳)、地址(详细小区)、房子类型(几室几厅)、价格(标价)
我们先爬取单条数据,再扩展到爬取所有数据
项目1:单页面数据爬取
items.py
import scrapy # LianjiaspiderItem 用于封装解析的数据 class LianjiaspiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() juzhutype = scrapy.Field() area = scrapy.Field() address = scrapy.Field() fangzitype = scrapy.Field() rent = scrapy.Field() city = scrapy.Field()
lianjia.py
import scrapy from scrapy.http import Request import re from python爬虫.链家租房数据教程.lianjiaSpider.lianjiaSpider.items import LianjiaspiderItem class LianjiaSpider(scrapy.Spider): name = 'lianjia' allowed_domains = ['https://www.lianjia.com/city'] # 还有其它的域,也可以添加到这里 start_urls = ['https://www.lianjia.com/city/'] # 爬虫的起始地址 ''' 请求http://www.lianjia.com/city 后调用parse方法。但是这里不需要处理初始链接,直接用来拼接指定链接 ''' # 解析内容、获取下一个请求url,这里其实地址 start_urls 的内容不需要解析,因此我们直接请求想要内容的地址 # 请求后,回调自定义函数myparse def parse(self,response): url = 'https://cd.lianjia.com/zufang/pg100/#contentList' yield Request(url=url,callback=self.myparse,dont_filter=True) # 解析每一个页面的数据7个字段 def myparse(self,response): try: # 在页面中获取城市 city = response.xpath('/html').re(';city=(.+)">')[0] print('城市aaaa='+city) ## pass # 找到当前页的数据 # 写(//div[@class="content__list"]/div')拿不到数据 data_list = response.xpath('/html/body/div[3]/div[1]/div[5]/div[1]/div[1]/div') for data in data_list: # 获取租房的介绍 # 只能抽取第一个item的,因此每个item前两个字段都是一样的结果 # title = data.xpath('//*[@id="content"]/div[1]/div[1]/div[1]/div/p[1]/a/text()').extract() [0].strip() title = data.xpath('./div/p[@class="content__list--item-- title"]/a[@class="twoline"]/text()').extract()[0].strip() print('标题aaaa=' + title) # 获取 租房类型 整租或者合租 # 这里使用正则,提取开始的两个字。在介绍,头两个就是租房的类型 juzhutype = re.findall('^(.+)·', title)[0] # 获取地区区域 area = data.xpath('./div/p[@class="content__list--item--des"]/a/text()').extract()[0] # 具体地址 address = '-'.join(data.xpath('./div/p[@class="content__list--item--des"]/a/text()').extract()) # 房子的类型 比如一室一厅 fangzitype = data.xpath('./div/p[@class="content__list--item--des"]/text()').extract()[-2].strip() # 租金 rent = data.xpath('./div/span/em/text()').extract()[0] # 封装成LianjiaItem容器,交给管道处理 yield LianjiaspiderItem(title=title, juzhutype=juzhutype, area=area, address=address, fangzitype=fangzitype,rent=rent, city=city) except: print('错误数据') # 如果有错误数据,就写1 在cuowu.text文件中 统计数量 with open('cuowu.txt', 'a', encoding='utf8') as f: f.write('1\n')
pipelines.py
import pandas as pd from sqlalchemy import create_engine class LianjiaspiderPipeline(object): # 创建链接mysql数据库的引擎 def __init__(self): self.engine = create_engine('mysql+pymysql://root:admin@127.0.0.1:3306/pythondb?charset=utf8') # 每次接收到一个item,然后对这个item进行处理 def process_item(self, item, spider): # 存储方法1、从item中取出数据,拼接成字符串,写入lianjia.txt # --测试通过,会在项目根目录生成lianjia.txt 并写入数据 # title = item['title'] # juzhutype = item['juzhutype'] # area = item['area'] # address = item['address'] # fangzitype = item['fangzitype'] # rent = item['rent'] # city = item['city'] # print("++++++++++++++++++++++++++++++++++++=") # with open('lianjia.txt', 'a', encoding='utf8') as f: # mystr = '{}|{}|{}|{}|{}|{}|{}\n'.format(title, juzhutype, area, address, fangzitype, rent, city) # f.write(mystr) # 存储方法2、存入mysql数据库 cc =dict(item) data = pd.DataFrame(dict(item),index=[0]) data.to_sql('lianjia',self.engine,if_exists='append',index=False) return item
settings.py
BOT_NAME = 'lianjiaSpider' SPIDER_MODULES = ['lianjiaSpider.spiders'] NEWSPIDER_MODULE = 'lianjiaSpider.spiders' #设置自己的管道LianjiaspiderPipeline及顺序 ITEM_PIPELINES = { 'lianjiaSpider.pipelines.LianjiaspiderPipeline':300, } ROBOTSTXT_OBEY = False #不遵守网站规则 RETRY_ENABLED = False #禁止重试 DOWNLOAD_TIMEOUT = 30 #设置下载超时 COOKIES_ENABLED = False #禁止cookeys DOWMLOAD_DELY= 3 #设置下载延迟 REACTOR_THREADPOOL_MAXSIZE = 10 #设置线程池
middlewares.py:该项目中,该文件使用默认即可。
运行爬虫
根据pipelines中持久化数据方式的不同
方法1:持久化到txt文件中:

方法2:持久化数据到mysql中 首先需要创建数据库pythondb,然后创建表lianjia
# sql代码 create table lianjia( title VARCHAR(255), juzhutype VARCHAR(255), area VARCHAR(255), address VARCHAR(255), fangzitype VARCHAR(255), rent INT(11), city VARCHAR(100) );
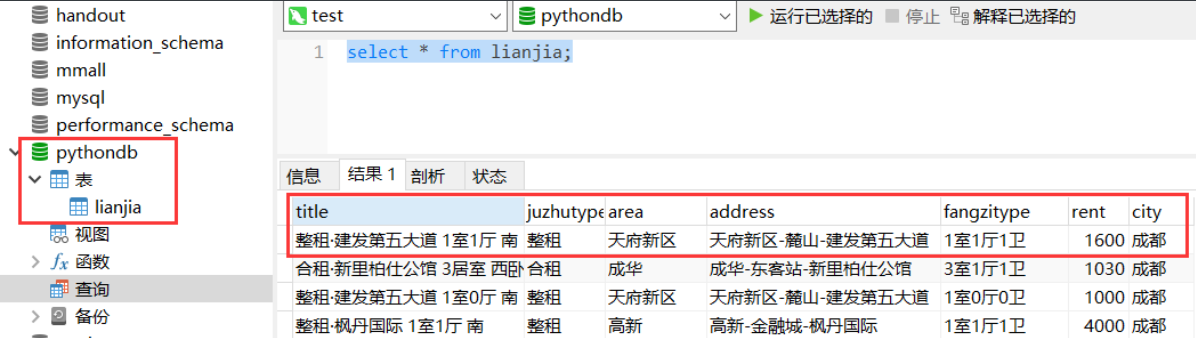
到此,用scrapy框架爬取链家租房数据的“单个页面”就调通了。
项目2:所有数据爬取
数据分析,往往需要爬取很多页面的数据,在大量的数据背后,找出规律。因此,我们把爬取单个页面的代码,修改成爬取所有租房数据的代码,其实也很简单,在“单页面数据爬取”项目中,修改一下lianjia.py文件即可实现。
lianjia.py
仅仅修改了parse函数,把原来的单个url,换成了拼接成的500个url。
import scrapy from scrapy.http import Request import re from python爬虫.链家租房数据教程.lianjiaSpider.lianjiaSpider.items import LianjiaspiderItem class LianjiaSpider(scrapy.Spider): name = 'lianjia' allowed_domains = ['https://www.lianjia.com/city'] # 还有其它的域,也可以添加到这里 start_urls = ['https://www.lianjia.com/city/'] # 爬虫的起始地址 ''' 请求http://www.lianjia.com/city 后调用parse方法。但是这里不需要处理初始链接,直接用来拼接指定链接。 parse方法用于解析内容、获取下一个请求url,这里其实地址 start_urls 的内容不需要解析,因此我们直接请求想要内容的地址 请求后,回调自定义函数myparse ''' def parse(self,response): # 成都、重庆、背景、上海、贵阳五个城市的域名 city_urls = ['https://cd.lianjia.com/', 'https://cq.lianjia.com/','https://bj.lianjia.com/', 'https://sh.lianjia.com/', 'https://gy.lianjia.com/'] print(response) # url是城市链接 # page是页数,这几个城市最大页数都是100 for url in city_urls: for page in range(1,101): # 拼接出类似 https://bj.lianjia.com/zufang/pg1/#contentList 的链接 # 每个城市100页,5个城市,大概能拼接出500个租房信息页面的url myurl = url+'zufang/pg%s/#contentList' % page ''' 把url给引擎,让它去调度并下载。 callback 是指定下载完成后调用的方法,这里是myparse dont_filter 禁止scrapy自带的url过滤,这里我们不需要过滤,因为这里的url是不会重复的 ''' yield Request(url=url, callback=self.myparse, dont_filter=True) # print("进来了吗") # pass # print(response) # url = 'https://cd.lianjia.com/zufang/pg100/#contentList' # yield Request(url=url,callback=self.myparse,dont_filter=True) # # 解析每一个页面的数据 def myparse(self,response): try: # 在页面中获取城市 city = response.xpath('/html').re(';city=(.+)">')[0] print('城市aaaa='+city) ## pass # 找到当前页的数据 # 写(//div[@class="content__list"]/div')拿不到数据 data_list = response.xpath('/html/body/div[3]/div[1]/div[5]/div[1]/div[1]/div') for data in data_list: # 获取租房的介绍 # 只能抽取第一个item的,因此每个item前两个字段都是一样的结果 # title = data.xpath('//*[@id="content"]/div[1]/div[1]/div[1]/div/p[1]/a/text()').extract() [0].strip() title = data.xpath('./div/p[@class="content__list--item-- title"]/a[@class="twoline"]/text()').extract()[0].strip() print('标题aaaa=' + title) # 获取 租房类型 整租或者合租 # 这里使用正则,提取开始的两个字。在介绍,头两个就是租房的类型 juzhutype = re.findall('^(.+)·', title)[0] # 获取地区区域 area = data.xpath('./div/p[@class="content__list--item--des"]/a/text()').extract()[0] # 具体地址 address = '-'.join(data.xpath('./div/p[@class="content__list--item--des"]/a/text()').extract()) # 房子的类型 比如一室一厅 fangzitype = data.xpath('./div/p[@class="content__list--item--des"]/text()').extract()[-2].strip() # 租金 rent = data.xpath('./div/span/em/text()').extract()[0] # 封装成LianjiaItem容器,交给管道处理 yield LianjiaspiderItem(title=title, juzhutype=juzhutype, area=area, address=address, fangzitype=fangzitype,rent=rent, city=city) except: print('错误数据') # 如果有错误数据,就写1 在cuowu.text文件中 统计数量 with open('cuowu.txt', 'a', encoding='utf8') as f: f.write('1\n')
运行爬虫
根据pipelines中持久化数据方式的不同
方法1:持久化到txt文件中:

方法2:持久化数据到mysql中 首先需要创建数据库pythondb,然后创建表lianjia
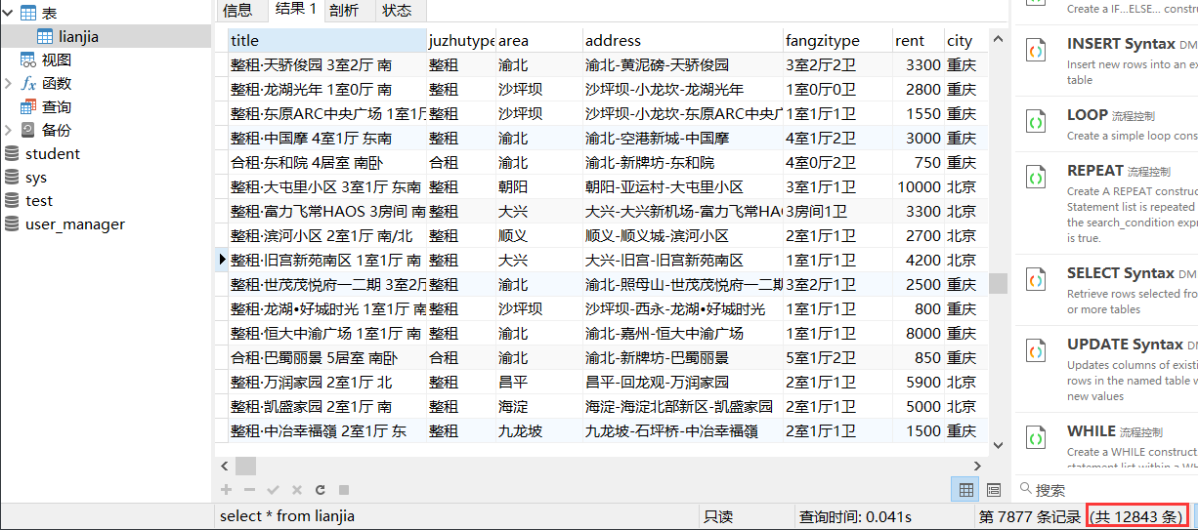
一共12843条数据存储mysql,存入文件是13769条。 为什么记录不一样: 可能是两个原因: 1:本身网页数据在变动,存在个别差异是正常现象; 2:在爬取和存储数据到mysql的过程中,电脑没电了,重新开机后爬虫继续爬取,导致中间部分数据丢失。到此,scrapy爬取数据项目就结束了。
展望:
为了防止爬虫被网站的反爬规则识别,可以通过如下方式加强爬虫:
1、配置动态User-Agent --可在middlewares.py中配置
2、使用ip地址池 --可在middlewares.py中配置
3、禁用cookie --可在settings.py中配置
4、设置延迟下载 --可在settings.py中配置
5、使用Crawlera,使得项目中的所有request都通过Crawlera发出
备注
调试代码
1、在需要查看的参数左边,对应的行号前点击一下,出现一个红色的原点
2、然后打开main.py,右键--》debug main即可以debug模式运行代码
3、单机左下角的step into mycode,便可以挨行运行代码
报错
1、raise ValueError("If using all scalar values, you must pass an index")
出错语句: data = pd.DataFrame(dict(item)
解决: data = pd.DataFrame(dict(item),index=[0]) # 加上index=[0]即可