环境
VM16:https://www.vmware.com/go/getworkstation-linux
激活码:ZF3R0-FHED2-M80TY-8QYGC-NPKYFYF390-0HF8P-M81RQ-2DXQE-M2UT6ZF71R-DMX85-08DQY-8YMNC-PPHV8 (仅限个人学习使用)
CentOS-7-x86_64-DVD-2009.iso:http://mirrors.tuna.tsinghua.edu.cn/centos/7.9.2009/isos/x86_64/
hadoop3.2.2:https://archive.apache.org/dist/hadoop/common/
一、虚拟机安装
1:安装虚拟机 2:虚拟网络编辑器 NAT模式==》设置网关和ip NAT设置:设置网关
比如:
网关:192.168.56.10
子网:192.168.56.0 子网掩码:255.255.255.0
3:安装linux 创建新的虚拟机==》典型安装==》选择linux的iso文件 ==》master(安装位置、20G) ==》一直下一步(system installAtion..) ==》设置root:root password:admin
特别注意:
一般不需要安装GUI,占较大资源:
VM12可以按照上述方式完成无GUI的安装。
VM16按照上诉方式的话,显示简易安装(带GUI)。VM16只能选择稍后安装系统,然后再自己选择最小系统,完成无GUI的安装。
4:右键master--》管理==》克隆(完整克隆)==》取名slave1 和 slave2
二、虚拟机配置网络
5.0 Master和slave的网络配置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static IPADDR=192.168.56.110 NETMASK=255.255.255.0 GATEWAY=192.168.56.10 ONBOOT=yes
slvav1 和slave2分别是111 和112
5.1 设置虚拟机DNS
vi /etc/NetworkManager/NetworkManager.conf
添加一行内容dns=none
然后重启网络管理: systemctl restart NetworkManager.service
修改域名解析配置文件
vi /etc/resolv.conf nameserver 192.168.56.10
最后重启网络service network restart
ping www.baidu.com可ping通即配置成功。
安装xshell和xftp并连接linux,方便操作。
5.2:关闭防火墙(每个节点都执行) 查看状态: systemctl status firewalld.service
关闭防火墙:systemctl stop firewalld.service
防止下次重启防火墙自动启动 :systemctl disable firewalld.service
6:设置主机名 vi /etc/sysconfig/network
#Created by anaconda
NETWORKING=yes
HOSTNAME=master
防止重启又恢复回去
vi /etc/hostname
master
#同理设置slave1和slave2
vi /etc/sysconfig/network
#Created by anaconda
NETWORKING=yes
HOSTNAME=slave1
防止重启又恢复回去 vi /etc/hostname
slave1
vi /etc/sysconfig/network
#Created by anaconda
NETWORKING=yes
HOSTNAME=slave2
防止重启又恢复回去 vi /etc/hostname
slave2
7:设置主机名与ip的映射 为了用计算机名访问网络
注意:已有的代码要保留
vi /etc/hosts
192.168.56.110 master
192.168.56.111 slave1
192.168.56.112 slave2
(三台机器都分别设置)
三、安装JDK1.8
8:安装jdk #上传文件 用xftp上传jdk-8u162-linux-x64.tar.gz 文件到/usr/local/java/
#解压文件 cd /usr/local/java/ tar -zxvf jdk-8u162-linux-x64.tar.gz
#设置环境变量 vi /root/.bash_profile
加入下面内容
export JAVA_HOME=/usr/local/java/jdk1.8.0_162
export PATH=$JAVA_HOME/bin:$PATH
#使设置立即生效 source /root/.bash_profile
#验证是否成功 java -version
四、免密钥登录配置
9:免密钥登录配置 #生成密钥(每台都执行) ssh-keygen -t rsa
#发送到每台服务器(每台都执行-一行行执行)
ssh-copy-id -i ~/.ssh/id_rsa.pub root@master
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave2
#测试 ssh master ssh slave1 ssh slave2
#查看生成的文件 cat ~/.ssh/ authorized_keys id_rsa id_rsa.pub known_hosts
五、hadoop3.2.2伪分布式安装
10:hadoop安装
#通常在 Master 节点上完成安装和配置后,然后将安装目录复制到其他节点即可
#1:上传文件 用xftp上传hadoop-3.2.2.tar.gz 文件到/opt/目录中
#2:解压文件 #主机进入/opt目录 tar -zxvf hadoop-3.2.2.tar.gz
#将“hadoop-3.2.2.tar.gz”文件夹名称修改为“hadoop”此即 Hadoop 安装目录。
11:配置hadoop-env.sh 【与2.x不同点1】 vi /opt/hadoop/etc/hadoop/hadoop-env.sh 找到“export JAVA_HOME”这行,
export JAVA_HOME=/opt/jdk1.8.0_162/
##添加部分--与2.x配置不同点1
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
12:配置 core-site.xml vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>
13:配置是 hdfs-site.xml vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
14:配置yarn-site.xml vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value> ##浏览器访问yarn的地址
</property>
15:配置/mapred-site.xml vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
##【与2.x不同点2】
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
16:配置workers---------------【与2.x不同点3】 vi /opt/hadoop/etc/hadoop
slave1 slave2
19:复制master上的hadoop到slave0和1节点
scp -r /opt/hadoop root@slave1:/opt scp -r /opt/hadoop root@slave2:/opt
20:配置hadoop(三个节点都要配置) vi ~/.bash_profile #追加 #HADOOP
export HADOOP_HOME=/opt/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#使配置生效
source ~/.bash_profile
21:创建 Hadoop 数据目录(三个都创建)
mkdir /opt/hadoop/hadoopdata #也可以用xftp可视化创建
22:格式化文件系统(该操作只需要在 Master 节点上进行)
hadoop namenode -format
23:启动和关闭hadoop
cd $HADOOP_HOME cd sbin ls ./start-all.sh //启动程序 #This script is Deprecated. #Instead use start-dfs.sh and start-yarn.sh #停止 ./stop-all.sh #Instead use stop-dfs.sh and stop-yarn.sh #验证 在三个节点输入指令: jps
#在web监控hdfs http://192.168.56.110:9870 (hadoop3.x) 【与2.x不同点4】 http://192.168.56.110:50070 (hadoop2.x)
#在web监控yarn http://192.168.56.110:18088 ((hadoop3.x)) 因为在haoop中配置的18088,因此不变的
[为什么http://master:18088 不行? ------》这个问题在后面是可以使用的]
六、测试集群
24:在hadoop集群中运行程序 cd /opt/hadoop/share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-3.2.2.jar pi 2 3
显示结果:
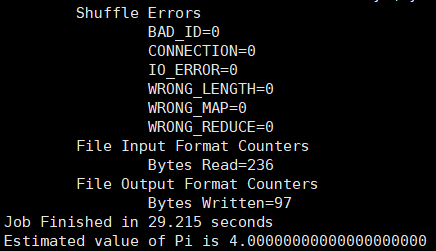
到此,hadoop集群配置完成。
参考资源:
1:https://www.jianshu.com/p/3182aaff918d
2:https://blog.csdn.net/qq_39314099/article/details/103681298
4:https://www.cnblogs.com/yuqiliu/p/14380367.html 【没测试】
================================================================
其他备注:---这是之前2.7.5出现的问题汇总,与3.2.2配置无关
1:修改了主机之后(两个文件) 可能没有生效,需要重启机器
2:运行pi案例,不能输出,且输出192.168.56.110 to 0.0.0.0:22不能连接
#关闭安全模式 #bin/hdfs dfsadmin -safemode leave
#启动historyserver mr-jobhistory-daemon.sh start historyserver
3:history可以查看使用过的命令
问题解决教程连接
1:java.net.ConnectException: Call To Master/127.0.0.1:9000 failed on connection exception http://blog.sina.com.cn/s/blog_4b1452dd0102wxe8.html
2:hadoop配置启动historyserver https://blog.csdn.net/tszxlzc/article/details/74838674
--geiliHe 2021.5.25晚