一、Uclamp简介
1. PELT负载跟踪算法得到的 task util 与用户空间的期望有时候会出现分歧,比如对于控制线程或UI线程,PELT计算出的util可能较小,认为是“小”task,而用户空间则希望调度器将控制线程或UI线程看作“大”task,以便被调度到高性能核运行在高频点上使任务更快更及时的完成处理。同样地,对于某些长时间运行的后台task,eg:日志记录,PELT计算出的task util 可能很大,认为是“大”task,但是对于用户空间来说,此类task对于完成时间要求并不高,并不希望被当作“大”task,以利于节省系统功耗和缓解发热。
2. 关于任务的性质、性能/功耗需求用户空间拥有足够的信息可以识别,那么若将用户空间关于任务的信息传递给内核任务调度器,则能够更好的帮助调度器进行任务的调度。Utilization Clamping(uclamp)便是这样一种机制。
3. uclamp提供了一种用户空间对于task util进行限制的机制,通过该机制用户空间可以将task util钳制在[util_min, util_max]范围内,而cpu util则由处于其运行队列上的task的uclamp值决定。通过将util_min设置为一个较大值,使得一个task看起来像一个“大”任务,使CPU运行在高性能状态,加速任务的处理,提升系统的性能表现;对于一些后台任务,通过将util_max设置为较小值,使其看起来像一个“小”任务,使CPU运行在高能效状态,以节省系统的功耗。
4. 在 CPU Utilization 和 Task Utilization 两个维度的跟踪信号。CPU Utilization 用于指示CPU的繁忙程度,内核调度器使用此信号驱动CPU频率的调整(schedutil governor生效时);Task Utilization 用于指示一个task对CPU的使用量,表明一个task是“大”还是“小”,此信号可以辅助内核调度器选核。
5. Android Kernel 5.4以前,cgroup中存在一个 schedtune,也提供了与uclamp类似的功能。后来 uclamp 作为 schedtune 的替代方案合入Linux内核主线。下面是二者相关feature对比:
| Features | Schedtune | Uclamp |
| 支持的主线版本 | Before 5.4 | 5.4 and Later |
| APIs | 仅支持Cgroup v1,有限的cgroup |
支持Cgroup v1 v2,不限cgroup数量 支持基于proc的system-wide的API 支持基于syscall的per-task的API |
| boost实现 |
基于SPC算法,即 util+(max-util)*boost% 而且boost只能为正值,只能boost不能限制 |
uclamp到基于[min, max],可boost可限制 |
| 低延迟支持 | perfer-idle feature | latency_sensitive feature |
| RT任务支持 | 不支持 | 支持 |
二、Uclamp软件架构
用户空间进程管理服务将相关 task 的 util clamp 值通过适当接口传递到内核空间,调度器基于用户空间提供的信息通过 schedutil 驱动频率的调整,也可以基于该信息为task选择适当的core。
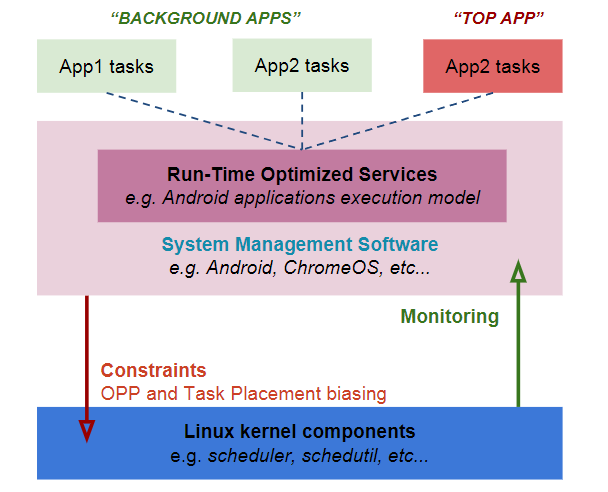
三、Uclamp软件实现

四、用到的桶算法
对于一个cpu来说,其运行队列rq上可能同时存在几个task(running/runnable),那么如何计算 cpu 的 util_min 和 util_max 则非常关键。uclmap 使用桶化算法实现这种计算。
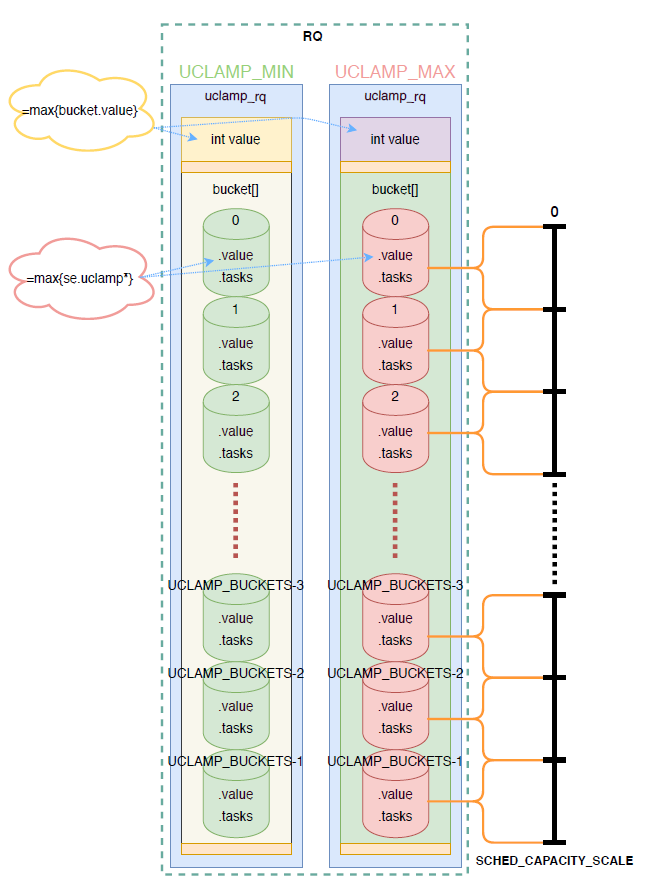
将 [0, SCHED_CAPACITY_SCALE] 划分为 UCLAMP_BUCKETS 个区间,区间个数可以通过 CONFIG_UCLAMP_BUCKETS_COUNT 进行配置,每个区间看作一个桶,使用 uclamp_bucket 结构描述。
struct uclamp_bucket { //bucket::value始终是此bucket中所有task 生效clamp(就是enqueue到rq上的)的最大值。 unsigned long value : bits_per(SCHED_CAPACITY_SCALE); //11 //有多少个task位于桶内 unsigned long tasks : BITS_PER_LONG - bits_per(SCHED_CAPACITY_SCALE);//64-11=53 };
存在 UCLAMP_MIN、UCLAMP_MAX 两个桶集合,rq上所有 task 的 uclamp_min 值放入 UCLAMP_MIN 桶集合、uclam_max 值放入 UCLAMP_MAX 桶集合。多个任务位于同一个桶内,桶的值按最大值聚合原则,即由uclamp值最大的 task 决定。桶与桶之间同样按最大值聚合原则,即 cpu 的 uclamp 值由 value 值最大的桶决定。这样可以保证高性能任务其性能需求始终能够得到满足。
五、用户空间接口
1. 基于 procfs 的 system-wide API
/proc/sys/kernel/sched_util_clamp_min /proc/sys/kernel/sched_util_clamp_max /proc/sys/kernel/sched_util_clamp_min_rt_default
取值范围 [0, SCHED_CAPACITY_SCALE],用于限制 per-group 值和 per-task 设置的值,使之不超过全局设置。默认前两个文件都是 1024,都是1024就表示不限制,因为原生的uclamp是单向往低处拉的(但MTK在cgroup层级改了这个逻辑,使util在cgroup的限制层级中落在区间内),比如 uclamp[400 800],当util是900的时候,clamp后是800,当util是300的时候,clamp后还是300,而不会限制在400-800之间。MTK和Qcom的BSP都是,第三个文件是0(5.4中还没有,5.10中有),对RT任务只有一个 min_clamp 的限制。
这三个文件对应同一个处理函数:
int sysctl_sched_uclamp_handler(struct ctl_table *table, int write, void *buffer, size_t *lenp, loff_t *ppos) //sched/core.c { ... //如果修改了 sched_util_clamp_min 文件 if (old_min != sysctl_sched_uclamp_util_min) { uclamp_se_set(&uclamp_default[UCLAMP_MIN], sysctl_sched_uclamp_util_min, false); //此设置路径userdefined传false update_root_tg = true; } //如果修改了 sched_util_clamp_max 文件 if (old_max != sysctl_sched_uclamp_util_max) { uclamp_se_set(&uclamp_default[UCLAMP_MAX], sysctl_sched_uclamp_util_max, false); //此设置路径userdefined传false update_root_tg = true; } //若是修改了上面两个文件中的任何一个文件就执行 if (update_root_tg) { //在 enqueue/dequeue 时用于计算CPU的clamp值时进行判断 static_branch_enable(&sched_uclamp_used); //设置到全局变量 root_task_group :: uclamp_req 成员中 uclamp_update_root_tg(); } //如果修改了 sched_util_clamp_min_rt_default 文件 if (old_min_rt != sysctl_sched_uclamp_util_min_rt_default) { static_branch_enable(&sched_uclamp_used); //设置到系统中所有RT任务的 p->uclamp_req[UCLAMP_MIN] 中 uclamp_sync_util_min_rt_default(); } ... }
通过 sched_util_clamp_min/sched_util_clamp_max 文件设置的值会设置到全局变量 uclamp_default[] 中,同时还会设置到全局变量 root_task_group::uclamp_req[]中。
通过 sched_util_clamp_min_rt_default 文件设置的值会设置到所有RT任务的 p->uclamp_req[UCLAMP_MIN] 中,它会在RT任务选核中起作用。
2. 基于 cgroup 的 per-group API
/dev/cpuctl/<group>/cpu.uclamp.min /dev/cpuctl/<group>/cpu.uclamp.max /dev/cpuctl/<group>/cpu.uclamp.latency_sensitive
基于 cgroup 实现的 per-group 值,该设置值会限制组内各个任务的 per-task 的值。cpu.uclamp.min/cpu.uclamp.max 取值范围 0.00 - 100.00,格式为两位小数精度的百分比值,比如设置echo 40 > min 就表示clamp min为 40% * 1024 = 409.6,后者还可以直接echo max,表示100.00。cpu.uclamp.latency_sensitive 只能设置0或1,在CFS选核中起作用,见下文。
注意根目录 /dev/cpuctl/ 下是没有uclamp相关接口文件的,应该是放在上面 profs 文件接口给设置了,见对 root_task_group 的设置。
(1) cpu.uclamp.min/cpu.uclamp.max 的响应接口:
static struct cftype cpu_legacy_files[] = { //sched/core.c ... { .name = "uclamp.min", .flags = CFTYPE_NOT_ON_ROOT, .seq_show = cpu_uclamp_min_show, .write = cpu_uclamp_min_write, }, { .name = "uclamp.max", .flags = CFTYPE_NOT_ON_ROOT, .seq_show = cpu_uclamp_max_show, .write = cpu_uclamp_max_write, }, { .name = "uclamp.latency_sensitive", .flags = CFTYPE_NOT_ON_ROOT, .read_u64 = cpu_uclamp_ls_read_u64, .write_u64 = cpu_uclamp_ls_write_u64, }, ... }
先看write接口:
//cpu.uclamp.min/cpu.uclamp.max 写时对应函数,clamp_id 分别传参 UCLAMP_MIN/UCLAMP_MAX static ssize_t cpu_uclamp_write(struct kernfs_open_file *of, char *buf, size_t nbytes, loff_t off, enum uclamp_id clamp_id) //sched/core.c { struct uclamp_request req; struct task_group *tg; req = capacity_from_percent(buf); if (req.ret) return req.ret; //同样使能static branch static_branch_enable(&sched_uclamp_used); mutex_lock(&uclamp_mutex); rcu_read_lock(); tg = css_tg(of_css(of)); if (tg->uclamp_req[clamp_id].value != req.util) //设置到 tg->uclamp_req[]中,此设置路径userdefined传false uclamp_se_set(&tg->uclamp_req[clamp_id], req.util, false); /* 由于不可恢复的转换舍入,我们会跟踪确切的请求值 */ tg->uclamp_pct[clamp_id] = req.percent; //注意是percent值 /* Update effective clamps to track the most restrictive value */ cpu_util_update_eff(of_css(of)); rcu_read_unlock(); mutex_unlock(&uclamp_mutex); return nbytes; } static inline void uclamp_se_set(struct uclamp_se *uc_se, unsigned int value, bool user_defined) //sched/core.c { uc_se->value = value; uc_se->bucket_id = uclamp_bucket_id(value); uc_se->user_defined = user_defined; } static inline unsigned int uclamp_bucket_id(unsigned int clamp_value) { /* 默认分20个桶,将1024均分到[0, 19], 两个宏分别为 51, 20 */ return min_t(unsigned int, clamp_value / UCLAMP_BUCKET_DELTA, UCLAMP_BUCKETS - 1); } cpu.uclamp.min/cpu.uclamp.max 文件 cat 时,若 tg->uclamp_req[clamp_id].value == SCHED_CAPACITY_SCALE,打印“max”,否则打印的是 task_group::uclamp_pct[clamp_id] 这 个是个百分比值。 static inline void cpu_uclamp_print(struct seq_file *sf, enum uclamp_id clamp_id) //sched/core.c { struct task_group *tg; u64 util_clamp; u64 percent; u32 rem; rcu_read_lock(); tg = css_tg(seq_css(sf)); util_clamp = tg->uclamp_req[clamp_id].value; rcu_read_unlock(); if (util_clamp == SCHED_CAPACITY_SCALE) { seq_puts(sf, "max\n"); return; } percent = tg->uclamp_pct[clamp_id]; percent = div_u64_rem(percent, POW10(UCLAMP_PERCENT_SHIFT), &rem); seq_printf(sf, "%llu.%0*u\n", percent, UCLAMP_PERCENT_SHIFT, rem); }
需要使能 CONFIG_UCLAMP_TASK_GROUP 才有效。
(2) cpu.uclamp.latency_sensitive 响应接口
static int cpu_uclamp_ls_write_u64(struct cgroup_subsys_state *css, struct cftype *cftype, u64 ls) //sched/core.c { struct task_group *tg; if (ls > 1) return -EINVAL; tg = css_tg(css); tg->latency_sensitive = (unsigned int) ls; return 0; } static u64 cpu_uclamp_ls_read_u64(struct cgroup_subsys_state *css, struct cftype *cft) //sched/core.c { struct task_group *tg = css_tg(css); return (u64) tg->latency_sensitive; }
直接赋值给 task_group::latency_sensitive,此成员的使用位置:
位置1:
在为 CFS 任务选核时,在 find_energy_efficient_cpu() 中若判断任务所在组设置了 latency_sensitive 属性,趋向于选择idle cpu,若是没有idle cpu可选,就算空余算力最大的CPU;若是没有设置 latency_sensitive 属性,那就趋向于选择最节能的CPU。
位置2:
MTK 在 find_energy_efficient_cpu() 中注册了 hook,函数为 mtk_find_energy_efficient_cpu() 若是 hook 中选到核了,位置1就不再生效了。此 hook 的逻辑为若是 perf_ioctl 没有设置 uclamp_min_ls,那么 latency_sensitive 的取值和原生的一致,否则取值为 p->uclamp_req[UCLAMP_MIN].value > 0 ? 1 : 0,若是判断为 latency_sensitive 的,就优先选择idle 核,若没有 idle 核就依次选最空闲的具有最大算力的核和有最大空余算力的核,判读时考虑了从idle退出的延迟。
仅从cgroup上,目前有MTK只有神经网络相关的binder线程单独创建了一个group,设置了这个 latency_sensitive 属性。
3. 基于 systemcall 的 per-task API
#include <sched.h> int sched_setattr(pid_t pid, struct sched_attr *attr, unsigned int flags); int sched_getattr(pid_t pid, struct sched_attr *attr, unsigned int size, unsigned int flags); //早期内核版本是不支持的,里面没有util成员 struct sched_attr { __u32 size; __u32 sched_policy; __u64 sched_flags; /* SCHED_NORMAL, SCHED_BATCH */ __s32 sched_nice; /* SCHED_FIFO, SCHED_RR */ __u32 sched_priority; /* SCHED_DEADLINE */ __u64 sched_runtime; __u64 sched_deadline; __u64 sched_period; /* Utilization hints 应该是uclamp的设置*/ __u32 sched_util_min; __u32 sched_util_max; };
通过 sched_setattr 系统调用,每个任务都可以自主的设置各自的 uclamp_min 和 uclamp_max,以满足自身的性能/功耗需求,但是该设置值会受制于 cgroup 设置值和系统全局设置的值,取值范围 0 - SCHED_CAPACITY_SCALE。
系统调用响应函数:
SYSCALL_DEFINE3(sched_setattr, pid_t, pid, struct sched_attr __user *, uattr, unsigned int, flags) //kernel/sched/core.c { struct sched_attr attr; struct task_struct *p; int retval; if (!uattr || pid < 0 || flags) //flags只能传0 return -EINVAL; retval = sched_copy_attr(uattr, &attr); if ((int)attr.sched_policy < 0) return -EINVAL; if (attr.sched_flags & SCHED_FLAG_KEEP_POLICY) attr.sched_policy = SETPARAM_POLICY; p = find_process_by_pid(pid); if (likely(p)) { if (attr.sched_flags & SCHED_FLAG_KEEP_PARAMS) get_params(p, &attr); //RT只赋值 sched_priority,CFS只赋值 sched_nice retval = sched_setattr(p, &attr); //这里设置 put_task_struct(p); } return retval; } int sched_setattr(struct task_struct *p, const struct sched_attr *attr) { return __sched_setscheduler(p, attr, true, true); } EXPORT_SYMBOL_GPL(sched_setattr); int sched_setattr_nocheck(struct task_struct *p, const struct sched_attr *attr) { return __sched_setscheduler(p, attr, false, true); } EXPORT_SYMBOL_GPL(sched_setattr_nocheck); static int __sched_setscheduler(struct task_struct *p, const struct sched_attr *attr, bool user, bool pi) //sched/core.c { ... //用户空间设置需要 capable(CAP_SYS_NICE) 权限 if (user && !capable(CAP_SYS_NICE)) { if (fair_policy(policy)) { if (attr->sched_nice < task_nice(p) && !can_nice(p, attr->sched_nice)) return -EPERM; } //检查目标进程是否具有与当前进程的 UID 匹配的 UID /* Can't change other user's priorities: */ if (!check_same_owner(p)) return -EPERM; //此版本内核不支持用户空间 uclamp /* Can't change util-clamps */ if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP) return -EPERM; } //但是内核空间的 uclamp 是支持的 /* Update task specific "requested" clamps */ if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP) { //执行 //这个函数中调用了 static_branch_enable(&sched_uclamp_used); retval = uclamp_validate(p, attr); } //在设置前会先将任务dequeue,设置完后再enqueue __setscheduler(rq, p, attr, pi); //其它属性设置 __setscheduler_uclamp(p, attr); //uclamp位置 }
结论:目前5.10版本的Linux内核还不支持用户空间通过 sched_setattr 系统调用设置 uclamp 属性。但是内核空间的设置是支持的,内核空间使用 sched_setattr_nocheck() 进行设置,最终会设置到 p->uclamp_req[] 中,如何使用参考:
static int sched_uclamp_set(struct task_struct *p, int util_min, int util_max, bool reset) { struct sched_attr attr = {}; attr.sched_policy = -1; attr.sched_flags = SCHED_FLAG_KEEP_ALL | SCHED_FLAG_UTIL_CLAMP | SCHED_FLAG_RESET_ON_FORK; if (reset) { attr.sched_util_min = -1; attr.sched_util_max = -1; } else { attr.sched_util_min = util_min; attr.sched_util_max = util_max; } return sched_setattr_nocheck(p, &attr); }
sched_setattr_nocheck 最终会调用到 __setscheduler_uclamp:
static void __setscheduler_uclamp(struct task_struct *p, const struct sched_attr *attr) { enum uclamp_id clamp_id; //执行reset的设置 for_each_clamp_id(clamp_id) { struct uclamp_se *uc_se = &p->uclamp_req[clamp_id]; unsigned int value; //对MIN或MAX不是reset继续 if (!uclamp_reset(attr, clamp_id, uc_se)) continue; /* * RT by default have a 100% boost value that could be modified at runtime. */ if (unlikely(rt_task(p) && clamp_id == UCLAMP_MIN)) //RT任务reset后uclamp[MIN]取 sched_util_clamp_min_rt_default 的值 value = sysctl_sched_uclamp_util_min_rt_default; else //非RT任务reset到没有clamp的状态,MIN就是0,MAX就是1024 value = uclamp_none(clamp_id); //若是reset的,user_defined 传 false uclamp_se_set(uc_se, value, false); } if (likely(!(attr->sched_flags & SCHED_FLAG_UTIL_CLAMP))) return; //下面是真正的设置,只有内核中per-task的设置user_defined才传true if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP_MIN && attr->sched_util_min != -1) { uclamp_se_set(&p->uclamp_req[UCLAMP_MIN], attr->sched_util_min, true); //没有使用 trace_android_vh_setscheduler_uclamp(p, UCLAMP_MIN, attr->sched_util_min); } if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP_MAX && attr->sched_util_max != -1) { uclamp_se_set(&p->uclamp_req[UCLAMP_MAX], attr->sched_util_max, true); //没有使用 trace_android_vh_setscheduler_uclamp(p, UCLAMP_MAX, attr->sched_util_max); } }
cat /proc/<pid>/sched 可以看 uclamp 值和 effective uclamp 值(就是此时任务在rq上是对其util的限制范围)
# cat /proc/<pid>/sched se.avg.util_avg : 49 //util值 se.avg.util_est.ewma : 42 //util_est值 se.avg.util_est.enqueued : 19 uclamp.min : 163 //取自p->uclamp_req[UCLAMP_MIN].value,是内核接口sched_setattr_nocheck()请求的设置值 uclamp.max : 180 effective uclamp.min : 163 //uclamp_eff_value()返回的值,是受全局和per-cgroup设置值限制后的值 effective uclamp.max : 180
proc_sched_show_task() //debug.c { __PS("uclamp.min", p->uclamp_req[UCLAMP_MIN].value); __PS("uclamp.max", p->uclamp_req[UCLAMP_MAX].value); __PS("effective uclamp.min", uclamp_eff_value(p, UCLAMP_MIN)); //这个是被全局限制的 __PS("effective uclamp.max", uclamp_eff_value(p, UCLAMP_MAX)); }
4. 设置总结
(1) 全局的设置会设置到全局数组 uclamp_default[] 和 全局数组 root_task_group :: uclamp_req[] 里面,user_defined 为fasle; per-cgroup的设置会设置到 task_group::uclamp_req[] 里面,user_defined 为fasle; per-task的设置5.10内核还不支持用户空间对uclamp的设置,内核中的设置会设置到 task_struct::uclamp_req[] 中,user_defined 为true。
(2) 三个设置路径在设置后都执行了 static_branch_enable(&sched_uclamp_used),使用位置是 enqueue_task/enqueue_task 位置,若是三个路径都没有设置过,那么 sched_uclamp_used 就为 False,功能等于没有被启动。
五、相关函数分析
1. 相关数据结构
//per-task: struct uclamp_se { //uclamp_max/min对应的值 unsigned int value : bits_per(SCHED_CAPACITY_SCALE); //11bit //uclamp_max/min对应的值落在那个桶的id unsigned int bucket_id : bits_per(UCLAMP_BUCKETS); //5bit //enqueue此task时写1,dequeue此task时写0,标记此se是否在rq队列上 unsigned int active : 1; //system-wide和per-cgroup的设置为0,内核per-task的设置为1 unsigned int user_defined : 1; }; //per-rq: struct uclamp_rq { unsigned int value; struct uclamp_bucket bucket[UCLAMP_BUCKETS]; //20 }; struct uclamp_bucket { //bucket::value始终是此bucket中所有task 生效clamp(就是enqueue到rq上的)的最大值。 unsigned long value : bits_per(SCHED_CAPACITY_SCALE); //11 //有多少个task位于桶内 unsigned long tasks : BITS_PER_LONG - bits_per(SCHED_CAPACITY_SCALE);//64-11=53 }; struct task_struct { ... /* * 请求的clamp值保存从内核空间 sched_setattr()设置的值, * 目前用户空间的设置还不支持 */ struct uclamp_se uclamp_req[UCLAMP_CNT]; //2 /* * Effective clamp values used for a scheduling entity. * Must be updated with task_rq_lock() held. * * uclamp_rq_inc_id: 中更新,保存的 uclamp_eff_get()的返回值, * 即是受system-wide和per-cgroup uclmap设置对per-task设置值 * MIN/MAX的最大值进行限制后的值。 */ struct uclamp_se uclamp[UCLAMP_CNT]; }; struct task_group { ... /* The two decimal precision [%] value requested from user-space */ unsigned int uclamp_pct[UCLAMP_CNT]; /* Clamp values requested for a task group */ struct uclamp_se uclamp_req[UCLAMP_CNT]; /* Effective clamp values used for a task group */ struct uclamp_se uclamp[UCLAMP_CNT]; /* Latency-sensitive flag used for a task group */ unsigned int latency_sensitive; }; struct rq { ... struct uclamp_rq uclamp[UCLAMP_CNT] ____cacheline_aligned; unsigned int uclamp_flags; #define UCLAMP_FLAG_IDLE 0x01 ... }
2. 对CPU的clamp的设置位置:
enqueue_task
uclamp_rq_inc
dequeue_task
uclamp_rq_dec
(1) 先来看 uclamp_rq_inc 函数:
static inline void uclamp_rq_inc(struct rq *rq, struct task_struct *p) { enum uclamp_id clamp_id; /* * Avoid any overhead until uclamp is actually used by the userspace. * * The condition is constructed such that a NOP is generated when * sched_uclamp_used is disabled. */ //若是没有通过接口设置uclamp,这里直接就返回了 if (!static_branch_unlikely(&sched_uclamp_used)) return; //CFS和RT调度类的是静态使能的 if (unlikely(!p->sched_class->uclamp_enabled)) return; //只有MIN和MAX for_each_clamp_id(clamp_id) uclamp_rq_inc_id(rq, p, clamp_id); /* Reset clamp idle holding when there is one RUNNABLE task */ //清除idle标志 if (rq->uclamp_flags & UCLAMP_FLAG_IDLE) rq->uclamp_flags &= ~UCLAMP_FLAG_IDLE; } /*enqueue_task--> 入队时规划task到rq bucket中, 并更新uclamp_rq::value*/ static inline void uclamp_rq_inc_id(struct rq *rq, struct task_struct *p, enum uclamp_id clamp_id) { struct uclamp_rq *uc_rq = &rq->uclamp[clamp_id]; struct uclamp_se *uc_se = &p->uclamp[clamp_id]; struct uclamp_bucket *bucket; lockdep_assert_held(&rq->lock); /* Update task effective clamp */ //这里返回的不一定是 p->uclamp[clamp_id] 了,而是被限制后的,可能是per-cgroup的也可能是system-wide的 p->uclamp[clamp_id] = uclamp_eff_get(p, clamp_id); bucket = &uc_rq->bucket[uc_se->bucket_id]; bucket->tasks++; uc_se->active = true; /* * 若之前是idle,执行复位直接将 uc_se->value 设置到 uc_rq->value 中, * 复位后继续往下执行,uc_rq->value 仍然是最大值。 */ uclamp_idle_reset(rq, clamp_id, uc_se->value); /* * Local max aggregation: rq buckets always track the max * "requested" clamp value of its RUNNABLE tasks. * 本地最大聚合:rq 存储桶始终跟踪其 RUNNABLE 任务的最大“请求”钳位值。 */ //更新 bucket->value,使其保持为桶内最大 if (bucket->tasks == 1 || uc_se->value > bucket->value) bucket->value = uc_se->value; //更新 uc_rq->value,使其保持为桶内最大 if (uc_se->value > READ_ONCE(uc_rq->value)) WRITE_ONCE(uc_rq->value, uc_se->value); } /* * 获取任务有效的uclamp设置: * * 看以看出,内核per-task的uclamp设置要受到per-cgroup和system_wide的uclamp设置值的限制,只限制max/min的最大值,不限制最小值。 * * 可见优先级 system_wide > per-cgroup > per-task * * system_wide 可设置为[1024, 1024]以起到不做限制的目的。 */ static inline struct uclamp_se uclamp_eff_get(struct task_struct *p, enum uclamp_id clamp_id) { //uclamp_min/max 的最大值先受到 per-group 的uclamp设置值限制一下 struct uclamp_se uc_req = uclamp_tg_restrict(p, clamp_id); //唯一使用 uclamp_default[]的位置 struct uclamp_se uc_max = uclamp_default[clamp_id]; struct uclamp_se uc_eff; int ret = 0; trace_android_rvh_uclamp_eff_get(p, clamp_id, &uc_max, &uc_eff, &ret); //mtk_uclamp_eff_get if (ret) return uc_eff; //uclamp_min/max 的最大值再受system-wide的uclamp设置值再限制一次 /* System default restrictions always apply */ if (unlikely(uc_req.value > uc_max.value)) return uc_max; return uc_req; }
要想达到不被 system-wide 这个全局的设置影响,将 sched_util_clamp_min 和 sched_util_clamp_max 文件都设置为最大 1024 即可。因为大小两端都是大于全局的设置往低处拉。
/* * per-task的设置MIN/MAX的最大值受到per-cgroup设置值的限制 */ static inline struct uclamp_se uclamp_tg_restrict(struct task_struct *p, enum uclamp_id clamp_id) { struct uclamp_se uc_req = p->uclamp_req[clamp_id]; #ifdef CONFIG_UCLAMP_TASK_GROUP struct uclamp_se uc_max; /* * Tasks in autogroups or root task group will be * restricted by system defaults. */ if (task_group_is_autogroup(task_group(p))) return uc_req; //没有cgroup分组的任务返回自己的uclamp值 if (task_group(p) == &root_task_group) return uc_req; //获取任务所在group的uclamp值 uc_max = task_group(p)->uclamp[clamp_id]; /* * 若 task 的 req 是非 user_defined,也就是说是per-cgroup和 * system-wide设置下来的,直接返回group的uclamp; * 若是user_defined为true,也就是内核per-task的设置,uclamp_min/ * uclamp_max的最大值则要受到per-group clamp的限制。 */ if (uc_req.value > uc_max.value || !uc_req.user_defined) return uc_max; #endif return uc_req; } static inline void uclamp_idle_reset(struct rq *rq, enum uclamp_id clamp_id, unsigned int clamp_value) { /* Reset max-clamp retention only on idle exit */ if (!(rq->uclamp_flags & UCLAMP_FLAG_IDLE)) return; WRITE_ONCE(rq->uclamp[clamp_id].value, clamp_value); }
注:Kernel-5.10中 uclamp_tg_restrict()有变化,是直接clamp(value, tg_min, tg_max),cgroup不再是对per-task的min和max边界都向下拉了。上面备注是Google原生内核的,但是MTK加了一个hook,mtk_uclamp_eff_get():
//uc_eff 是 uclamp_eff_get()的返回值,ret是uclamp_eff_get()判断是否继续往下执行的 void mtk_uclamp_eff_get(void *data, struct task_struct *p, enum uclamp_id clamp_id, struct uclamp_se *uc_max, struct uclamp_se *uc_eff, int *ret) { struct uclamp_se group_uclamp = task_group(p)->uclamp[clamp_id]; *uc_eff = p->uclamp_req[clamp_id]; if (task_group_is_autogroup(task_group(p))) goto sys_restriction; //若是没有分组,保持逻辑不变 if (task_group(p) == &root_task_group) goto sys_restriction; //若是任务p在某个cgroup中 switch (clamp_id) { case UCLAMP_MIN: if (uc_eff->value < group_uclamp.value) //MIN值的最小值受per-cgroup设置值的限制 *uc_eff = group_uclamp; break; case UCLAMP_MAX: if (uc_eff->value > group_uclamp.value) //MAX值的最大值都per-cgroup设置值的限制 *uc_eff = group_uclamp; break; default: WARN_ON_ONCE(1); break; } sys_restriction: if (uc_eff->value > uc_max->value) //最后MAX/MIN的最大值再受system-wide设置值的限制 *uc_eff = *uc_max; *ret = 1; }
执行 hook 后 uclamp_eff_get() 的逻辑变化的部分为:任务p若是在某个cgroup中,其MIN的最小值也要受到per-cgroup设置值的限制,利于性能。
(2) 再看 uclamp_rq_dec 函数:
static inline void uclamp_rq_dec(struct rq *rq, struct task_struct *p) { enum uclamp_id clamp_id; /* * Avoid any overhead until uclamp is actually used by the userspace. * * The condition is constructed such that a NOP is generated when * sched_uclamp_used is disabled. */ //若是没有通过接口设置uclamp,这里直接就返回了。 if (!static_branch_unlikely(&sched_uclamp_used)) return; //CFS和RT调度类的是静态使能的 if (unlikely(!p->sched_class->uclamp_enabled)) return; //只有MIN/MAX for_each_clamp_id(clamp_id) uclamp_rq_dec_id(rq, p, clamp_id); } /* * 当任务从 rq 中dequeue时,任务引用的钳位桶被释放。如果这是对 rq 的最大active * 钳位值的最后一个任务的引用,则更新 rq 的钳位值。 * * 被引用计数的任务和 rq 的缓存钳位值都应始终有效。如果检测到它们无效,则作为防 * 御性编程,强制执行预期状态并发出警告。 */ static inline void uclamp_rq_dec_id(struct rq *rq, struct task_struct *p, enum uclamp_id clamp_id) { struct uclamp_rq *uc_rq = &rq->uclamp[clamp_id]; struct uclamp_se *uc_se = &p->uclamp[clamp_id]; struct uclamp_bucket *bucket; unsigned int bkt_clamp; unsigned int rq_clamp; lockdep_assert_held(&rq->lock); //主要担心enqueue后才使能的sched_uclamp_used,不是active的,说明enqueue时没有对其调用inc,所以这里不用dec if (unlikely(!uc_se->active)) return; bucket = &uc_rq->bucket[uc_se->bucket_id]; SCHED_WARN_ON(!bucket->tasks); if (likely(bucket->tasks)) bucket->tasks--; uc_se->active = false; /* * 保持“本地最大聚合”简单并接受(可能)在同一存储桶中过度提升一些 * RUNNABLE 任务。 只要不再有 RUNNABLE 任务对其进行引用计数,rq 钳 * 位桶值就会重置为其基值。 */ /* * 若rq上还有task,是不会更新 uc_rq->value 的,即使最大的util减去了, * 也不更新,对功耗的影响待评估!########## */ if (likely(bucket->tasks)) return; /* 下面对应这个 bucket 中没有任务的情况 */ rq_clamp = READ_ONCE(uc_rq->value); //Defensive programming: 这永远都不应该发生 SCHED_WARN_ON(bucket->value > rq_clamp); //大于不会出现,但是等于可能会出现 if (bucket->value >= rq_clamp) { bkt_clamp = uclamp_rq_max_value(rq, clamp_id, uc_se->value); WRITE_ONCE(uc_rq->value, bkt_clamp); } } static inline unsigned int uclamp_rq_max_value(struct rq *rq, enum uclamp_id clamp_id, unsigned int clamp_value) { struct uclamp_bucket *bucket = rq->uclamp[clamp_id].bucket; int bucket_id = UCLAMP_BUCKETS - 1; /* * Since both min and max clamps are max aggregated, find the * top most bucket with tasks in. * 由于最小和最大钳位都是最大聚合的,因此找到包含任务的最上面的桶。 */ for ( ; bucket_id >= 0; bucket_id--) { if (!bucket[bucket_id].tasks) continue; return bucket[bucket_id].value; } /* No tasks -- default clamp values */ //一个任务都没有了,就返回idle时对应的clamp值 return uclamp_idle_value(rq, clamp_id, clamp_value); } static inline unsigned int uclamp_idle_value(struct rq *rq, enum uclamp_id clamp_id, unsigned int clamp_value) { /* * Avoid blocked utilization pushing up the frequency when we go * idle (which drops the max-clamp) by retaining the last known max-clamp. * 通过保持上次的 max-clamp 来避免当进入idle时频点降低。 */ if (clamp_id == UCLAMP_MAX) { rq->uclamp_flags |= UCLAMP_FLAG_IDLE; return clamp_value; } //MIN: 0 return uclamp_none(UCLAMP_MIN); }
看来这个 UCLAMP_FLAG_IDLE 就是当 rq->uclamp[clamp_id] 中所有的 bucket 中都没有 runnable 任务时设置,然后将最后一个 dequeue 的任务的 p->uclamp[MAX].value 赋值给 uc_rq->value 以避免频点降的过低。
这是 core.c 中的代码,并且没有区分CFS线程还是RT线程。
(3) rq->uclamp_flags 之 UCLAMP_FLAG_IDLE 使用逻辑
除了上面列出的函数有对idle标志操作外,还有下面这个函数:
static inline void uclamp_rq_reinc_id(struct rq *rq, struct task_struct *p, enum uclamp_id clamp_id) { //不在队列上非runnable任务不更新 if (!p->uclamp[clamp_id].active) return; uclamp_rq_dec_id(rq, p, clamp_id); uclamp_rq_inc_id(rq, p, clamp_id); /* * Make sure to clear the idle flag if we've transiently reached 0 active tasks on rq. * 如果我们在 rq 上暂时达到 0 个活动任务,请确保清除空闲标志 ? */ if (clamp_id == UCLAMP_MAX && (rq->uclamp_flags & UCLAMP_FLAG_IDLE)) rq->uclamp_flags &= ~UCLAMP_FLAG_IDLE; }
其被 uclamp_update_active() 唯一调用:
static inline void uclamp_update_active(struct task_struct *p, enum uclamp_id clamp_id) { struct rq_flags rf; struct rq *rq; rq = task_rq_lock(p, &rf); uclamp_rq_reinc_id(rq, p, clamp_id); task_rq_unlock(rq, p, &rf); }
调用路径:
/proc/sys/kernel/sched_util_clamp_min //system-wide接口 /proc/sys/kernel/sched_util_clamp_max //system-wide接口 sysctl_sched_uclamp_handler uclamp_update_root_tg //core.c cgroup_mkdir //cgroup.c 应该是 mkdir创建一个cgroup分组时调用 cgroup_apply_control //cgroup.c cgroup_apply_control_enable css_create online_css //cgroup.c cpu_cgrp_subsys.css_online //回调 cpu_cgroup_css_online //core.c //cpu.uclamp.min 文件接口 cpu_uclamp_min_write //core.c //cpu.uclamp.max 文件接口 cpu_uclamp_max_write //core.c cpu_uclamp_write //core.c cpu_util_update_eff uclamp_update_active_tasks //遍历cgroup所有任务进行设置 uclamp_update_active uclamp_rq_reinc_id
总结:由上面贴出的函数可知,当 rq->uclamp[clamp_id] 中所有的 bucket 中都没有 runnable 任务时设置将最后一个 dequeue 的任务的 p->uclamp[MAX].value 赋值给 uc_rq->value 以避免频点降的过低。当新插入一个 runnable 任务时,在 uclamp_idle_reset() 中将 rq->uclamp[clamp_id].value 赋值为任务 uclamp_eff_get(p, clamp_id) 限制后的值,然后在 uclamp_rq_inc() 中清除 idle 标志。
3. 将 p->uclamp_req[] 更新到 p->uclamp[] 的时机
enqueue_task --> uclamp_rq_inc --> uclamp_rq_inc_id() 中更新为 uclamp_eff_get(p, clamp_id) 的返回值,原生逻辑即是受system-wide和per-cgroup uclmap设置对per-task设置值MIN/MAX的最大值进行限制后的值。
4. p->uclamp[] 起作用分析
(1) 在任务入队列和出队列时,在 uclamp_rq_inc_id()/uclamp_rq_dec_id() 中更新,然后用来去更新 rq->uclamp[clamp_id].bucket[] 和 rq->uclamp[clamp_id].value。
(2) 在 uclamp_task_util() 和 task_fits_capacity() 中使用
unsigned long uclamp_eff_value(struct task_struct *p, enum uclamp_id clamp_id) { struct uclamp_se uc_eff; /* Task currently refcounted: use back-annotated (effective) value */ if (p->uclamp[clamp_id].active) return (unsigned long)p->uclamp[clamp_id].value; uc_eff = uclamp_eff_get(p, clamp_id); //返回全局和cgroup限制MIN/MAX最大值后的值 return (unsigned long)uc_eff.value; } static inline unsigned long uclamp_task_util(struct task_struct *p) //fair.c { //返回的是 uclamp 限制后的 util_est return clamp(task_util_est(p), uclamp_eff_value(p, UCLAMP_MIN), uclamp_eff_value(p, UCLAMP_MAX)); } //对任务选核有影响,快速路径中判断了 static inline int task_fits_capacity(struct task_struct *p, long capacity) //fair.c { return fits_capacity(uclamp_task_util(p), capacity); //使用的是clamp后的util }
uclamp_task_util() 会在选核的快速路径中的 select_idle_capacity() select_idle_sibling()使用,主要是对唤醒任务选核的快速路径。
task_fits_capacity() 则会在 update_misfit_status() find_energy_efficient_cpu() detach_tasks() update_sg_wakeup_stats() 中使用。
(3) rt_task_fits_capacity() 中使用
static inline bool rt_task_fits_capacity(struct task_struct *p, int cpu) { unsigned int min_cap; unsigned int max_cap; unsigned int cpu_cap; /* Only heterogeneous systems can benefit from this check */ if (!static_branch_unlikely(&sched_asym_cpucapacity)) return true; min_cap = uclamp_eff_value(p, UCLAMP_MIN); max_cap = uclamp_eff_value(p, UCLAMP_MAX); cpu_cap = capacity_orig_of(cpu); return cpu_cap >= min(min_cap, max_cap); }
在rt任务选核任务中起作用,kernel-5.10 中rt任务也考虑了算力。
总结起来就是对任务的util进行uclmap影响其rq的uclamp值、选核、负载均衡。
5. rq->uclamp[clamp_id] 更新逻辑分析
per-rq 的 uclamp_rq 结构有 value 和 bucket 两个成员,在 enqueue_task 、dequeue_task 中更新,并始终保持为其rq队列上任务的effective uclamp值的最大值。
6. rq->uclamp[clamp_id] 起作用分析
(1) 设置opp时起作用
mtk_set_cpu_min_opp_single
mtk_set_cpu_min_opp_shared
(2) 调单CPU频率时起作用,rq->uclamp[clamp_id].value 会影响CPU频点。
sugov_update_single
sugov_next_freq_shared
mtk_uclamp_rq_util_with
(3) 为CFS任务选核时,EAS选核路径中跳过算力不足的cpu(hook中同逻辑),有利于为任务向上选核。
find_energy_efficient_cpu //fair.c util = uclamp_rq_util_with(cpu_rq(cpu), util, p); if (!fits_capacity(util, cpu_cap)) continue;
六、相关DEBUG方法
1. trace sched_task_uclamp
update_load_avg //fair.c propagate_entity_load_avg //fair.c set_task_rq_fair //fair.c 为任务选核时更新任务负载 sync_entity_load_avg //fair.c __update_load_avg_blocked_se //pelt.c update_load_avg //fair.c __update_load_avg_se //pelt.c trace_pelt_se_tp sched_task_uclamp_hook //sched_main.c trace_sched_task_uclamp(p->pid, util, p->uclamp[UCLAMP_MIN].active, p->uclamp[UCLAMP_MIN].value, p->uclamp[UCLAMP_MAX].value, uc_min_req->user_defined, uc_min_req->value, uc_max_req->user_defined, uc_max_req->value);
更新任务负载时进行trace,trace打印内容见下文。
2. trace sched_queue_task
dequeue_task //core.c enqueue_task //core.c sched_queue_task_hook trace_sched_queue_task(cpu, p->pid, type, util, rq->uclamp[UCLAMP_MIN].value, rq->uclamp[UCLAMP_MAX].value, p->uclamp[UCLAMP_MIN].value, p->uclamp[UCLAMP_MAX].value);
任务enqueue/dequeue时 trace 任务的 uclamp 值。
3. trace sugov_ext_util
cpufreq_update_util sugov_next_freq_shared //cpufreq_sugov_main.c sugov_update_single trace_sugov_ext_util(sg_cpu->cpu, util, umin, umax); //umin/umax 为rq->uclamp[UCLAMP_MIN/MAX].value,主要看umin
调频路径中 trace rq 的 uclamp 值。
七、测试
1. 优先级限制生效测试
# echo 50 > /dev/cpuctl/top-app/cpu.uclamp.min //50%为512, # cat /proc/<pid>/sched uclamp.min : 16 uclamp.max : 24 effective uclamp.min : 512 //立即变为512(MTK hook的MIN也向cgroup的MIN进行限制) effective uclamp.max : 24 # echo 100 > /proc/sys/kernel/sched_util_clamp_min //全局最高优先级min限制为100 # cat /proc/<pid>/sched effective uclamp.min : 100 //立即变为100 # echo 800 > /proc/sys/kernel/sched_util_clamp_min # cat /proc/<pid>/sched effective uclamp.min : 512 //重新回到512
2. 查看trace
(1) trace_sched_task_uclamp
trace_sched_task_uclamp(p->pid, util, p->uclamp[UCLAMP_MIN].active, p->uclamp[UCLAMP_MIN].value, p->uclamp[UCLAMP_MAX].value, p->uclamp_req[UCLAMP_MIN].user_defined, p->uclamp_req[UCLAMP_MIN].value, p->uclamp_req[UCLAMP_MAX].user_defined, p->uclamp_req[UCLAMP_MAX].value); //trace是依次打印每一个参数的值: # echo 50 > /dev/cpuctl/top-app/cpu.uclamp.min //cgroup的clamp_min设50% main-7710 [007] d..3 2159.461272: sched_task_uclamp: pid=7710 util=74 active=0 min=512 max=180 min_ud=1 min_req=163 max_ud=1 max_req=180 # echo 80 > /dev/cpuctl/top-app/cpu.uclamp.min //cgroup的clamp_min设80% main-7710 [007] d.h2 2170.227392: sched_task_uclamp: pid=7710 util=83 active=1 min=819 max=24 min_ud=1 min_req=16 max_ud=1 max_req=24 # echo 20 > /proc/sys/kernel/sched_util_clamp_min //全局的clamp_min设20% main-7710 [006] d..3 2189.762599: sched_task_uclamp: pid=7710 util=89 active=0 min=20 max=24 min_ud=1 min_req=8 max_ud=1 max_req=24
注意:cgroup的限制值和全局限制值是体现在 p->uclamp[] 上,而不是 p->uclamp_req[] 上。
(2) trace_sched_queue_task
trace_sched_queue_task(cpu, p->pid, type, util, rq->uclamp[UCLAMP_MIN].value, rq->uclamp[UCLAMP_MAX].value, p->uclamp[UCLAMP_MIN].value, p->uclamp[UCLAMP_MAX].value);
没有任何clamp限制时的打印:
kworker/u16:3-25905 [002] d..2 9251.745822: sched_queue_task: cpu=2 pid=25905 enqueue=-1 cfs_util=38 min=0 max=1024 task_min=0 task_max=1024
(3) trace_sugov_ext_util
trace_sugov_ext_util(sg_cpu->cpu, util, umin, umax); trace也是依次打印每一个参数的值: util: 取自 sugov_get_util() //clamp_min取p和rq二者的较大值,clamp_max取p的,返回限制后的结果。 umin: 取自 rq->uclamp[UCLAMP_MIN].value //是其上的所有se的最大的那个值 umax: 取自 rq->uclamp[UCLAMP_MAX].value main-7710 [006] d..7 2159.461842: sugov_ext_util: cpu=5 util=517 min=512 max=180 Binder:904_1-1002 [004] d..3 2189.730267: sugov_ext_util: cpu=6 util=819 min=819 max=24 RenderThread-7905 [006] d..5 2189.765668: sugov_ext_util: cpu=4 util=124 min=20 max=1024