odoo数据库 导入、导出
首先odoo框架下postgresql数据库中,表结构的存储方式:
存在id(小写),并没有所谓的外部ID
例如数据库中的国家表:模块名_tb_country (注意:odoo框架下,数据库中生成的表命名规则是,模块名_实际表名)
id code name
1 001 中国
2 002 美国
3 003 德国
。。。
odoo系统自带功能,前台界面导出的时候:导入兼容导出模式

这种情况下导出的csv表数据结构 : 注意这里导出的id为小写
id code name
__export__.模块名_tb_country_1 001 中国
__export__.模块名_tb_country_2 002 美国
__export__.模块名_tb_country_3 003 德国
我们再对比看下 另一种导出模式:导出全部数据
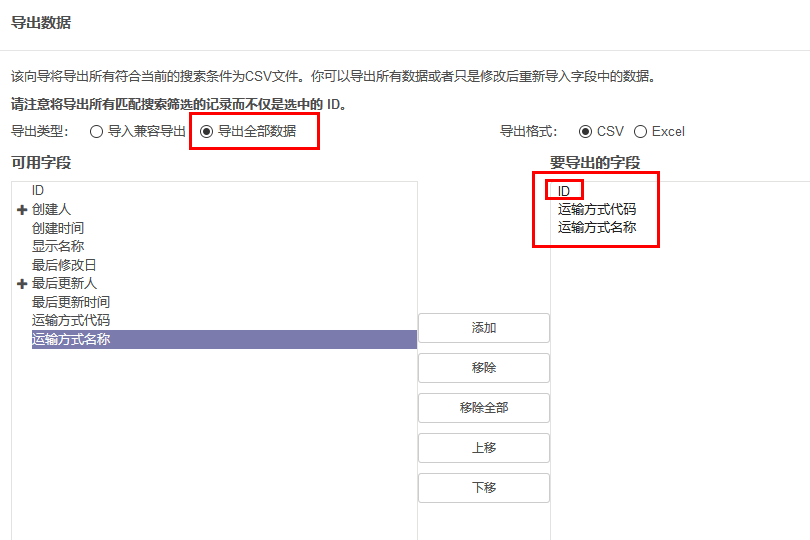
这种情况下导出的csv数据结构 :如果选择导出id,那么导出的CSV表中,外部id字段的表头,会和ID做个区分,改成了External ID
External ID ID code name
__export__.模块名_tb_country_1 1 001 中国
__export__.模块名_tb_country_2 2 002 美国
__export__.模块名_tb_country_3 3 003 德国
我们可以看到 两种方式导出的.CSV表结构可能有些区别,那么我们如果从外部导入原始数据的时候,应该怎么导入呢,官方建议是按照odoo的机制,最好导入外部id;
可以参考文档:
https://www.odoo.com/documentation/user/11.0/general/base_import/import_faq.html
http://www.sunpop.cn/documentation/user/10.0/zh_CN/general/base_import/import_faq.html
那我们导入数据的时候,具体应该按照哪种格式,制作CSV源表,
建议:比如我们在一个新odoo环境下,要导入国家表,那么可以按照如下格式:
方式1:
ID code name
模块名_tb_country_1 001 中国
模块名_tb_country_2 002 美国
模块名_tb_country_3 003 德国
方式2:
ID code name
__export__.模块名_tb_country_1 001 中国
__export__.模块名_tb_country_2 002 美国
__export__.模块名_tb_country_3 003 德国
方式3:
ID code name
tb_country_1 001 中国
tb_country_2 002 美国
tb_country_3 003 德国
两种方式都可以,方式1, 2加了__export__.前缀,系统也是正常识别的,不会报错,只是ID不会从1开始。(注:这里写错了 ,其实ID 不从1开始,是因为导入数据的时候,不能点击验证,否则id就不是从1开始了!!!)
建议以方式3导入,注意导入的时候ID字段的ID 要大写,不是小写。
补充知识:
postgresql 中表的字段,id字段,为整形自增字段,并且插入一条数据之后,该id是从1开始,而不是从0开始。
用truncate命令清空表之后,id字段并不会清空变成1,还是会继续历史数据id往后自增。
这里需要注意一下,
1.如果truncate命令执行的时候,提示有相关的表存在引用,执行的时候,可以加上cascade参数,具体语法:
TRUNCATE TABLE 表1,表2,表3...... cascade
表和表之间用 逗号分隔;
https://stackoverflow.com/questions/2679854/postgresql-disabling-constraints
https://www.yiibai.com/html/postgresql/2013/080676.html
2. 如果我们确实有,把id字段重置的需求,那么可以用以下方式:(注意,此方式还原id序列,并不会将数据清空,用了该方法之后,如果原表中数据没有被清空,往原表里插入数据是会报id已存在的错误的,所以该命令要配合truncete使用。)
ALTER SEQUENCE 表名_id_seq RESTART WITH 1
表名_id_seq查看获取方式:
项目中需要清空postgresql数据库中的一些表的数据,并将主键自增字段设置为1,在使用truncate在清表的时候,不能将主键自增字段重置为1,所以尝试采用下面这种方面进行重置自增的主键字段: ALTER SEQUENCE tab_seq RESTART WITH 1; 其中,tab_seq为表的序列标识(使用pgAdmin III软件序列标识位于数据库/数据库名/模式/序列/查找需要重置的序列)