今天我们来聊一聊redis,这是根据自己的理解来描述的,所以如果有不正确的,请大家批评指正
首先呢,redis 是 nosql ,是非关系型数据库 , 是基于key-value形式存储的,redis 是基于内存的,所以读写非常快,这样也被很多需要迅速响应的业务的场景所喜爱,虽然redis 是key value的形式,但是它支持很多数据结构的存储,这也是与memcached 的区别之一,memcached 只支持一些简单的字符串,而redis 支持 String ,List , Hash , Set , SortSet有序集合等,而且redis 支持持久化,即使重启也可以恢复。
我们平时使用的操作命令一般都是setString 形式的,一般我们的List集合也可以序列化成String 形式,如果涉及到Map形式可以使用 hset和hmset等形式,如果涉及到其他的业务我们可以灵活地使用这些命令用于存储,像比如说我要按照分数排名统计每个人对应的分数和名次,就可以使用zadd方法,这些是用于业务中的场景,其实redis还有一个非常重要的特性就是它是单线程的,可以很好地解决和处理一些问题
首先是redis可以用做分布式锁,现在基本上项目都是分布式的,集群的配置,同步锁 synchronized 已经无法控制多个请求,因为对应的多个服务,属于多个jvm,同步锁 synchronized只能控制多个线程,但是现在实际上已经是多个进程在访问,比如同步锁 synchronized 可以同步 对应一台机器上 请求A,请求B,但是如果在集群中假如请求A访问机器1请求B访问机器2,同步锁 synchronized就无法控制了,需要分布式锁 ,分布式锁可以使用 RedissonClient 来实现,网上的代码很多,就不再说了,或者使用SETNX 操作也可以,所依靠的就是redis的单线程操作。
还有一个就是比较有趣的如何实现一个秒杀系统,这个也是天猫的一道面试题,其实实现一个秒杀系统比较复杂,涉及的业务非常多,这里就不再说明,其实秒杀系统需要解决的就是高并发场景下如何准确的计算出我想要的极少数用户,不会产生订单>库存的现象,使用mq或者 redis 都可以实现,这里我们说一下使用redis来实现,由于redis是单线程的,非常适合用于高并发的场景下,而且读写迅速,适合这种秒杀系统,比如10万个用户争抢,最后只能有20个用户,我们可以使用List集合的lpop方法,事先存储20条数据,然后通过 lpop命令选出20个请求,然后剩下的全部打回。其实只要是redis的原子性操作,都可以避免数据不准确的情况,不要出现先读后写的情况,由于秒杀系统在某一时刻请求较多,qps会较高,所以建议redis部署在单独的机器上,页面使用静态页面等。
最近接触到了一个业务是 全网排行榜获取最新的20个用户的数据,要求实时刷新,对于实时刷新这样的需求,我们可以使用redis存储数据,那么如何保证所有的请求到达后我只保留20条数据呢,而且需要也有顺序,最新的请求到达后肯定是第一位的,榜首的位置,我们可以使用redis 的List集合,采用lpush的方式,最新的首位,但是我如何保证取到20位呢,当然,我们可以不设置list长度,让它一直lpush,取的话可以使用lrange key 0 ,19 但是随着不断lpush ,redis的key 需要维护的值会越来越大,导致redis 浪费资源存储很多没有用的数据,当然我们也可以通过判断长度,如果超出的话就rpop,但是在qps高 的情况下, 会出现判断后多个线程操作lpush或者rpop,数据就不准确了,其实就是查询redis key 和操作redis key 是两个操作,已经失去了原子性,所以我选择使用 pipeline管道,redis 支持使用pipeline,pipeline用于处理多条命令,批量获取的时候 ,它减少了redis与客户端交互的次数,并且大大提升了系统的吞吐量,需要注意到是用 pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。我们使用pipeline将命令绑定在一起,下面上代码:
public int lpushAndDel(String key, String value, int length, int exp) {
if (length < 1) {
return -11;
} else {
JedisWapper jedisWapper = null;
byte var7;
try {
jedisWapper = this.getJedis();
Pipeline p = jedisWapper.getJedis().pipelined();
Response<Long> response = p.llen(key);
p.lpush(key, new String[]{value});
if (response != null && ((Long)response.get()).intValue() >= length) {
p.rpop(key);
}
if (exp != 0) {
p.expire(key, exp);
}
p.sync();
byte var8 = 1;
return var8;
} catch (Exception var12) {
logger.error("lpush进list失败", var12);
var7 = -8;
} finally {
if (jedisWapper != null) {
jedisWapper.releaseFromPool(this.pool);
}
}
return var7;
}
}
代码使用的Java, 用的Jedis来操作redis实例。
现在是不是觉得redis很神奇,我们在碰到需要执行耗时特别久,且结果不频繁变动的 SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。那个redis为什么这么快呢,下面我们来看一下redis内部的原理,首先呢,redis是纯内存操作,读写快速,其次redis是单线程的,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗,最后呢redis 采用了非阻塞 I/O 多路复用机制 ,是什么意思呢,就是说不采用传统的并发模型 每个io 操作都启用一个新的线程来管理,而是使用单个线程将多个i/o请求放置到队列中来管理,统一分发,下面是比较真实的redis模型
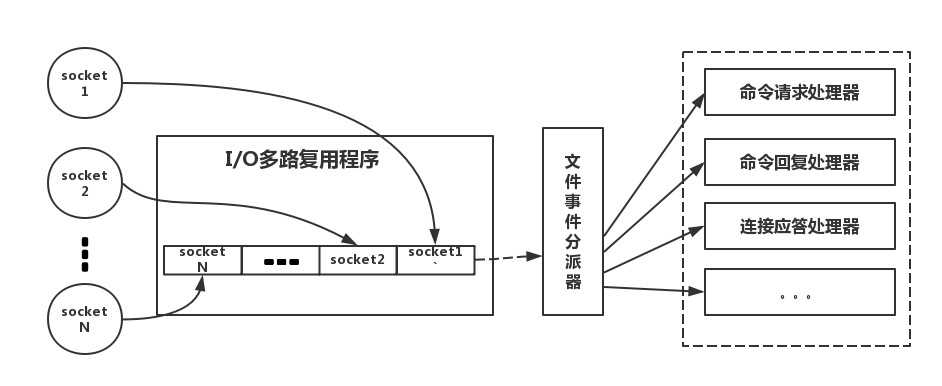
我们的 redis-client 在操作的时候,会产生具有不同事件类型的 Socket(i/o请求),在服务端,有一段 I/O 多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。redis使用多路复用IO模型来处理客户端的请求,每次会读客户端请求的所有命令到内存 并按照命令的顺序进行执行。
下面我们再来说一下redis的缓存失效问题,我们都知道redis都有缓存的失效时间,可以根据业务来设定时间长短,redis 有自己的过期策略和淘汰的机制, 它采用的是定期删除和惰性删除,redis 没有采用定时删除,因为这个会十分消耗cpu的资源,在大并发请求下,CPU 要将时间应用在处理请求,而不是删除 Key。要记住redis是用来处理数据的,而不是花费时间在删除过期的key上。定期删除,Redis 默认每个 100ms 检查,是否有过期的 Key,有过期 Key 则删除。需要说明的是,Redis 不是每个 100ms 将所有的 Key 检查一次,而是随机抽取进行检查(如果每隔 100ms,全部 Key 进行检查,Redis 岂不是会挂掉)。因此,如果只采用定期删除策略,会导致很多 Key 到时间没有删除。于是,惰性删除派上用场。惰性删除其实和Java 设计模式中的单例模式中的懒汉式很相似 ,你什么时候来找我,我才检查和操作,当我在获取某个key的时候,redis检查一下该key是否设置了失效时间,是否已过期,如果过期,就删除。那么这样还是会有问题,有一些不被经常访问的key会一直混在中间躲过了搜查,导致redis实际上存储着一些无用的数据,导致内存不断增高,redis内部有一个内存淘汰的机制,在 redis.conf 中有一行配置:# maxmemory-policy volatile-lru 这个就是内存的淘汰策略,有很多选项可以选择,可以根据不同的业务需求选择。推荐使用的是 allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 Key。 这个就是使用的咱们原来操作系统学习的lru算法。
redis 作为缓存,如何和数据库保持一致性的问题一直是令人头疼的问题,建议就是先操作数据库,再删缓存。
下面我们来说一下redis 的缓存穿透和缓存雪崩问题,其实redis 设置缓存的失效时间是一把双刃剑,例如对于缓存穿透来说,我们都知道一般查询数据都是先查询缓存,缓存没有的话再查询数据库,将查询结果放到缓存中并设置失效时间,如果有人故意大量请求去查询不存在的数据,这样会一直查询数据库,导致数据库挂掉,我推荐的做法是在数据库中如果没有查询到结果,也在缓存中放置结果,例如放置null字符串,并设置较短的失效时间,比如设置1分钟或者半分钟,防止一直请求数据库导致数据库连接异常。缓存雪崩是指由于在某个业务中可能存放大量的缓存,并且失效时间都是统一的,这样等时间已过可能缓存大面积失效,这样有大量请求过来的时候,缓存中已失效,全部请求数据库,从而导致数据库连接异常,当然这样的情况可能很难碰到,但是一旦遇到就会把数据库拖死,造成很大的影响,对于这种情况还没有好的控制的办法,如果大家有什么好的方法可以联系我,大家一块讨论。
当然对于redis 来说可能也是分布式的,配置redis集群,当遇到涉及key的操作时,可能多个请求对于某一个key 操作并不一定是在同一个redis-server机器上,这样就会出现数据被多个key set的情况,这不是我们想要看到的,我推荐的做法是准备一个redis分布式锁,多个请求去抢锁,抢到的可以有写缓存的权利,或者使用rpush 队列的形式,将多个争抢的key 排好顺序,最后只取第一个就可以了。
CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽。(来自官方)