原文链接:关于感受野的总结
论文链接:Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
一、感受野
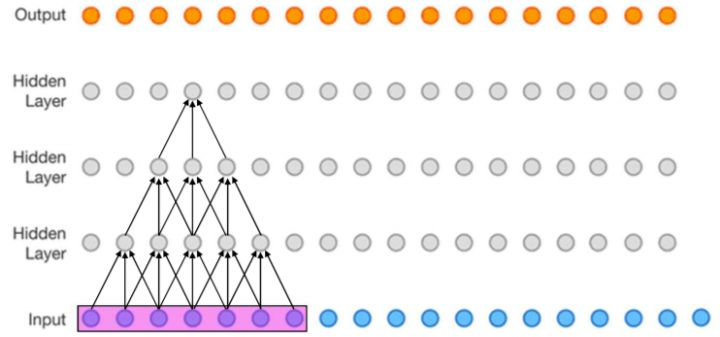
感受野被定义为卷积神经网络特征所能看到输入图像的区域,换句话说特征输出受感受野区域内的像素点的影响。下图展示了一个在输出层达到了7*7感受野的例子:
感受野计算公式为: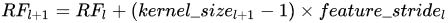 ,
,
如上例第一个隐层,![]() ,
,

如果存在空洞卷积,公式变为![]() 。
。
感受野计算的问题
上文所述的是理论感受野,而特征的有效感受野(实际起作用的感受野)实际上是远小于理论感受野的,如下图所示。具体数学分析比较复杂,不再赘述,感兴趣的话可以参考论文:Understanding the Effective Receptive Field in Deep Convolutional Neural Networks。

我们以下图为例,简要介绍有效感受野的问题:
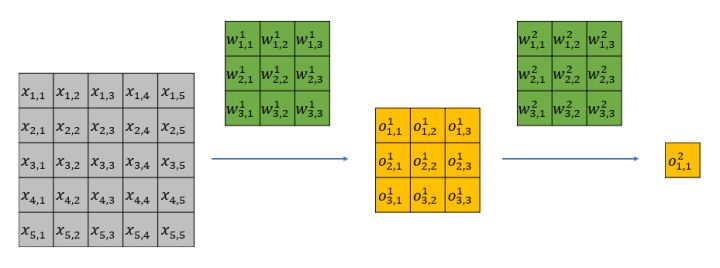
很容易可以发现, 只影响第一层feature map中的
;而
会影响第一层feature map中的所有特征,即
。
第一层的输出全部会影响第二层的 。
于是 只能通过
来影响
;而
能通过
来影响
。显而易见,虽然
和
都位于第二层特征感受野内,但是二者对最后的特征
的影响却大不相同,输入中越靠感受野中间的元素对特征的贡献越大。
计算公式
对于普通卷积:F(i, j-1) = (F(i, j) - 1)*stride + kernel_size
其中 F(i,j)表示第i层对第j层的局部感受野。
对于空洞卷积:F(i, j-1) = (F(i, j) - 1)*stride + dilation*(kernel_size - 1) + 1
经实际演算,以上公式正确。
二、感受野的应用
分类
Xudong Cao写过一篇叫《A practical theory for designing very deep convolutional neural networks》的technical report,里面讲设计基于深度卷积神经网络的图像分类器时,为了保证得到不错的效果,需要满足两个条件:
Firstly, for each convolutional layer, its capacity of learning more complex patterns should be guaranteed; Secondly, the receptive field of the top most layer should be no larger than the image region.
其中第二个条件就是对卷积神经网络最高层网络特征感受野大小的限制。
目标检测
现在流行的目标检测网络大部分都是基于anchor的,比如SSD系列,v2以后的yolo,还有faster rcnn系列。
基于anchor的目标检测网络会预设一组大小不同的anchor,比如32x32、64x64、128x128、256x256,这么多anchor,我们应该放置在哪几层比较合适呢?这个时候感受野的大小是一个重要的考虑因素。
放置anchor层的特征感受野应该跟anchor大小相匹配,感受野比anchor大太多不好,小太多也不好。如果感受野比anchor小很多,就好比只给你一只脚,让你说出这是什么鸟一样。如果感受野比anchor大很多,则好比给你一张世界地图,让你指出故宫在哪儿一样。
《S3FD: Single Shot Scale-invariant Face Detector》这篇人脸检测器论文就是依据感受野来设计anchor的大小的一个例子,文中的原话是
we design anchor scales based on the effective receptive field
《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》这篇论文在设计多尺度anchor的时候,依据同样是感受野,文章的一个贡献为
We introduce the Multiple Scale Convolutional Layers
(MSCL) to handle various scales of face via enriching
receptive fields and discretizing anchors over layers