一、Gluon数据加载
下面的两个dataset处理类一般会成对出现,两个都可做预处理,但是由于后面还可能用到原始图片,.ImageFolderDataset不加预处理的话可以满足,所以建议在.DataLoader预处理
图片数据(含标签)加载函数:gluon.data.vision.ImageFolderDataset
- .synsets,标签名列表list,因为实际存储位置是数字
- .__len__
给出ImageFolderDataset类的描述,
Init signature:
mxnet.gluon.data.vision.datasets.ImageFolderDataset(root, flag=1, transform=None)
Source:
class ImageFolderDataset(dataset.Dataset):
"""A dataset for loading image files stored in a folder structure like::
root/car/0001.jpg
root/car/xxxa.jpg
root/car/yyyb.jpg
root/bus/123.jpg
root/bus/023.jpg
root/bus/wwww.jpg
Parameters
----------
root : str
Path to root directory.
flag : {0, 1}, default 1 # 控制彩色or灰度
If 0, always convert loaded images to greyscale (1 channel).
If 1, always convert loaded images to colored (3 channels).
transform : callable, default None
A function that takes data and label and transforms them:
::
transform = lambda data, label: (data.astype(np.float32)/255, label)
Attributes
----------
synsets : list # 查看类别,实际就是文件名
List of class names. `synsets[i]` is the name for the integer label `i`
items : list of tuples # 生成的数据
List of all images in (filename, label) pairs.
"""
实例:
train_imgs = gluon.data.vision.ImageFolderDataset(
data_dir+'/hotdog/train',
transform=lambda X, y: transform(X, y, train_augs))
test_imgs = gluon.data.vision.ImageFolderDataset(
data_dir+'/hotdog/test',
transform=lambda X, y: transform(X, y, test_augs))
print(train_imgs)
print(train_imgs.synsets)
data = gluon.data.DataLoader(train_imgs, 32, shuffle=True)
<mxnet.gluon.data.vision.datasets.ImageFolderDataset object at 0x7fbed5641c18> ['hotdog', 'not-hotdog']
batch迭代器:gluon.data.DataLoader
具有特殊方法,def __iter__(self),其实例可以被迭代,也就是每次返回一个batch的数据,在第一维度上切割。
首个定位参数文档如下:
dataset : Dataset
Source dataset. Note that numpy and mxnet arrays can be directly used
as a Dataset.
最后生成的X_batch送入net(X_batch)向前传播,y_batch送入loss(output,y_batch)计算loss后反向传播。
二、MXNet.io:数据读取迭代器
https://blog.csdn.net/qq_36165459/article/details/78394322
从内存中读取数据
当数据存储在内存中,由NDArray 或numpy ndarray 支持时,我们可以使用NDArrayIter 读取数据:
import mxnet as mx
import numpy as np
data = np.random.rand(100,3) # 100个数据每个数据3特征
label = np.random.randint(0, 10, (100,)) # 100个标签
data_iter = mx.io.NDArrayIter(data=data, label=label, batch_size=30)
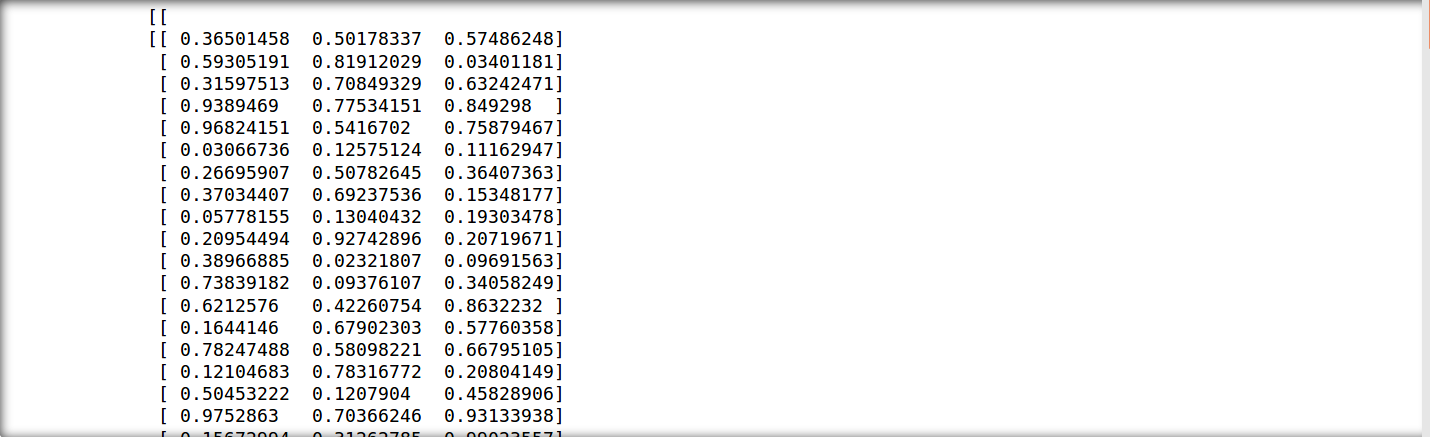
for batch in data_iter:
print([batch.data, batch.label, batch.pad],'
')
从CSV文件中读取数据
MXNet提供 CSVIter 从CSV文件中读取数据,用法如下:
#lets save `data` into a csv file first and try reading it back
np.savetxt('data.csv', data, delimiter=',')
# data_shape对应不上会报错
data_iter = mx.io.CSVIter(data_csv='data.csv', data_shape=(3,), batch_size=30)
for batch in data_iter:
print([batch.data, batch.pad])
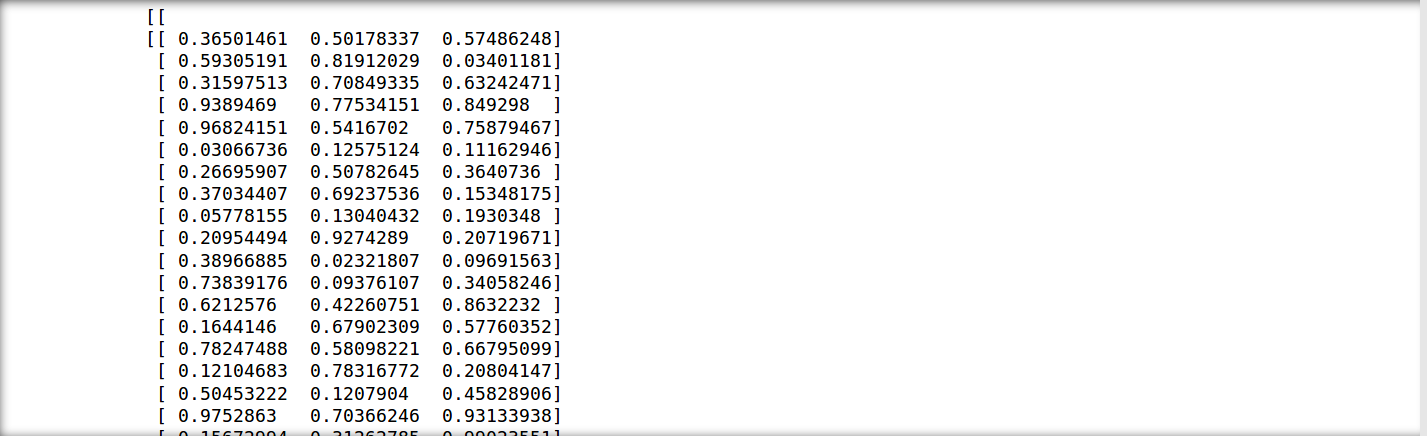
以上两种方法中的pad属性为int,表示有多少条数据是补充的(最后一个batch数据不够时的策略)。
三、MXNet.recordio:二进制rec文件交互
RecordIO是MXNet用于数据IO的文件格式,文件后缀为.rec。
它紧凑地打包数据,以便从Hadoop HDFS和AWS S3等分布式文件系统进行高效的读写。 MXNet提供MXRecordIO 和MXIndexedRecordIO,用于数据的顺序访问和随机访问。
注意,.rec文件写入的必须是整数或者二进制数据。
mx.recordio.MXRecordIO:顺序式rec文件
首先,我们来看一下如何使用MXRecordIO 顺序读写的例子,
record = mx.recordio.MXRecordIO('tmp.rec', 'w')
for i in range(5):
record.write(b'record_%d'%i)
record.close()
通过r 选项打开文件来读取数据,如下所示,
record = mx.recordio.MXRecordIO('tmp.rec', 'r')
while True:
item = record.read()
if not item:
break
print (item)
record.close()
mx.recordio.MXIndexedRecordIO:随机索引式rec文件
MXIndexedRecordIO 支持随机或索引访问数据。 我们将创建一个索引记录文件和一个相应的索引文件,如下所示:
record = mx.recordio.MXIndexedRecordIO('tmp.idx', 'tmp.rec', 'w')
for i in range(5):
record.write_idx(i, b'record_%d'%i)
record.close()
现在,我们可以使用键值访问各个记录:
record = mx.recordio.MXIndexedRecordIO('tmp.idx', 'tmp.rec', 'r')
record.read_idx(3)
还可以列出文件中的所有键:
record.keys
数据文件打包为规整的二进制结构
.rec文件中的每个记录都可以包含任意的二进制数据,然而,大多数深度学习任务需要以标签/数据格式作为输入。
mx.recordio 包为此类操作提供了一些实用功能,即:pack,unpack,pack_img 和unpack_img。
二进制数据的装包(mx.recordio.pack)与拆包(mx.recordio.unpack)
pack 和unpack 用于存储浮点数(或1维浮点数组)标签和二进制数据。
数据与头文件一起打包。
# pack data = b'data' label1 = 1.0 header1 = mx.recordio.IRHeader(flag=0, label=label1, id=1, id2=0) s1 = mx.recordio.pack(header1, data) label2 = [1.0, 2.0, 3.0] header2 = mx.recordio.IRHeader(flag=3, label=label2, id=2, id2=0) s2 = mx.recordio.pack(header2, data) # unpack print(mx.recordio.unpack(s1)) print(mx.recordio.unpack(s2))
mx.recordio.pack返回的s1、s2为二进制字节流,而mx.recordio.unpack则返回tuple。
s = mx.recordio.unpack(s1) isinstance(s[0], tuple)
True
图像数据的装包与拆包
由于图片数据在DL中尤为常用,所以单独给图片数组设计出接口,这个接口可以接收numpy数组,自动将之转化为二进制数据存入文件,解压时逆向操作。
MXNet提供pack_img 和unpack_img 来打包/解压图像数据,pack_img 打包的记录可以由mx.io.ImageRecordIter 加载。
data = np.ones((3,3,1), dtype=np.uint8) label = 1.0 header = mx.recordio.IRHeader(flag=0, label=label, id=0, id2=0) s = mx.recordio.pack_img(header, data, quality=100, img_fmt='.jpg') # unpack_img print(mx.recordio.unpack_img(s))
(HEADER(flag=0, label=1.0, id=0, id2=0),
array([[1, 1, 1],
[1, 1, 1],
[1, 1, 1]], dtype=uint8))
四、自定义迭代器
自定义迭代器
当内置的迭代器不符合应用需求时,可以创建自己的自定义数据迭代器。
MXNet中的迭代器应该:
- 实现Python2中的next() 或者Python3中的__ next() __,返回DataBatch 或者到数据流的末尾时抛出StopIteration 异常。
- 实现reset() 方法,从头开始读取数据
- 具有一个provide_data 属性,包括存储了数据的名称,形状,类型和布局信息的DataDesc 对象的列表
- 具有一个provide_label 属性,包括存储了标签的名称,形状,类型和布局信息的DataDesc 对象的列表
当创建一个新的迭代器时,你既可以从头开始定义一个迭代器,也可以使用一个现有的迭代器。例如,在图像字幕应用中,输入样本是图像,而标签是句子。 因此,我们可以通过以下方式创建一个新的迭代器:
- 通过使用ImageRecordIter 创建一个image_iter,它提供多线程的预取和增强。
- 通过使用NDArrayIter 或 rnn 包中提供的bucketing 迭代器创建caption_iter 。
- next() 返回image_iter.next() 和caption_iter.next() 的组合结果
class SimpleIter(mx.io.DataIter):
def __init__(self,
# data_shaps:包含batch维的数据,data_gen:函数,接收参数data_shapes
data_names, data_shapes, data_gen,
# label_shaps:包含batch维的标签,label_gen:函数,接收参数label_shapes
label_names, label_shapes, label_gen,
num_batches=10):
"""
实际上这个class着重修改__init__和next即可,包证next的return是一个batch的数据
n = 32
data_iter = SimpleIter(['data'], [(n, 100)],
[lambda s: np.random.uniform(-1, 1, s)],
['softmax_label'], [(n,)],
[lambda s: np.random.randint(0, num_classes, s)])
"""
self._provide_data = zip(data_names, data_shapes)
self._provide_label = zip(label_names, label_shapes)
self.num_batches = num_batches
self.data_gen = data_gen
self.label_gen = label_gen
self.cur_batch = 0
def __iter__(self):
return self
def reset(self):
self.cur_batch = 0
def __next__(self):
return self.next()
@property
def provide_data(self):
return self._provide_data
@property
def provide_label(self):
return self._provide_label
def next(self):
if self.cur_batch < self.num_batches:
self.cur_batch += 1
data = [mx.nd.array(g(d[1]))
for d,g in zip(self._provide_data, self.data_gen)]
label = [mx.nd.array(g(d[1]))
for d,g in zip(self._provide_label, self.label_gen)]
return mx.io.DataBatch(data, label)
else:
raise StopIteration
简单定义一个网络,
import mxnet as mx
num_classes = 10
net = mx.sym.Variable('data')
net = mx.sym.FullyConnected(data=net, name='fc1', num_hidden=64)
net = mx.sym.Activation(data=net, name='relu1', act_type="relu")
net = mx.sym.FullyConnected(data=net, name='fc2', num_hidden=num_classes)
net = mx.sym.SoftmaxOutput(data=net, name='softmax')
print(net.list_arguments())
print(net.list_outputs())
训练示意,
import logging
logging.basicConfig(level=logging.INFO)
n = 32
data_iter = SimpleIter(['data'], [(n, 100)],
[lambda s: np.random.uniform(-1, 1, s)],
['softmax_label'], [(n,)],
[lambda s: np.random.randint(0, num_classes, s)])
mod = mx.mod.Module(symbol=net)
mod.fit(data_iter, num_epoch=5)