Tensor存储结构如下,
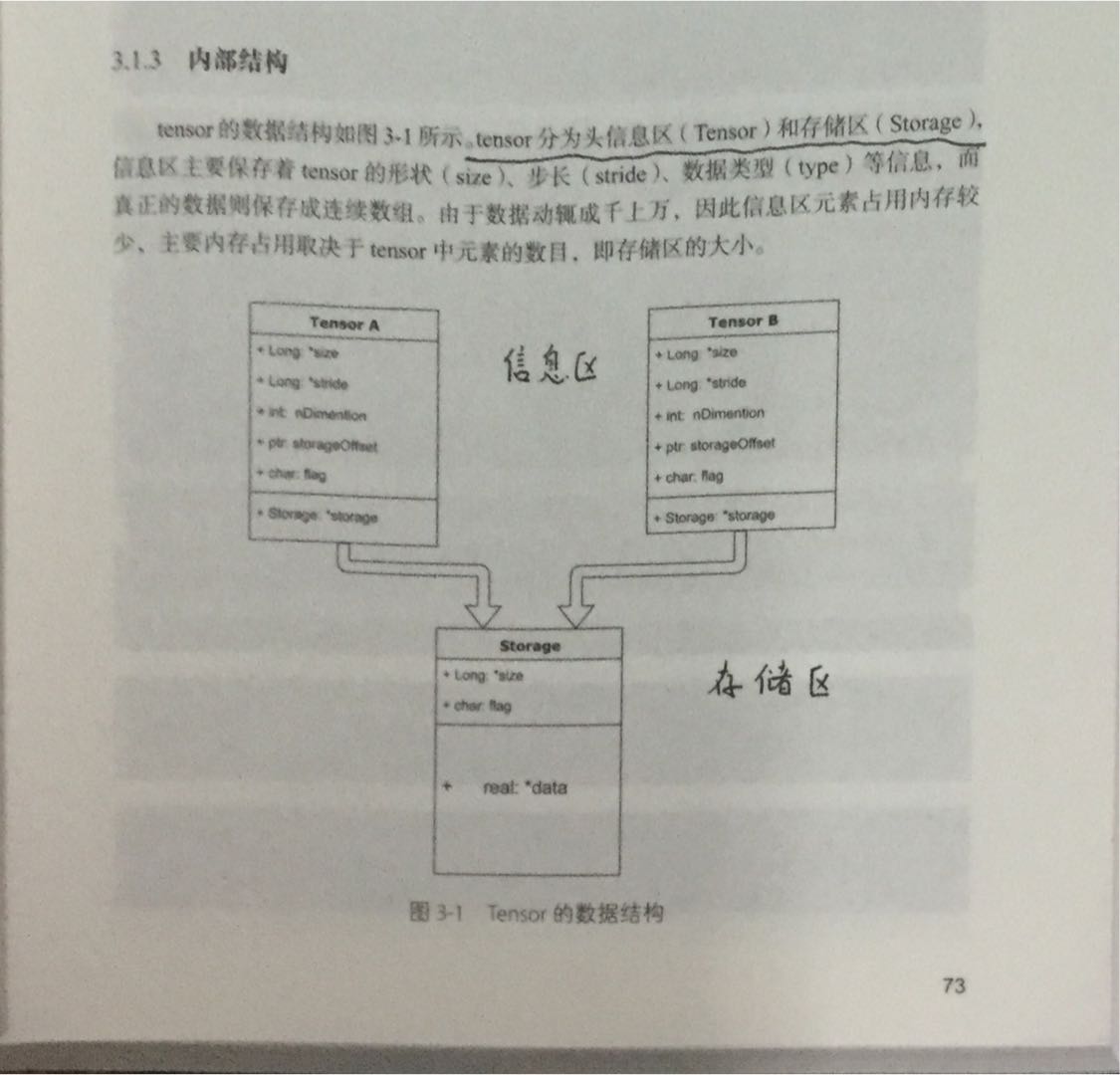
如图所示,实际上很可能多个信息区对应于同一个存储区,也就是上一节我们说到的,初始化或者普通索引时经常会有这种情况。
一、几种共享内存的情况
view
a = t.arange(0,6) print(a.storage()) b = a.view(2,3) print(b.storage()) print(id(a.storage())==id(b.storage())) a[1] = 10 print(b)
上面代码,我们通过.storage()可以查询到Tensor所对应的storage地址,可以看到view虽然不是inplace的,但也仅仅是更改了对同一片内存的检索方式而已,并没有开辟新的内存:
0.0 1.0 2.0 3.0 4.0 5.0 [torch.FloatStorage of size 6] 0.0 1.0 2.0 3.0 4.0 5.0 [torch.FloatStorage of size 6] True 0 10 2 3 4 5 [torch.FloatTensor of size 2x3]
简单索引
注意,id(a.storage())==id(c.storage()) != id(a[2])==id(a[0])==id(c[0]),id(a)!=id(c)
c = a[2:] print(c.storage()) # c所属的storage也在这里 print(id(a[2]), id(a[0]),id(c[0])) # 指向了同一处 print(id(a),id(c)) print(id(a.storage()),id(c.storage()))
0.0 10.0 2.0 3.0 4.0 5.0 [torch.FloatStorage of size 6] 2443616787576 2443616787576 2443616787576 2443617946696 2443591634888 2443617823496 2443617823496
通过Tensor初始化Tensor
d = t.Tensor(c.storage()) d[0] = 20 print(a) print(id(a.storage())==id(b.storage())==id(c.storage())==id(d.storage()))
二、内存检索方式查看
storage_offset():偏移量
stride():步长,注意下面的代码,步长比我们通常理解的步长稍微麻烦一点,是有层次结构的步长
print(a.storage_offset(),b.storage_offset(),c.storage_offset(),d.storage_offset()) e = b[::2,::2] print(id(b.storage())==id(e.storage())) print(b.stride(),e.stride()) print(e.is_contiguous()) f = e.contiguous() # 对于内存不连续的张量,复制数据到新的连续内存中 print(id(f.storage())==id(e.storage())) print(e.is_contiguous()) print(f.is_contiguous()) g = f.contiguous() # 对于内存连续的张量,这个操作什么都没做 print(id(f.storage())==id(g.storage()))
高级检索一般不共享stroage,这就是因为普通索引可以通过修改offset、stride、size实现,二高级检索出的结果坐标更加混乱,不方便这样修改,需要开辟新的内存进行存储。
三、其他有关Tensor
持久化
t.save和t.load,由于torch的为单独Tensor指定设备的特性,实际保存时会保存设备信息,但是load是通过特定参数可以加载到其他设备,详情help(torch.load),其他的同numpy类似
向量化计算
Tensor天生支持广播和矩阵运算,包含numpy等其他库在内,其矩阵计算效率远高于python内置的for循环,能少用for就少用,换句话说python的for循环实现的效率很低。
辅助功能
设置展示位数:t.set_printoptions(precision=n)
In [13]: a = t.randn(2,3)
In [14]: a
Out[14]:
1.1564 0.5561 -0.2968
-1.0205 0.8023 0.1582
[torch.FloatTensor of size 2x3]
In [15]: t.set_printoptions(precision=10)
In [16]: a
Out[16]:
1.1564352512 0.5561078787 -0.2968128324
-1.0205242634 0.8023245335 0.1582107395
[torch.FloatTensor of size 2x3]
out参数:
很多torch函数有out参数,这主要是因为torch没有tf.cast()这类的类型转换函数,也少有dtype参数指定输出类型,所以需要事先建立一个输出Tensor为LongTensor、IntTensor等等,再由out导入,如下:
In [3]: a = t.arange(0, 20000000)
In [4]: print(a[-1],a[-2])
16777216.0 16777216.0
可以看到溢出了数字,如果这样处理,
In [5]: b = t.LongTensor()
In [6]: b = t.arange(0,20000000)
In [7]: b[-2]
Out[7]: 16777216.0
还是不行,只能这样,
In [9]: b = t.LongTensor()
In [10]: t.arange(0,20000000,out=b)
Out[10]:
0.0000e+00
1.0000e+00
2.0000e+00
⋮
2.0000e+07
2.0000e+07
2.0000e+07
[torch.LongTensor of size 20000000]
In [11]: b[-2]
Out[11]: 19999998
In [12]: b[-1]
Out[12]: 19999999