论文地址:https://arxiv.org/abs/1804.02516
研究领域
文本-视频检索。
存在问题
缺乏大规模的标注数据。
One difficulty with this approach, however, is the lack of large-scale annotated video-caption datasets for training. To address this issue, we aim at learning text-video embeddings from heterogeneous data sources.
本文创新
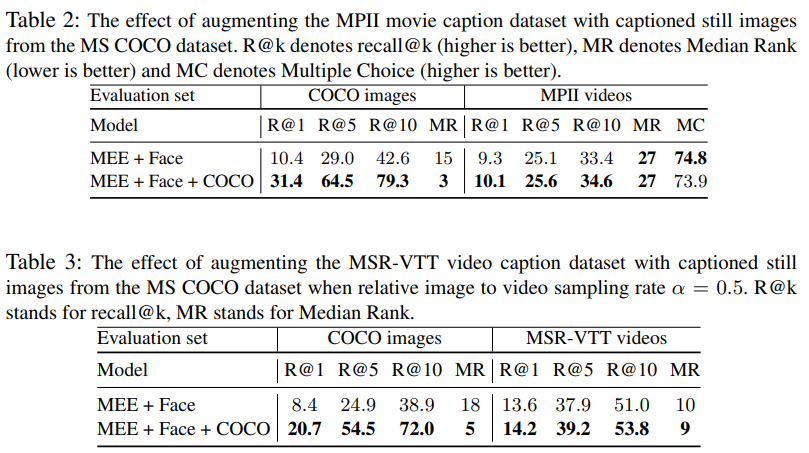
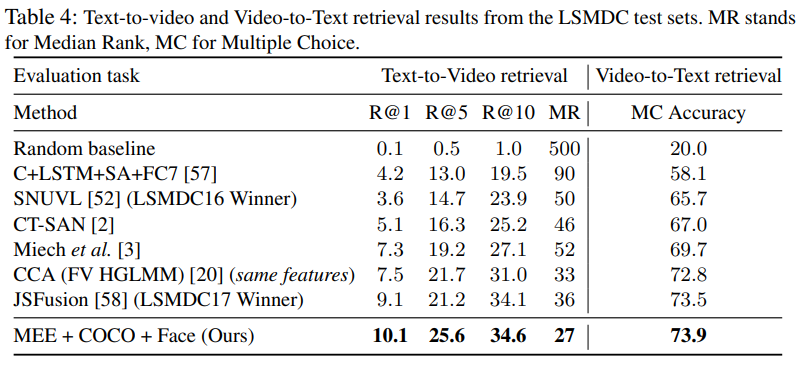
提出Mixture-of-Embedding-Experts (MEE) model,可以处理缺失一部分信息的“视频”,将之正常的与文本进行匹配,增加训练集大小。
论文的出发点下图表示的很清楚,就是将不同形式的数据映射到相同的特征空间,使得最大化的利用数据(即使缺失部分构成要素,例如图像相对视频,也能充分的学习仅剩的部分)。

具体来说,视频数据被拆成了多个源,每个源和句子的一种特征表示进行相似度计算,最终结果为加权平均:
文本先经过NetVLAD提取特征(This is motivated by the recent results [34] demonstrating superior performance of NetVLAD aggregation over other common aggregation architectures such as long short-term memory (LSTM) [48] or gated recurrent units (GRU) [49].),然后文本经过下面的映射:
(1)就是维度映射,而(2)将Z原文解释为:
The second layer, given by (2), performs context gating [34], where individual dimensions of Z1 are reweighted using learnt gating weights σ(W2Z1 + b2) with values between 0 and 1, where W2 and b2 are learnt parameters.
The motivation for such gating is two-fold: (i) we wish to introduce nonlinear interactions among dimensions of Z1 and (ii) we wish to recalibrate the strengths of different activations of Z1 through a self-gating mechanism. Finally, the last layer, given by (3), performs L2 normalization to obtain the final output Z.
[34] Miech, A., Laptev, I., Sivic, J.: Learnable pooling with context gating for video classification. arXiv preprint arXiv:1706.06905 (2017)
上面的这个结构式多个并行的,每个针对视频的一种源,作者解释这是因为不同的视频源形式关注文字中的不同部分,实际上(2)也是在用文本自身调节自身的特征分布。
作者还介绍了相似度计算过程,很简单,值得一提的是,不同的视频源描述符(different streams of input descriptors)的权重完全由句子计算,作者认为句子可以作为先验决定描述的视频更侧重哪方面——这也是种自注意力机制:

最后用检索任务常用的margin损失函数收尾:

实验部分