Kafka多个消费者的小例子
public class FirstMultiConsumerThreadDemo2 {
public static final String brokerList = "10.211.55.3:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
public static Properties initConfig() {
Properties props = new Properties();
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
// props.put(ConsumerConfig.CLIENT_ID_CONFIG,"consumer.client.id.demo");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumerThread consumerThread = new KafkaConsumerThread(props,topic,Runtime.getRuntime().availableProcessors());
consumerThread.start();
}
public static class KafkaConsumerThread extends Thread {
private KafkaConsumer<String,String> kafkaConsumer;
private ExecutorService executorService;
private int threadNumber;
public KafkaConsumerThread(Properties props,String topic,int threadNumber) {
this.kafkaConsumer = new KafkaConsumer<>(props);
this.kafkaConsumer.subscribe(Collections.singletonList(topic));
this.threadNumber = threadNumber;
executorService = new ThreadPoolExecutor(threadNumber,threadNumber,0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000),new ThreadPoolExecutor.CallerRunsPolicy());
}
@Override
public void run() {
try {
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
//将一批消息,即records封装成任务类,提交给线程池
//通常这一步最为耗时,通过异步的方式,降低处理业务逻辑所耗费的时间
executorService.submit(new RecordHandler(records));
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
}
public static class RecordHandler extends Thread{
public final ConsumerRecords<String,String> records;
public RecordHandler(ConsumerRecords<String,String> records){
this.records = records;
}
@Override
public void run() {
//处理records
}
}
}
RecordHandler类是用来处理消息的,注意线程池的最后一个参数设置的是:CallerrunsPolicy,这样可以防止线程池的总体消费能力跟不上poll()的能力,从而导致异常现象的发生。
一般而言,poll()拉取消息的速度是相当快的,而整体消费的瓶颈也正是在处理消息这一块,如果我们通过异步的方式,就能 带动整体消费性能的提升。
如下图:
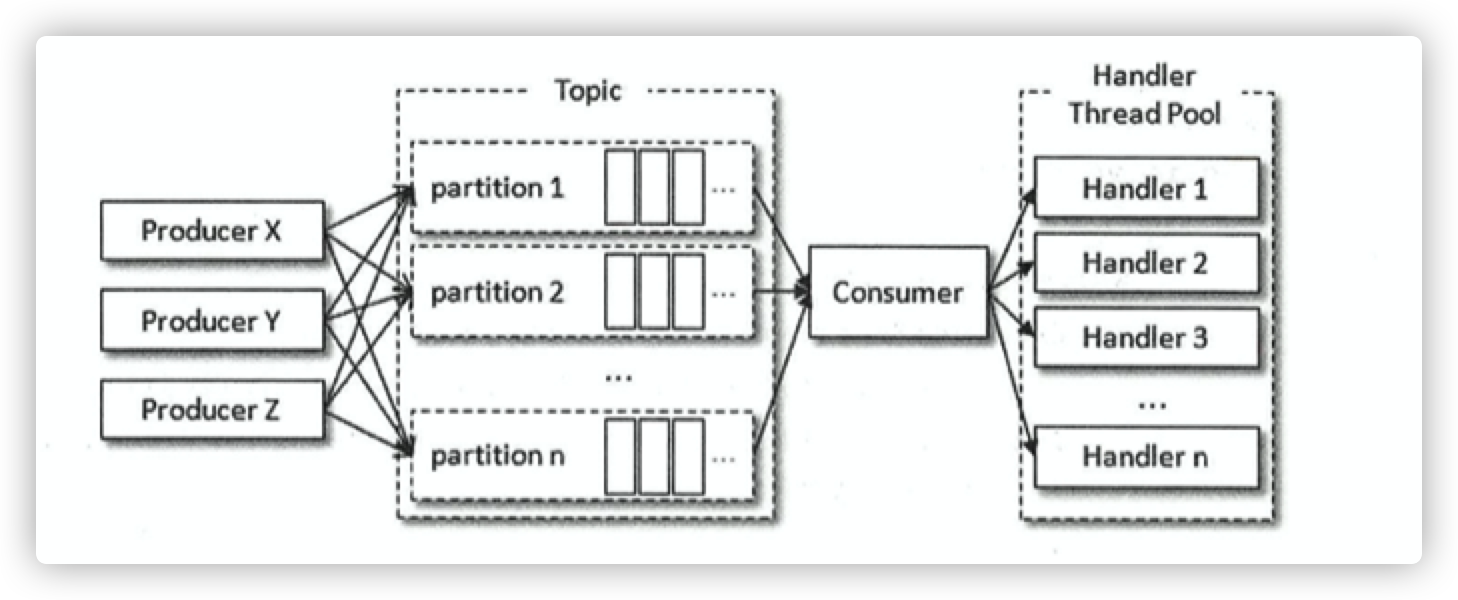
将处理消息改成多线程的实现方式。