中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#
1.1 安装BeautifulSoup模块和解析器
1) 安装BeautifulSoup
pip install beautifulsoup4
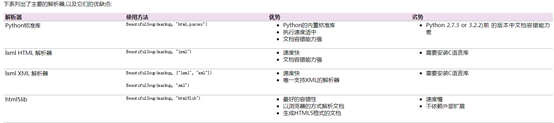
2) 安装解析器
pip install lxml
pip install html5lib
1.2 对象种类
- Tag : 标签对象,如:<p class="title"><b>yoyoketang</b></p>,这就是一个标签
- NavigableString :字符对象,如:这里是我的微信公众号:yoyoketang
- BeautifulSoup :就是整个html对象
- Comment :注释对象,如:!-- for HTML5 --,它其实就是一个特殊NavigableString
1.3 常用方法
# coding:utf-8
__author__ = 'Helen'
'''
description:爬虫模块BeautifulSoup学习
'''
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.baidu.com/")
soup = BeautifulSoup(r.content,'html5lib')
print soup.a # 根据tab名输出,只输出第一个
print soup.find('a') # 同上
print soup.find_all('a') # 输出所有a元素
# 找出对应的tag,再根据元素属性找内容
print soup.find_all('a',{'href':'https://www.hao123.com','name':'tj_trhao123'})
# .contents(tag对象contents可以获取所有的子节点,返回的是list,获取该元素的直接子节点)
print soup.find('a').contents[0] # 输出第一个节点
print soup.find('div',id='u1').contents[1] # 输出第二个节点
# .children(点children这个生成的是list对象,跟上面的点contents功能一样,但是不能通过下标读,只能for循环读)
for i in soup.find('div',id='u1').children:
print i
# .descendants(获取所有的子孙节点)
for i in soup.find(class_='head_wrapper').descendants:
print i