20180912-3 词频统计
作业要求参见:https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583
老五在寝室吹牛他熟读过《鲁滨逊漂流记》,在女生面前吹牛热爱《呼啸山庄》《简爱》和《飘》,在你面前说通读了《战争与和平》。但是,他的四级至今没过。你们几个私下商量,这几本大作的单词量怎么可能低于四级,大家听说你学习《构建之法》,一致推举你写个程序名字叫wf,统计英文作品的单词量并给出每个单词出现的次数,准备用于打脸老五。
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
重难点:初次接触这类问题,感觉难点很多,首先在将py文件转换成EXE文件就花费了我好多的时间,先是pip版本过低,无法安装想要的包,后来升级报错。
部分代码:
def count(words): collect = collections.Counter(words) num = 0 for i in collect: num += 1 print('total %d words ' % num) result = collect.most_common(10) for j in result: print('%-8s%5d' % (j[0], j[1]))
截图: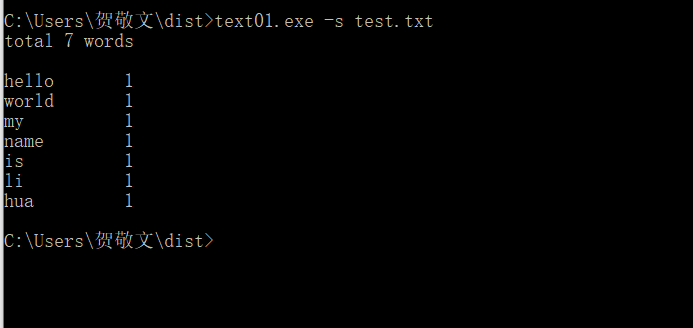
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
重难点:在这个问题上我感觉重难点就是如何将一个文件名读入,我是采用在读入的文件中没有.txt后缀的文本让程序给他加上然后再读入。
部分代码:
def doCount(accept): s = '.txt' if s in accept: path = accept else: path = accept + '.txt' f = open(path, encoding='utf-8') words = re.findall(r'[a-z0-9^-]+', f.read().lower()) count(words)
截图:

功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
重难点:这个功能感觉比较难,请教了学长才完成。
部分代码:
def doSomeFileCount(path): print(path) f = open(path, encoding='utf-8') words = re.findall(r'[a-z0-9^-]+', f.read().lower()) count(words) print('----') def doCountByPurText(inputText): words = re.findall(r'[a-z0-9^-]+', inputText.lower()) count(words)
截图:
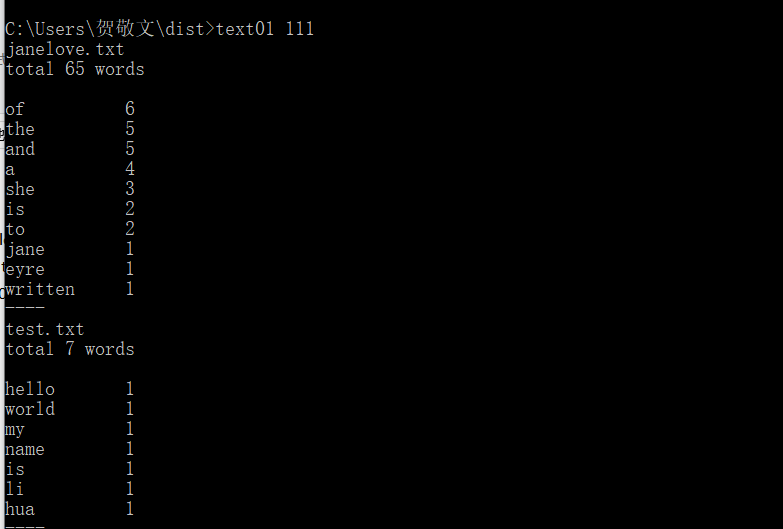
功能4 未完成
PSP
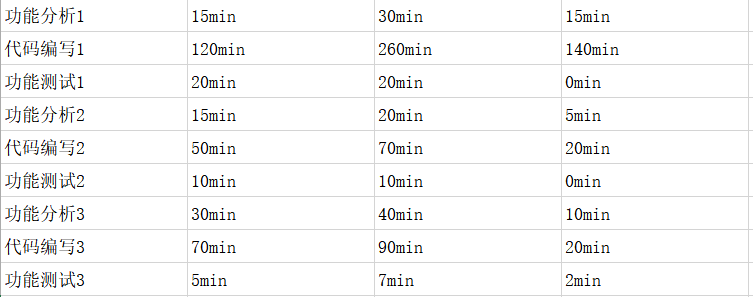
代码链接:https://e.coding.net/hejw031/hejw03.git
总结:
在做这个作业时,我深刻认识到了自己的不足,在看到题目时,原本打算用c语言写,可是后来发现实在是太麻烦了,总是不是这不行就是那不中,学长说用python很简单的,可是我对python并没有太多的了解,只能边学边写了,在一次次失败后终于跑出来了第一个功能,后来第二个功能没有思路,在学长提了一些意见后最终实现,可是最后一个功能还是没有实现,我也不会放弃,等我python学的更全面一些我会把最后一个功能做出来。