CORS跨域资源共享是前后端跨域十分常用的一种方案,主要依赖Access-Control-Allow(ACA)系列header来实现一种协商性的跨域交互。
基本模型
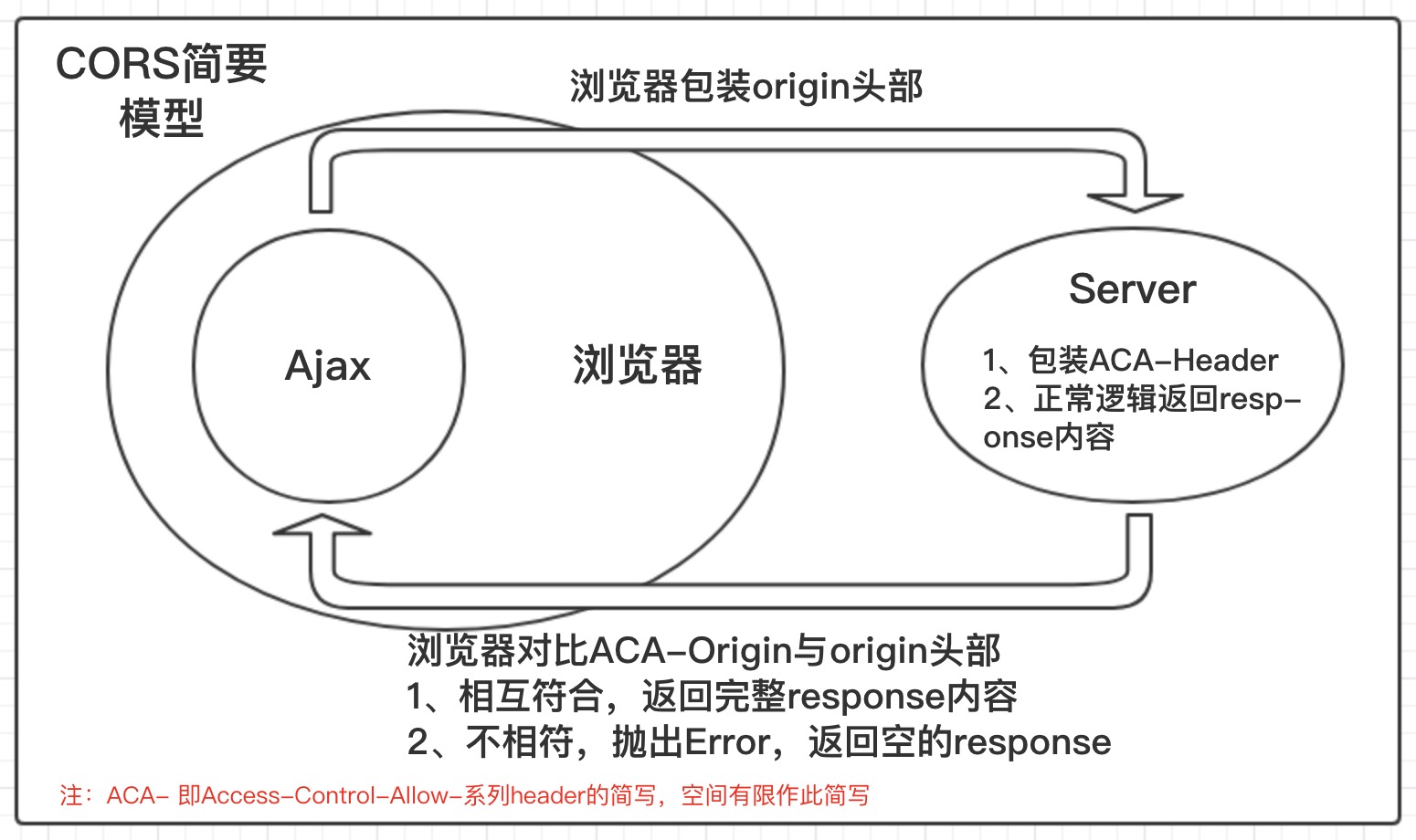
其中的具体流程大致可以分为以下几步:
1、前端从webview上发出ajax请求
2、浏览器监测到ajax跨域,添加origin头部,标明请求来源
2、后端接收到请求后,根据正常业务逻辑包装业务返回
3、在业务返回的response上添加ACA系列头部,如
'Access-Control-Allow-Origin' '*';
'Access-Control-Allow-Credentials' "true";
'Access-Control-Allow-Headers' 'X-Requested-With';
等等
4、浏览器接收到返回后判断ACA-Origin和之前加上的origin头部是否相符,相符的话进入5,否则进入第6步
5、返回完整的response内容到ajax的success中,ajax结束
6、抛出Error对象到给浏览器处理,置空response的返回给ajax处理
如果画一个来理解的话,大致如下
更详尽的内容大家可以去看一下阮一峰老师写的《跨域资源共享 CORS 详解》,里面介绍的很详尽,在这里也不在细说了。下面说说本文的另一个重点--常见理解误区
常见理解误区
看下这个问题
Q: 跨域失败的时候,后端接口返回的内容是什么样的?
当我们很多时候都在思考怎么跨域的时候,不知道大家有没有想过这个问题?跨域失败很自然的给人的想法就是拿不到数据,那肯定就是后端没有返回啊。然而很多我们理所当然的却不并是理所当然的那个样子。
事实是,
A: 跨域失败对于后端是没有感知的,跨域本来就不是服务端的事儿,它只是打个辅助,返回的数据和你跨域成功的时候一毛一样,一毛一样
是的,一毛一样。来个例子用事实说句话
我们在一个页面上发送了一个xxx/ 的跨域请求,接口端没做cors处理,这时我们在浏览器会看到

什么返回都没有,response返回体是空的,控制台报错啦,事实上呢?我们用charles抓包看到的实际情况是

看到没?服务端返回的是正常数据啊。
这个时候我们回头看看上面我们写的那个cors模型流程,服务端接口所做的工作和非跨域请求唯一的区别只是多加了那么几个ACA的头部,你觉得这几个ACA的头部直接就把数据搞没了?Naive。所以接口返回的返回体完全没变。
再来看看我为什么说跨域本来就不是服务端的事儿,它只是打个辅助。回顾一下跨域的概念,你会发现跨域本身只是浏览器上由于同源策略才存在的一种安全保障行为,服务端一个接口可能供给浏览器中的接口调用,也可以同时给其他服务使用。一个接口数据返回来了,浏览器判断是不是跨域你自己去处理,和后端就没有关系了。
这个问题说实话最开始的时候,我的反应也是错的,后面仔细想了想才得到这个答案,或许这只是和我一样小白的误区,希望对大家有所帮助吧。
~全篇完~
前面还写了一个nginx跨域相关的《nginx反向代理跨域基本配置与常见误区》,大家有兴趣欢迎来踩,如有问题欢迎指出~
~真·全篇完~