要爬取的网站是浙江水利局的台风路径网站,在该网站不仅可以查看当前正在发生的台风实况,还可以查看已发生过的台风的历史路径,如下图所示。

此类网站还有很多,但其他网站没有去仔细研究过,不清楚本文的方法是否通用。
该网站是动态加载的,点击选中某一台风后详细信息才会加载出来。最直接的办法应该是用selenium去模拟浏览器行为进行爬取,但这种方法显然很麻烦。为了偷懒我们先来看看是否可以通过抓包解决。
打开开发者工具的Network界面,选中今年的台风鹦鹉查看相关信息,返回的是图示圈中的两个:

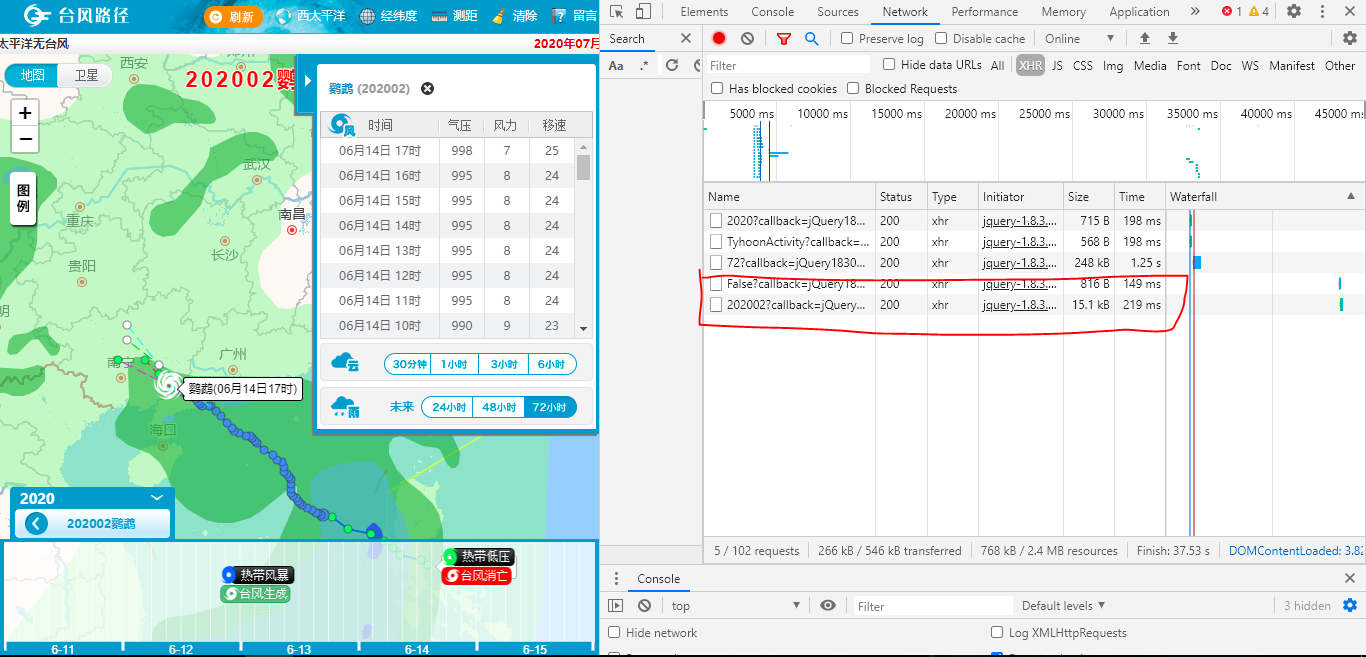
选中这两个包分别查看它们的请求信息,访问两个Request URL后发现第二个包请求的URL(http://typhoon.zjwater.gov.cn/Api/TyphoonInfo/202002?callback=jQuery18309526813185109586_1595992957586&_=1595992964619)里所返回的信息就是我们所需要的历史路径信息。


分析该URL可以发现其中有一个202002,由于选中的台风鹦鹉正好是2020年发生的第二场台风,进而想到修改这一字段进行访问,测试http://typhoon.zjwater.gov.cn/Api/TyphoonInfo/202001,发现返回的信息正是我们想要的,问题解决!
所以爬取该网站2000年至今台风历史路径的思路就是通过访问http://typhoon.zjwater.gov.cn/Api/TyphoonInfo/+年份和台风次序来返回台风的路径信息,然后通过正则表达式匹配所需的字段,完整代码如下:
import requests import json import pymysql h = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36', 'Referer':'http://typhoon.zjwater.gov.cn/'} def parse_typhoon(ty_json): centerlat = ty_json[0]['centerlat'] centerlng = ty_json[0]['centerlng'] enname = ty_json[0]["enname"] endtime = ty_json[0]["endtime"] name = ty_json[0]["name"] #这里数据用的是数据库存的,表是提前建立好的 #连接数据库 conn = pymysql.connect(host='localhost', user='root', password='*****',db='******') mycursor = conn.cursor() for point in ty_json[0]['points']: lat = point['lat'] lng = point['lng'] movedirection = point["movedirection"] movespeed = point["movespeed"] power = point["power"] pressure = point["pressure"] speed = point["speed"] strong = point["strong"] sql = "INSERT INTO typhoon (centerlat,centerlng,name,lng,lat,movedirection,movespeed,power,pressure,speed,strong, endtime, enname) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)" params = (centerlat, centerlng, name, lng, lat, movedirection, movespeed, power, pressure, speed, strong, endtime, enname) mycursor.execute(sql, params) conn.commit() for year in range(2000, 2021): t = 1 url = 'http://typhoon.zjwater.gov.cn/Api/TyphoonInfo/'+str(year)+'01' req = requests.get(url, headers=h) ty_json = json.loads(req.text) while ty_json[0]['centerlat']: parse_typhoon(ty_json) print(str(year) + '第' + str(t) + '个台风插入完成') t += 1 if t < 10: num = '0' + str(t) else: num = str(t) url = 'http://typhoon.zjwater.gov.cn/Api/TyphoonInfo/' + str(year) + num req = requests.get(url, headers=h) ty_json = json.loads(req.text)