import requests #导入模块
response = requests.get('http://www.baidu.com')
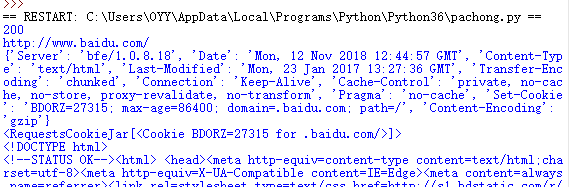
print(response.status_code) #打印状态码
print(response.url) #打印请求url
print(response.headers) #打印头部信息
print(response.cookies) #打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印网页源码
url = 'https://www.baidu.com/' #创建需要爬取网页的地址
headers = {'User-Agent':'Mozilla/5.0(Windows NT 6.1;W...) Genko/201000101 Firefox/59.0'}
response = requests.get(url,headers) #发送网络请求
print(response.content) #以字节流形式打印网页源码
网络超时
for a in range(0,50):
try: #捕获异常
#设置超时时间为0.5s
response = requests.get('https://www.baidu.com/', timeout=0.5 )
print(response.status_code) #打印状态码
except Exception as e: #捕获异常
print('异常'+str(e)) #打印异常信息

代理服务
proxy = {'http':'122.114.31.177:808',
'https':'122.114.31.177:8080'} #设置代理ip对应的端口号
#对需要爬取的网页发送请求
response = requests.get('http://www.mingrisoft.com',proxies=proxy)
print(response.content) #以字节流形式打印出网页源码