kafka介绍及常见问题解答
1.1 主要功能
根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能:
1:It lets you publish and subscribe to streams of records.发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因
2:It lets you store streams of records in a fault-tolerant way.以容错的方式记录消息流,kafka以文件的方式来存储消息流
3:It lets you process streams of records as they occur.可以再消息发布的时候进行处理
1.2 使用场景
1:Building real-time streaming data pipelines that reliably get data between systems or applications.在系统或应用程序之间构建可靠的用于传输实时数据的管道,消息队列功能
2:Building real-time streaming applications that transform or react to the streams of data。构建实时的流数据处理程序来变换或处理数据流,数据处理功能
1.3 详细介绍
1.3.1 消息传输流程

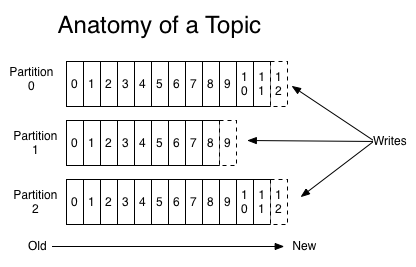
Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic,上图展示了两个producer发送了分类为topic1的消息,另外一个发送了topic2的消息。
Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息
Consumer即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
从上图中就可以看出同一个Topic下的消费者和生产者的数量并不是对应的。
1.3.2 消息存储
数据存储
- 压缩与解压缩
- 消息压缩指两块,一是单条数据的压缩,二是批量数据的压缩
- 单条数据的压缩指将数据序列化为二进制
- 批量数据的压缩指将多条消息合并为1个消息集,共享消息头(比如消息数量,压缩格式等),提高吞吐量
- 压缩式发生在生产者端,生产者通过缓存机制和批量提交机制,一次性发送多条消息给kafka
- 当生产者压缩格式与服务端需要的压缩格式不一致时,服务端会发生解压缩和重压缩的步骤,带来的影响是服务端需要使用jvm内存来完成这一步操作,影响写入效率
- 解压缩的步骤发生在消费者端
- 存储形式是什么样的?
- 以文件的方式存储,数据文件是.log结尾
- 数据内容为原封不动的生产端压缩过后的数据
- kafka通过mmap+write的形式,写系统缓存(page cache),由系统控制刷入磁盘,一致性及可用性由副本和ack机制保证
- 是否可更改?
- 与其他消息队列不同,kafka不允许对已有数据进行更改,消息消费过后也不会被删除
- 日志文件多了怎么办?
- 通过配置过期删除策略,删除过期的文件
- offset机制
- offset即位移,指的是消息在文件中的位置,每个分区内单独递增,主要用于副本同步和消费者消费位置管理
分区
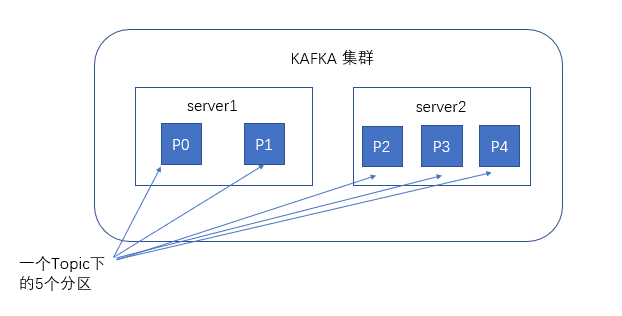
- 什么是分区?
- 分区指的是消息保存在服务端的不同位置,单机下是分文件,集群下是分机器
- 为什么需要分区机制?
- 分区是为了做负载均衡和横向扩容
- 分多少个合适?
- 一般而言,分区需要根据数据量决定,数据越多,分区越多,一般而言,日均百万级的数据,3个分区就够了
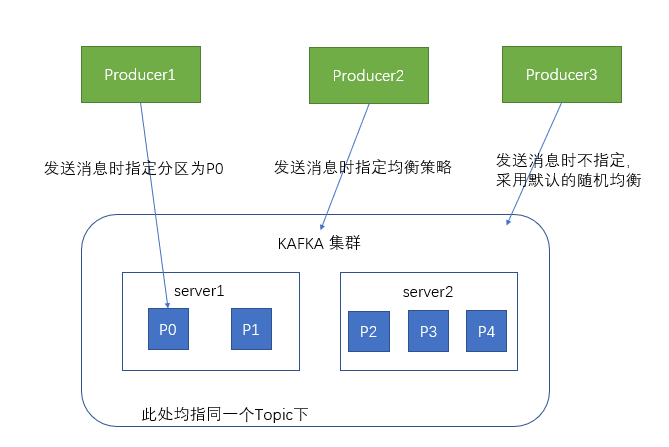
- 消息会发到哪个分区去?
- 跟分区策略相关,包括指定分区,hash分区,轮循分区(默认),自定义分区
- 消息发送到哪个分区是由生产者决定的,每个生产者会缓存所有的分区信息
副本

- 什么是副本?
- 副本是kafka为了保证数据不丢失引入的机制
- 一个topic有几个副本?
- 一个topic的每个分区都有多个副本,由创建topic时的参数replicationFactor决定
- leader与follower机制
- 一个topic内的多个副本中,一个为leader,其他的都为follower,基于zookeeper的节点加锁,成功创建节点的为leader
- leader副本控制整个集群的读写请求,生产者端缓存了该topic下所有分区及副本的信息,只会往leader发,如果发到了follower节点,会重新找leader节点
- follower定时向leader发起同步请求,同步的依据是offset
- 怎么判断follower与leader同步上了
- 通过ISR(IN-SYNC-REPLICA)副本机制,实际上是存储在zk里面的节点数据
- replica.log.max.messages,最大消息位置差距,follower副本通过offset同步数据,判断该offset和当前leader节点的结尾offset可得
- replica.log.time.max.ms,最大同步时间,follower上次发起同步的时间和当前时间比较可得
- 什么时候选leader?
- 分区数量变化
- 原leader宕机
- 哪些副本可以作为leader?
- ISR中的所有服务都可作为leader,谁先往zk中写入数据,谁就是leader
- ISR副本全挂了怎么办?unclean选举,带来的问题是数据丢失
- 为什么不能主写从读?
- 主写从读机制存在的目的就是为了负载均衡和分流,比如,终端管理平台的终端交互侧作为主库,后台管理测用从库
- 主写从读带来的问题就是数据的延迟和不一致,比如连到A从库时有数据,A宕机,连到B从库(还未同步到),发现没有那条数据
- 分区机制带来的负载均衡比主写从读更有效
索引
- kafka索引是什么
- kafka索引是一个文件,以.index结尾
- kafka索引有两种,offset索引和timestamp索引
- kafka索引是稀疏索引,类似于数组的结构,每个索引项指向日志中的一条记录,通过二分查找找到区间,再遍历日志记录找到数据
2.1 生产者
- 怎么算写入成功?
- 因为批量提交的存在,调用producer的send方法后并不说明发送成功,需要注册回调方法判断是否成功
- ack机制,producer端可配置acks, 0:消息发出去了就成功,1:leader写入了就成功,all:所有ISR写入成功才成功
3.1 消费者

- 消费分组
- 消费者以组为组织结构,不同group的消费者隔离
- 在一个group中,一个分区只能给一个消费者消费,一个消费者可以消费多个分区
- 怎么决定我该消费哪个分区?
- 同一个组中,第一个连接到kafka集群(joinGroup)的消费者自动成为消费者组的leader
- kafka把所有的topic分区及消费者信息都发送给这个leader,这个leader会把分区分配信息发送给kafka
- 其他消费者syncGroup时会获取到自己应该消费的分区信息
- 消费到哪了?
- 消费者通过offset维护当前消费的位置
- offset保存位置?
- 老版本offset保存在zk中,一个topic节点下有一个group,一个group下有每个分区的offset
- 新版本offset保存在_consumer_offsets这个topic下
- 手动管理,druid就是手动管理,自己保存在数据库
- 什么时候提交offset?
- autoCommit,消费端默认每隔100ms提交一次offset,存在重复消费的可能性
- 手动管理,可以根据消费进度,保证精确一次,flink里的kafka连接器就是这样的
4.1 kafka为什么这么快
- 日志格式:二进制格式,发送端压缩,接收端解压缩
- 顺序IO:只追加写,尤其指mmap(日志文件映射到内存),操作系统一次性刷新到磁盘
- 批量提交: 提高吞吐量,不需要那么多线程处理
- 批量压缩:减少数据量
- 廉价的消费者:主要指通过offset读取,不更改日志文件
- 未刷新的缓冲写入,指mmap
- 客户端优化:分区策略,压缩,生产者直接发给主节点
- 零拷贝:主要指数据文件发送给消费者时,通过sendfile调用直接发给网络socket,不用加载到jvm用户空间
- 避免垃圾收集(通道,原生缓冲区,页面缓存,直接内存的使用之类)
- 分区机制