python 爬虫
爬虫:对网络数据提取的一种艺术手法
一个正常的爬虫流程是什么样子?
1、将代码伪装成一个用户正常操作使用的浏览器
2、利用伪装代码向服务器发送请求,并成功接受返回结果
3、分析返回结果,提取数据
4、重复2-3,直到达成目的
那么该如何伪装代码?
如何判断伪装代码是否成功?
在大量重复提交测试中,伪装的代码是否能成功?
遇到了重定向,返回结果是否为自己所需要的?
静态页面与动态页面所需要的伪装方式是否相同?
...
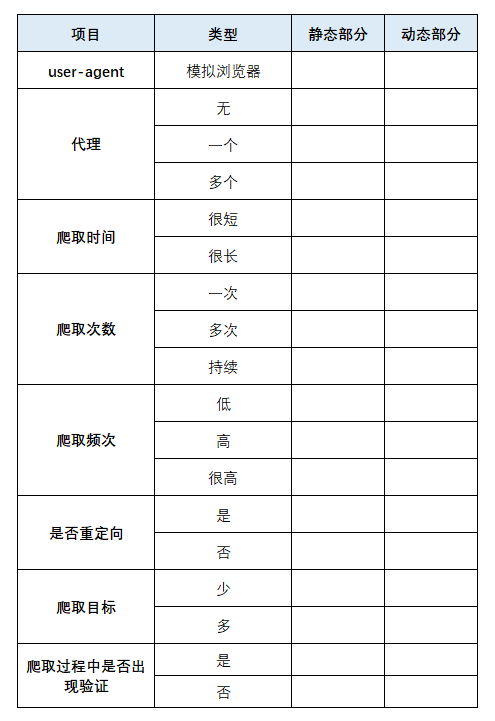
所列部分为目前能想到的情况,持续学习中...
爬虫:对网络数据提取的一种艺术手法
1、将代码伪装成一个用户正常操作使用的浏览器
2、利用伪装代码向服务器发送请求,并成功接受返回结果
3、分析返回结果,提取数据
4、重复2-3,直到达成目的
所列部分为目前能想到的情况,持续学习中...