文字转载:https://www.jianshu.com/p/e4a9e64082ef,转载内容仅供学习
如有侵权,请联系删除
获取url参数 urlparse 和 parse_qs
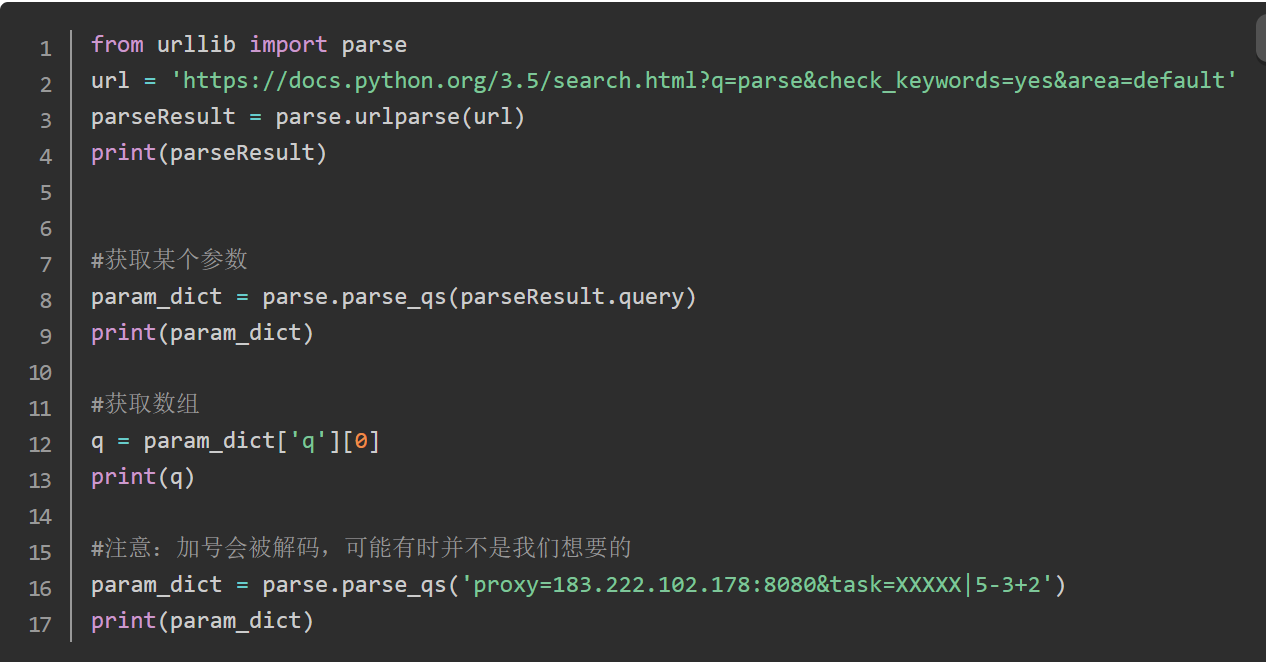
ParseResult(scheme='https', netloc='docs.python.org', path='/3.5/search.html', params='', query='q=parse&check_keywords=yes&area=default', fragment='')
{'q': ['parse'], 'check_keywords': ['yes'], 'area': ['default']}
parse
{'proxy': ['183.222.102.178:8080'], 'task': ['XXXXX|5-3 2']}
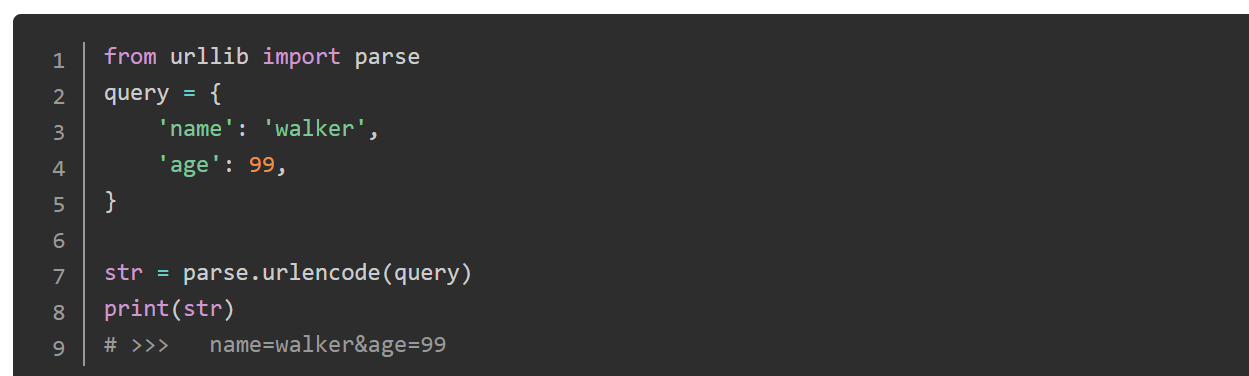
urlencode json 解析成 url参数