This page briefly introduces linear mixed models LMMs as a method for analyzing data that are non independent, multilevel/hierarchical, longitudinal, or correlated. We focus on the general concepts and interpretation of LMMS, with less time spent on the theory and technical details.
Background
Linear mixed models are an extension of simple linear models to allow both fixed and random effects, and are particularly used when there is non independence in the data, such as arises from a hierarchical structure. For example, students could be sampled from within classrooms, or patients from within doctors.
When there are multiple levels, such as patients seen by the same doctor, the variability in the outcome can be thought of as being either within group or between group. Patient level observations are not independent, as within a given doctor patients are more similar. Units sampled at the highest level (in our example, doctors) are independent. The figure below shows a sample where the dots are patients within doctors, the larger circles.

There are multiple ways to deal with hierarchical data. One simple approach is to aggregate. For example, suppose 10 patients are sampled from each doctor. Rather than using the individual patients’ data, which is not independent, we could take the average of all patients within a doctor. This aggregated data would then be independent.
Although aggregate data analysis yields consistent and effect estimates and standard errors, it does not really take advantage of all the data, because patient data are simply averaged. Looking at the figure above, at the aggregate level, there would only be six data points.
Another approach to hierarchical data is analyzing data from one unit at a time. Again in our example, we could run six separate linear regressions—one for each doctor in the sample. Again although this does work, there are many models, and each one does not take advantage of the information in data from other doctors. This can also make the results “noisy” in that the estimates from each model are not based on very much data
Linear mixed models (also called multilevel models) can be thought of as a trade off between these two alternatives. The individual regressions has many estimates and lots of data, but is noisy. The aggregate is less noisy, but may lose important differences by averaging all samples within each doctor. LMMs are somewhere inbetween.
Beyond just caring about getting standard errors corrected for non independence in the data, there can be important reasons to explore the difference between effects within and between groups. An example of this is shown in the figure below. Here we have patients from the six doctors again, and are looking at a scatter plot of the relation between a predictor and outcome. Within each doctor, the relation between predictor and outcome is negative. However, between doctors, the relation is positive. LMMs allow us to explore and understand these important effects.

Random Effects
The core of mixed models is that they incorporate fixed and random effects. A fixed effect is a parameter that does not vary. For example, we may assume there is some true regression line in the population, β, and we get some estimate of it, β^. In contrast, random effects are parameters that are themselves random variables. For example, we could say that β is distributed as a random normal variate with mean μμ and standard deviation σ, or in equation form:
β∼N(μ,σ)β∼N(μ,σ)
This is really the same as in linear regression, where we assume the data are random variables, but the parameters are fixed effects. Now the data are random variables, and the parameters are random variables (at one level), but fixed at the highest level (for example, we still assume some overall population mean, μ ).
Theory of Linear Mixed Models
y=Xβ+Zu+εy=Xβ+Zu+ε
Where y is a N×1 column vector, the outcome variable; X is a N×p matrix of the p predictor variables; β is a p×1 column vector of the fixed-effects regression coefficients (the ββs); ZZ is the N×qJN×qJ design matrix for the qq random effects and JJ groups; uu is a qJ×1qJ×1 vector of qq random effects (the random complement to the fixed β)β) for JJ groups; and εε is a N×1N×1 column vector of the residuals, that part of yy that is not explained by the model, Xβ+ZuXβ+Zu. To recap:

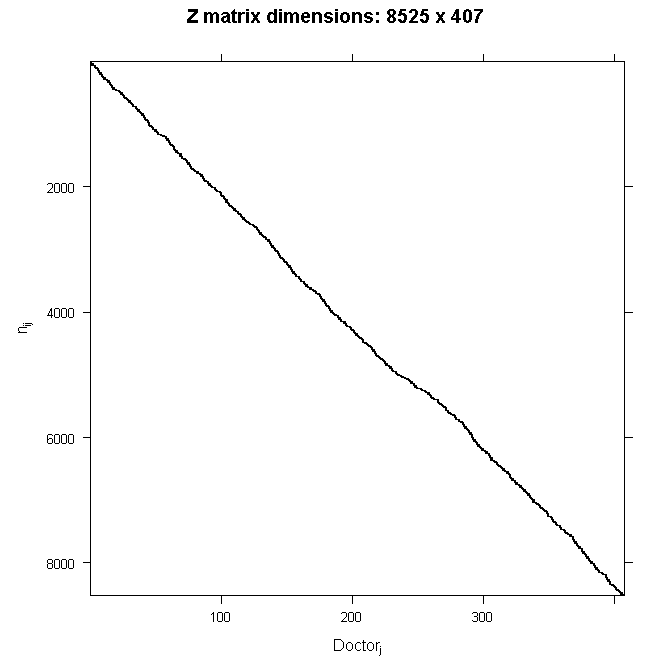
To make this more concrete, let’s consider an example from a simulated dataset. Doctors (J=407) indexed by the j subscript each see nj patients. So our grouping variable is the doctor. Not every doctor sees the same number of patients, ranging from just 2 patients all the way to 40 patients, averaging about 21. The total number of patients is the sum of the patients seen by each doctor

In our example, N=8525 patients were seen by doctors. Our outcome, y is a continuous variable, mobility scores. Further, suppose we had 6 fixed effects predictors, Age (in years), Married (0 = no, 1 = yes), Sex (0 = female, 1 = male), Red Blood Cell (RBC) count, and White Blood Cell (WBC) count plus a fixed intercept and random intercept for every doctor. For simplicity, we are only going to consider random intercepts. We will let every other effect be fixed for now. The reason we want any random effects is because we expect that mobility scores within doctors may be correlated. There are many reasons why this could be. For example, doctors may have specialties that mean they tend to see lung cancer patients with particular symptoms or some doctors may see more advanced cases, such that within a doctor, patients are more homogeneous than they are between doctors. To put this example back in our matrix notation, for the njnj dimensional response yj for doctor j we would have:

and by stacking observations from all groups together we would have:

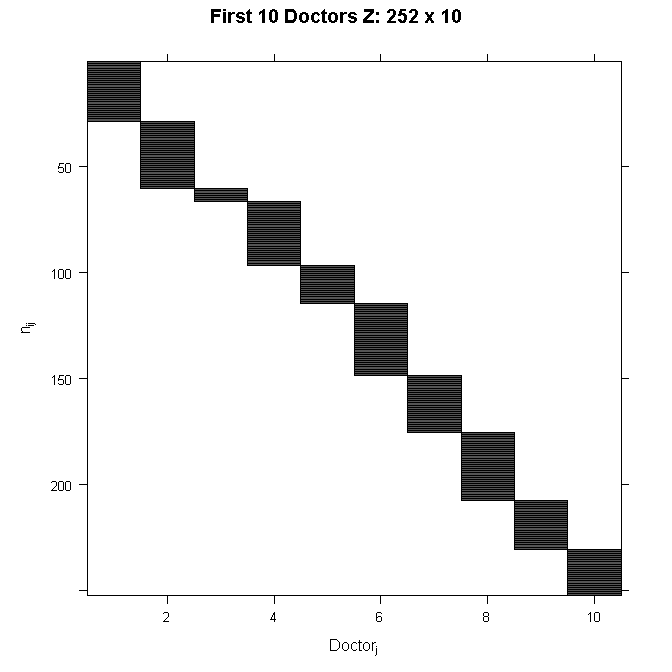
Because Z is so big, we will not write out the numbers here. Because we are only modeling random intercepts, it is a special matrix in our case that only codes which doctor a patient belongs to. So in this case, it is all 0s and 1s. Each column is one doctor and each row represents one patient (one row in the dataset). If the patient belongs to the doctor in that column, the cell will have a 1, 0 otherwise. This also means that it is a sparse matrix (i.e., a matrix of mostly zeros) and we can create a picture representation easily. Note that if we added a random slope, the number of rows in Z would remain the same, but the number of columns would double. This is why it can become computationally burdensome to add random effects, particularly when you have a lot of groups (we have 407 doctors). In all cases, the matrix will contain mostly zeros, so it is always sparse. In the graphical representation, the line appears to wiggle because the number of patients per doctor varies.
In order to see the structure in more detail, we could also zoom in on just the first 10 doctors. The filled space indicates rows of observations belonging to the doctor in that column, whereas the white space indicates not belonging to the doctor in that column.
If we estimated it, uu would be a column vector, similar to β. However, in classical statistics, we do not actually estimate uu. Instead, we nearly always assume that:
u∼N(0,G)
Which is read: “u is distributed as normal with mean zero and variance G”. Where G is the variance-covariance matrix of the random effects. Because we directly estimated the fixed effects, including the fixed effect intercept, random effect complements are modeled as deviations from the fixed effect, so they have mean zero. The random effects are just deviations around the value in ββ, which is the mean. So what is left to estimate is the variance. Because our example only had a random intercept, G is just a 1×1 matrix, the variance of the random intercept. However, it can be larger. For example, suppose that we had a random intercept and a random slope, then

Because G is a variance-covariance matrix, we know that it should have certain properties. In particular, we know that it is square, symmetric, and positive semidefinite. We also know that this matrix has redundant elements. For a q×q matrix, there are q(q+1)2 unique elements. To simplify computation by removing redundant effects and ensure that the resulting estimate matrix is positive definite, rather than model G directly, we estimate θ (e.g., a triangular Cholesky factorization G=LDL). θθ is not always parameterized the same way, but you can generally think of it as representing the random effects. It is usually designed to contain non redundant elements (unlike the variance covariance matrix) and to be parameterized in a way that yields more stable estimates than variances (such as taking the natural logarithm to ensure that the variances are positive). Regardless of the specifics, we can say that
G=σ(θ)
In other words, GG is some function of θθ. So we get some estimate of θθ which we call ^θθ^. Various parameterizations and constraints allow us to simplify the model for example by assuming that the random effects are independent, which would imply the true structure is

The final element in our model is the variance-covariance matrix of the residuals, ε or the variance-covariance matrix of conditional distribution of (y|β;u=u)(y|β;u=u). The most common residual covariance structure is

where II is the identity matrix (diagonal matrix of 1s) and σ2ε is the residual variance. This structure assumes a homogeneous residual variance for all (conditional) observations and that they are (conditionally) independent. Other structures can be assumed such as compound symmetry or autoregressive. The GG terminology is common in SAS, and also leads to talking about G-side structures for the variance covariance matrix of random effects and R-side structures for the residual variance covariance matrix.
So the final fixed elements are y, X, Z, and ε. The final estimated elements are β^, θ^, and R^. The final model depends on the distribution assumed, but is generally of the form:
(y|β;u=u)∼N(Xβ+Zu,R)
We could also frame our model in a two level-style equation for the ii-th patient for the jj-th doctor. There we are working with variables that we subscript rather than vectors as before. The level 1 equation adds subscripts to the parameters ββs to indicate which doctor they belong to. Turning to the level 2 equations, we can see that each β estimate for a particular doctor, βpj, can be represented as a combination of a mean estimate for that parameter, γp0γp0, and a random effect for that doctor, (upj). In this particular model, we see that only the intercept (β0jβ0j) is allowed to vary across doctors because it is the only equation with a random effect term, (u0ju0j). The other βpjβpj are constant across doctors.