本篇随笔有许多细节尚不明确(比如DMA和mmap以及sendfile的原理),因此仅供参考和简单理解使用,但是后面会不断补充和修正完善
基本介绍
1. 零拷贝是网络编程的关键,很多性能优化离不开它;
2. 在Java程序中,常用的零拷贝有mmap(内存映射)和sendfile
以一个简单IO读写程序介绍其中存在的问题
package org.scaventz.nio.mine; import java.io.File; import java.io.IOException; import java.io.RandomAccessFile; import java.net.ServerSocket; import java.net.Socket; public class ZeroCPY { public static void main(String[] args) throws IOException { File file = new File("D:/test.txt"); RandomAccessFile raf = new RandomAccessFile(file, "rw"); byte[] bytes = new byte[(int) file.length()]; raf.read(bytes); // 将读到的数据写给客户端 Socket socket = new ServerSocket().accept(); socket.getOutputStream().write(bytes); } }

对上面代码数据拷贝过程的分析:
1. 【DMA copy】:通过DMA(Direct Memory Access)将数据从Hard Drive拷贝到【内核空间】Kernel buffer,DMA拷贝时不需要CPU参与运算
2. 【CPU copy】:将数据从【内核空间】kernel buffer拷贝到【用户空间】的user buffer
3. 【CPU copy】:将数据从【用户空间】的user buffer拷贝到【内核空间】的socket buffer
4. 【DMA copy】:将数据从【内核空间】的socket buffer拷贝到protocol engine
性能:所以传统的网络IO,经过了
- 2次CPU copy + 2次 DMA copy
- 2次切换(不算开始时进入内核态那一次)
mmap 优化
mmp通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据(对应于下图的shared)。这样,在进行网络传输时,就可以减少内核空间到用户空间的拷贝
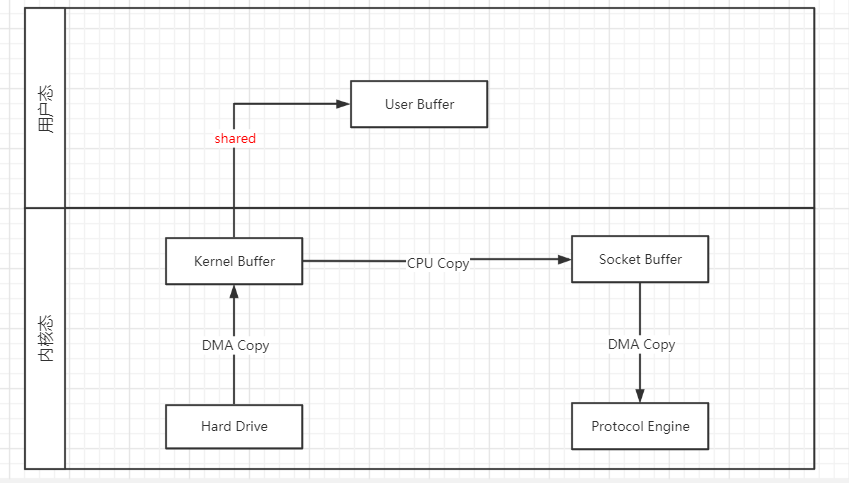
性能:
- 1次CPU copy + 2次DMA copy
- 2次上下文切换(存疑,待详细了解mmap原理细节后再回来订正)
sendFile优化(Linux 内核 2.1版本)
Linux2.1版本提供了sendFile函数,数据根本不经过用户态,直接从内核缓冲区进入到Socket Buffer,同时由于和用户态完全无关,就减少了一次上下文切换。
示意图如下
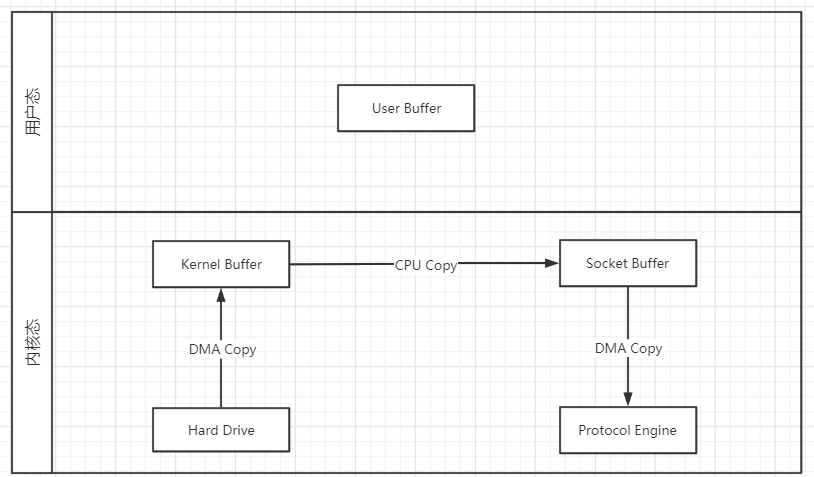
性能:
1. 还是存在1次CPU copy和2次DMA copy(DMA无可避免,0拷贝指无CPU拷贝)
2. 不存在上下文切换
sendFile优化(Linux 内核 2.4版本)
Linux在2.4版本做了一些优化,避免了从内核缓冲区拷贝到socket buffer的操作,直接从kernel buffer拷贝到协议栈,从而再一次减少了数据拷贝
示意图如下

性能:
- 几乎0 CPU copy,仍然有一些length,offset等少量数据设计到拷贝到socket buffer,但是拷贝的信息很少,消耗很低,可以忽略。
- 2次DMA拷贝
- 不存在上下文切换