序列化模块:json模块和pickle模块
前提:
试想一下,你没有这种需求,想把一个字典或者列表直接存储起来,等下次再用,但是这些数据类型是存储在内存中的,程序结束后内存就会被释放了。通过之前学习的内容,如果想把数据永久地存储下来,可以存储到文件里面,可是文件中只能储存字符串类型,或者那么你的这种需求能够实现吗?
你灵机一动,想到了强大的eval()内置函数,通过eval就能够操作字符串啊。
stu = {'name':'he','age':23}
ret = str(stu) #把字典转换为字符串类型
print(eval(ret),type(eval(ret)))
》》》
{'name': 'he', 'age': 23} <class 'dict'>
但是强大的eval()的安全性却得不到保证,如果在文件中读取出来的是一条类似于'rm /'之类的命令,后果不堪设想。
所以在三个场景中是不建议使用eval函数的:
1.用户输入的时候 2.文件读入的时候 3.网络传输的时候
这个时候要完成你的需求,就需要用到新的概念:序列化。
序列化:
将一个对象从内存中转换为可存储(字符串类型)或者可传输(bytes)类型的过程,就叫做序列化过程。在python中叫做pickling,通俗点说,就是序列化就是将其他数据类型转换为字符串/bytes类型的过程。
为什么要用序列化:
(1)持久化数据类型
(2)跨平台进行交互。不同的编程语言都用协商好的序列化格式,那么便能打破平台/语言之间的限制,实现跨平台数据交互。
json模块
json格式在各个语言之间都是通用的序列化格式。在json格式中,所有的字符串都是""双引号的。
json的优点:
所有的数据类型都是各个语言通用的。在各个编程语言中都支持。
json的缺点:
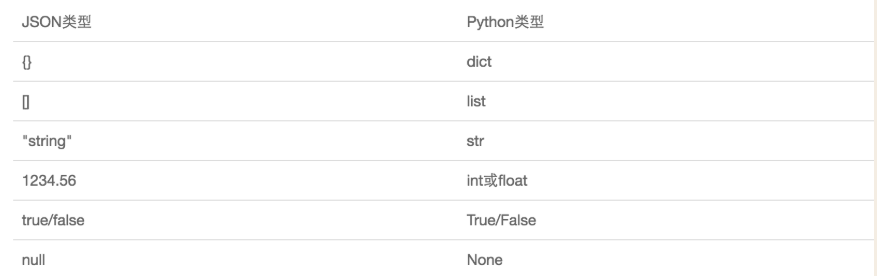
1. json只是支持非常少的数据类型
2. 对数据类型的约束十分严格。
(1)字典中的key必须是字符串。
(2)json只支持列表,字典,数值,字符串,布尔值。
json的用法:
# 序列化过程--json.dumps() stu = {'name':'he','age':23,1:('hello','python')} stu_json = json.dumps(stu) print(stu_json,type(stu_json)) >>> # 得到序列化后的结果,确实是字符串类型,但是也体现了json对数据类型的严苛要求 # 字典中的元素被转化为了列表形式 {"name": "he", "age": 23, "1": ["hello", "python"]} <class 'str'> #反序列化过程--json.loads() stu = json.loads(stu_json) print(stu,type(stu)) >>> # 反序列化得到了原来的字典类型,但是还是json格式的约束,原字典中的元组变成了列表 # WTF...这种更改了数据类型的操作,显示是不能令python开发者满意的 {'name': 'he', 'age': 23, '1': ['hello', 'python']} <class 'dict'>
如果想把数据类型直接序列化到一个文件中,json模块也为我们提供了两个方法:json.dump()和json.load()
# 序列化进文件中
import json
f = open('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close()
f = open('json_file')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
如果文件中存在很多数据,但是load方法只能去第一个数据,这种情况下,需要怎么办?这种情况下,就只能通过打开文件,通过loads()方法读取。
import json
with open('file_path','r') as f:
for line in f:
ret = json.loads(line.strip())
print(ret)
pickle模块
由于json格式对python数据类型的支持不是那么完美,如果只是在python程序之间交互,使用pickle模块的支持性会更好。但是不足之处就是,pickle只是适用于python语言。

pickle的优点:
(1)pickle支持python中的所有数据类型
(2)pickle会把数据类型序列化成bytes类型
pickle的缺点:
(1)pickle只适用于python。
pickle模块的使用:
import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()
#-------------------------反序列化
import pickle
f=open('序列化对象_pickle','rb')
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data['age'])