业务背景
写任何工具都不能脱离实际业务的背景。开始这个项目的时候是因为现有的项目中数据分布太零碎,零零散散的分布在好几个数据库中,没有统一的数据库来收集这些数据。这种情况下想做一个大而全的会员中心系统比较困难。(这边是一个以互联网保险为中心的项目,保单,会员等数据很零散的储存在好几个项目之中,并且项目之间的数据基本上是隔离的)。
现有的项目数据库是在腾讯云中储存,虽然腾讯提供了数据同步功能,但是这样必须要表结构相同才行,并不符合我们的需求。所以需要自行开发。
项目在这里:https://github.com/hjx601496320/miner。
更新:
这个项目我删掉了,git上现在找不到,新的项目在这里:
https://github.com/hjx601496320/plumber
去掉了对canal的依赖, 使用起来更加的方便~~
需求
1:需要能灵活配置。
2:实时数据10分钟内希望可以完成同步。
3:来源数据与目标数据可能结构,字段名称不同。
4:增删改都可以同步。
技术选择
这个任务交给了我和另外一个同事来做。
同事的
同事希望可以通过ETL工具Kettle来做,这个东西我没有研究过,是同事自己在研究。具体过程不是很清楚,但是最后是通过在mysql中设置更新,修改,删除的触发器,然后在Kettle中做了一个定时任务,实现了数据同步的功能,初步测试符合需求。但是必须要在数据库中设置触发器,并且会有一个临时表,这一点我个人不是很喜欢。
我的
我是本着能自己写就自己写的原则,准备自己写一个。刚开始使用的是定时任务比较两个库的数据差别,然后再同步数据。但是经过一定的数据测试后,发现在数据量大的时候,定时任务中的上一个任务没有执行完毕,下一个任务就又开始了。这样造成了两边数据不一致。最终这个方案废弃了。
后来通过研究,发现mysql的数据操作会记录在binlog中,这时就有了新的方案。可以通过逐行获取binlog信息,经过解析数据后,同步在目标库中。
既然有了方案,那么就开始做吧。
开始尝试:1
首先要打开数据库的binlog功能,这一步比较简单,修改mysql的配置文件:/etc/mysql/mysql.conf.d/mysqld.cnf,添加:
server-id = 1 log_bin = /var/log/mysql/mysql-bin.log expire_logs_days = 10 max_binlog_size = 100M binlog_format = ROW
然后重启mysql 就好了,具体每个参数的意思,搜索一下就好了。这时候随意的对某一个数据库中的表做一下增删改,对应的日志就会记录在/var/log/mysql/这个文件夹下了。我们看一下这个文件夹里的东西:

这里的文件是没有办法正常查看的,需要使用mysql提供的命令来查看,命令是这个样子的:
1:查看 mysqlbinlog mysql-bin.000002 2:指定位置查看 mysqlbinlog --start-position="120" --stop-position="332" mysql-bin.000002
因为我们现在的binlog_format指定的格式是ROW(就在上面写的,还记得吗?),所谓binlog文件的内容没有办法正常查看,因为他是这个样子的:

这时,我们需要:
对输出进行解码 mysqlbinlog --base64-output=decode-rows -v mysql-bin.000001
这时候,显示的结果就变成了:
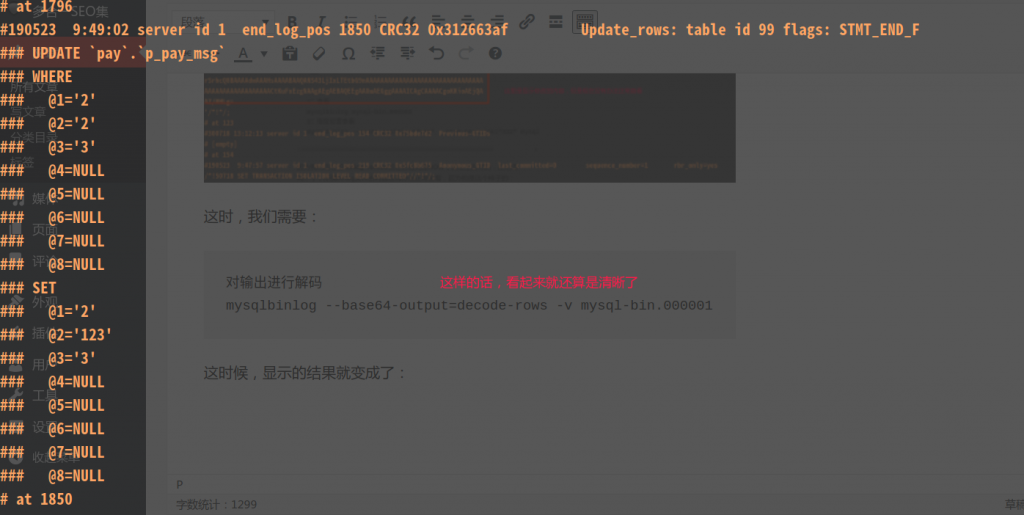
虽然还不是正常的sql,但是好赖是有一定的格式了。
but自己来做解析的话还是很麻烦,so~放弃这种操作。
继续尝试:2
经过再次研究后,发现数据库中执行sql也是可以查看binlog的。主要有如下几条命令:
重置binlog reset master; 查看binlog的配置 show variables like '%binlog%'; 查看所有的binlog show binary logs; 查看正在写入的binlog show master status; 查看指定binlog文件 show binlog events in 'mysql-bin.000001'; 查看指定binlog文件,并指定位置 show binlog events in 'mysql-bin.000001' from [pos] limit [显示多少条];
按照上面的命令执行结果为:
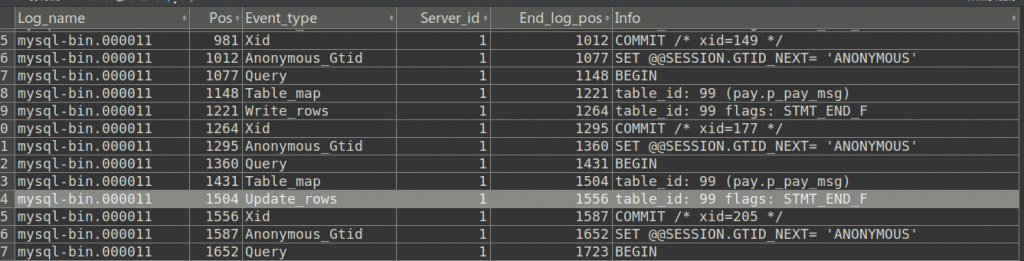
发现sql还是不能正常显示。这里的原因应该是binlog_format配置的原因。将其修改为 binlog_format=Mixed后,完美解决。经过数据库中一通增删改后,显示的sql类似这样:
use `pay`; /* ApplicationName=DataGrip 2018.2.5 */ UPDATE `pay`.`p_pay_log` t SET t.`mark_0` = 'sdfsdf' WHERE t.`id` LIKE '342' ESCAPE '#'
现在似乎已经可以开始写数据同步了,只要在启动的时候获取当正在使用的是哪一个日志文件,记录binlog的位置,然后一点一点向下执行,解析sql就好了。但是在这个过程中,我发现阿里巴巴有一款开源的软件可以用。就是标题上说道的:canal。看了一下网站上的介绍,简直美滋滋。
它的文档和代码地址在这里:https://github.com/alibaba/canal,大家可以看一下。现在就准备用这个来完成我所需要的功能。
正式开始写
首先看一下介绍,canal是需要单独运行一个服务的,这个服务具体的配置还是比较简单的。它的作用我自己理解就是监控binlog,然后根据自己的需要获取binlog中一定量的数据。这个数据是经过处理的,可以比较方便的知道里面的具体信息。比如那些数据发生了变动,每列数据的列名是什么,变动前和变动后的值是啥之类的。那么开始。
1:我的想法
1):项目启动的时候,开启canal的链接,以及初始化一些配置。
@Bean
public CanalConnector canalConnector() {
CanalConnector connector = CanalConnectors.newSingleConnector(
//对应canal服务的链接
new InetSocketAddress(canalConf.getIp(), canalConf.getPort()),
//链接的目标,这里对应canal服务中的配置,需要查阅文档
canalConf.getDestination(),
//不知道是什么用户,使用“”
canalConf.getUser(),
//不知道是什么密码,使用“”
canalConf.getPassword()
);
return connector;
}
2):先开启一个线程,里面写一个死循环,用于从canal的服务中获取binlog中的消息。这个消息类是:com.alibaba.otter.canal.protocol.Message。
Message message = connector.getWithoutAck(100); connector:canal链接的实例化对象。 connector.getWithoutAck(100):从连接中获取100条binlog中的数据。
3):取出Message中的事件集合,就是binlog中的每一条数据。将类型为增删改的数据取出,之后每一条数据放在一个线程中,用线程池去执行它。
List<Entry> entries = message.getEntries(); message.getEntries():从链接中获取的数据集合,每一条代表1条binlog数据
4):在每一个线程中,取出Entry中的数据,根据其类型拼接各种sql,并执行。
Header header = entry.getHeader();
获取发生变化的表名称,可能会没有
String tableName = header.getTableName();
获取发生变化的数据库名称,可能会没有
String schemaName = header.getSchemaName();
//获取事件类型
EventType eventType = rowChange.getEventType();
这里我们只是用其中的三种类型:
EventType.DELETE 删除
EventType.INSERT 插入
EventType.UPDATE 更新
//获取发生变化的数据
RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
//遍历其中的数据
int rowDatasCount = rowChange.getRowDatasCount();
for (int i = 0; i < rowDatasCount; i++) {
//每一行中的数据
RowData rowData = rowChange.getRowDatas(i);
}
//获取修改前的数据
List<Column> before = rowData.getBeforeColumnsList();
//获取修改后的数据
List<Column> after = rowData.getAfterColumnsList();
Column中有一系列方法,比如是否发生修改,时候为key,是否是null等,就不在细说了。
2:万事具备,可以开始写了
1):这里先写一个线程,用于不停的从canal服务中获取消息,然后创建新的线程并让其处理其中的数据。代码如下:
@Override
public void run() {
while (true) {
//主要用于在链接失败后用于再次尝试重新链接
try {
if (!run) {
//打开链接,并设置 run=true
startCanal();
}
} catch (Exception e) {
System.err.println("连接失败,尝试重新链接。。。");
threadSleep(3 * 1000);
}
System.err.println("链接成功。。。");
//不停的从CanalConnector中获取消息
try {
while (run) {
//获取一定数量的消息,这里为线程池数量×3
Message message = connector.getWithoutAck(batchSize * 3);
long id = message.getId();
//处理获取到的消息
process(message);
connector.ack(id);
}
} catch (Exception e) {
System.err.println(e.getMessage());
} finally {
//如果发生异常,最终关闭连接,并设置run=false
stopCanal();
}
}
}
void process(Message message) {
List<Entry> entries = message.getEntries();
if (entries.size() <= 0) {
return;
}
log.info("process message.entries.size:{}", entries.size());
for (Entry entry : entries) {
Header header = entry.getHeader();
String tableName = header.getTableName();
String schemaName = header.getSchemaName();
//这里判断是否可以取出数据库名称和表名称,如果不行,跳过循环
if (StringUtils.isAllBlank(tableName, schemaName)) {
continue;
}
//创建新的线程,并执行
jobList.stream()
.filter(job -> job.isMatches(tableName, schemaName))
.forEach(job -> executorService.execute(job.newTask(entry)));
}
}
这里的jobList是我自己定义List<Job>,代码如下:
package com.hebaibai.miner.job;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.google.protobuf.InvalidProtocolBufferException;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.jdbc.core.JdbcTemplate;
import static com.alibaba.otter.canal.protocol.CanalEntry.Entry;
@Slf4j
@Data
public abstract class Job {
/**
* 数据库链接
*/
protected JdbcTemplate jdbcTemplate;
/**
* 额外配置
*/
protected JSONObject prop;
/**
* 校验目标是否为合适的数据库和表
*
* @param table
* @param database
* @return
*/
abstract public boolean isMatches(String table, String database);
/**
* 实例化一个Runnable
*
* @param entry
* @return
*/
abstract public Runnable newTask(final Entry entry);
/**
* 获取RowChange
*
* @param entry
* @return
*/
protected CanalEntry.RowChange getRowChange(Entry entry) {
try {
return CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
return null;
}
}
jobList里面放的是Job的实现类。
3:写一个Job的实现类,并用于同步表,并转换字段名称。
因为需求中要求两个同步的数据中可能字段名称不一致,所以我写了一个josn用来配置两个表的字段对应关系:
别的配置
。。。
"prop": {
//来源数据库
"database": "pay",
//来源表
"table": "p_pay_msg",
//目标表(目标库在其他地方配置)
"target": "member",
//字段对应关系
//key :来源表的字段名
//value:目标表的字段名
"mapping": {
"id": "id",
"mch_code": "mCode",
"send_type": "mName",
"order_id": "phone",
"created_time": "create_time",
"creator": "remark"
}
}
。。。
别的配置
下面是全部的代码,主要做的就是取出变动的数据,按照对应的字段名重新拼装sql,然后执行就好了,不多解释。
package com.hebaibai.miner.job;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import static com.alibaba.otter.canal.protocol.CanalEntry.*;
/**
* 单表同步,表的字段名称可以不同,类型需要一致
* 表中需要有id字段
*/
@SuppressWarnings("ALL")
@Slf4j
public class TableSyncJob extends Job {
/**
* 用于校验是否适用于当前的配置
*
* @param table
* @param database
* @return
*/
@Override
public boolean isMatches(String table, String database) {
return prop.getString("database").equals(database) &&
prop.getString("table").equals(table);
}
/**
* 返回一个新的Runnable
*
* @param entry
* @return
*/
@Override
public Runnable newTask(final Entry entry) {
return () -> {
RowChange rowChange = super.getRowChange(entry);
if (rowChange == null) {
return;
}
EventType eventType = rowChange.getEventType();
int rowDatasCount = rowChange.getRowDatasCount();
for (int i = 0; i < rowDatasCount; i++) {
RowData rowData = rowChange.getRowDatas(i);
if (eventType == EventType.DELETE) {
delete(rowData.getBeforeColumnsList());
}
if (eventType == EventType.INSERT) {
insert(rowData.getAfterColumnsList());
}
if (eventType == EventType.UPDATE) {
update(rowData.getBeforeColumnsList(), rowData.getAfterColumnsList());
}
}
};
}
/**
* 修改后的数据
*
* @param after
*/
private void insert(List<Column> after) {
//找到改动的数据
List<Column> collect = after.stream().filter(column -> column.getUpdated() || column.getIsKey()).collect(Collectors.toList());
//根据表映射关系拼装更新sql
JSONObject mapping = prop.getJSONObject("mapping");
String target = prop.getString("target");
List<String> columnNames = new ArrayList<>();
List<String> columnValues = new ArrayList<>();
for (int i = 0; i < collect.size(); i++) {
Column column = collect.get(i);
if (!mapping.containsKey(column.getName())) {
continue;
}
String name = mapping.getString(column.getName());
columnNames.add(name);
if (column.getIsNull()) {
columnValues.add("null");
} else {
columnValues.add("'" + column.getValue() + "'");
}
}
StringBuilder sql = new StringBuilder();
sql.append("REPLACE INTO ").append(target).append("( ")
.append(StringUtils.join(columnNames, ", "))
.append(") VALUES ( ")
.append(StringUtils.join(columnValues, ", "))
.append(");");
String sqlStr = sql.toString();
log.debug(sqlStr);
jdbcTemplate.execute(sqlStr);
}
/**
* 更新数据
*
* @param before 原始数据
* @param after 更新后的数据
*/
private void update(List<Column> before, List<Column> after) {
//找到改动的数据
List<Column> updataCols = after.stream().filter(column -> column.getUpdated()).collect(Collectors.toList());
//找到之前的数据中的keys
List<Column> keyCols = before.stream().filter(column -> column.getIsKey()).collect(Collectors.toList());
//没有key,执行更新替换
if (keyCols.size() == 0) {
return;
}
//根据表映射关系拼装更新sql
JSONObject mapping = prop.getJSONObject("mapping");
String target = prop.getString("target");
//待更新数据
List<String> updatas = new ArrayList<>();
for (int i = 0; i < updataCols.size(); i++) {
Column updataCol = updataCols.get(i);
if (!mapping.containsKey(updataCol.getName())) {
continue;
}
String name = mapping.getString(updataCol.getName());
if (updataCol.getIsNull()) {
updatas.add("`" + name + "` = null");
} else {
updatas.add("`" + name + "` = '" + updataCol.getValue() + "'");
}
}
//如果没有要修改的数据,返回
if (updatas.size() == 0) {
return;
}
//keys
List<String> keys = new ArrayList<>();
for (Column keyCol : keyCols) {
String name = mapping.getString(keyCol.getName());
keys.add("`" + name + "` = '" + keyCol.getValue() + "'");
}
StringBuilder sql = new StringBuilder();
sql.append("UPDATE ").append(target).append(" SET ");
sql.append(StringUtils.join(updatas, ", "));
sql.append(" WHERE ");
sql.append(StringUtils.join(keys, "AND "));
String sqlStr = sql.toString();
log.debug(sqlStr);
jdbcTemplate.execute(sqlStr);
}
/**
* 删除数据
*
* @param before
*/
private void delete(List<Column> before) {
//找到改动的数据
List<Column> keyCols = before.stream().filter(column -> column.getIsKey()).collect(Collectors.toList());
if (keyCols.size() == 0) {
return;
}
//根据表映射关系拼装更新sql
JSONObject mapping = prop.getJSONObject("mapping");
String target = prop.getString("target");
StringBuilder sql = new StringBuilder();
sql.append("DELETE FROM `").append(target).append("` WHERE ");
List<String> where = new ArrayList<>();
for (Column column : keyCols) {
String name = mapping.getString(column.getName());
where.add(name + " = '" + column.getValue() + "' ");
}
sql.append(StringUtils.join(where, "and "));
String sqlStr = sql.toString();
log.debug(sqlStr);
jdbcTemplate.execute(sqlStr);
}
}
项目在这里:https://github.com/hjx601496320/miner。
这个项目我删掉了,git上现在找不到,新的项目在这里:
https://github.com/hjx601496320/plumber
去掉了对canal的依赖, 使用起来更加的方便~~