文件的使用
一、文件的概述
文件是一个存储在辅助存储器上的数据序列,可以包含任何数据内容。概念上,文件是数据的集合和抽象,类似的,函数是程序的集合和抽象,用文件形式组织和表达数据更有效也更为灵活,
二、文件包括两种类型:文本文件和二进制文件。
1.文本文件
一般由单一特定编码的字符组成,如UTF-8编码,内容容易统一展示和阅读。
2.二进制文件
直接由比特0和比特1组成,没有统一字符编码,文件内部数据的组织格式与文件用途有关。
三、文件的打开
<变量名>=open(<变量名>,<打开模式>)
文件的打开模式
| 文件的打开模式 | 含义 |
| 'r' | 只读模式,如果文件不存在,返回异常FileNotFoundError,默认值 |
| ‘w' | 覆盖写模式,文件不存在则创建,存在则完全覆盖 |
| 'x' | 创建写模式,文件不存在则创建,存在则返回异常FileNotFoundError |
| 'a' | 追加写模式,文件不存在则创建,存在则在文件最后追加内容 |
| 'b' | 二进制文件模式 |
| 't' | 文本文件模式,默认值 |
| '+' | 与r/w/x/a一同使用,在原功能基础上增加读写功能 |
注意:'r','w','x','a'可以和'b','t','+'组合使用
例如:打开文本文件模式
text=open('7.1.txt','rt')
打开二进制文件
text=open('7.1.txt','rb')
四、文件的读写
读取
| 操作方法 | 含义 |
| <file>.read(size=-1) | 从文件中读入整个文件内容,如果给出参数,读入前size长度的字符串或者字符流 |
| <file>.readline(size=-1) | 从文件中读入一行内容,如果给出参数,读入该行前size长度的字符串或者字符流 |
| <file>.readlines(hint=-1) | 从文件中读入所有行,以每行为元素形成一个列表如果给出参数,读入hint行 |
写入
| 方法 | 含义 |
| <file>.write(s) | 向文件写入一个字符串或者字符流 |
| <file>.writelines(lines) | 将一个元素全为字符串的列表写入文件 |
| <file>.seel(offset) | 改变当前文件操作指针的位置,offset的值:0--文件开头;1--当前位置;2--文件结尾 |
五、文件的关闭
<变量名>.close()
六、文件的简单应用

1 >>> wj=open('C:\UsersAdministratorDesktopPython文件的打开.txt','rt') #打开文件
2 >>> print(wj.read()) #输出文件内容
3 唐诗宋词元曲
4 >>> wj.close() #关闭文件
5 >>> lp=open('C:\UsersAdministratorDesktopPython文件的打开.txt',"w+") #打开文件的读写模式
6 >>> text=["是中国传统知识"] #将要写入的内容
7 >>> lp.writelines(text) #将文件写入
8 >>> lp.seek(0)
9 0
10 >>> for line in lp: #输出文件内容
11 print(line)
12
13
14 是中国传统知识
15 >>> lp.close() #关闭文件
七,将两个excle文件并存为csv格式文件
代码如下
# -*- coding:utf-8
import pandas as pd
def zhuan1(wenjian, mingcheng, baocun):
grade = pd.read_excel(wenjian, sheet_name=mingcheng)
for i in range(len(grade.index)):
for j in range(1, len(grade.columns)):
if grade.iloc[i, j] == '优秀':#查看第i行第j列
grade.iat[i, j] = 90#修改数据,转变成分数形式
elif grade.iloc[i, j] == '良好':
grade.iat[i, j] = 80
elif grade.iloc[i, j] == '合格':
grade.iat[i, j] = 60
elif grade.iloc[i,j] == '不合格':
grade.iat[i,j] = 60
else:
grade.iat[i, j] = 0
grade.to_csv(baocun)
def zhuan2(wenjian, mingcheng, baocun):
grade = pd.read_excel(wenjian, sheet_name=mingcheng)
Grade = grade.replace("优秀", "90")#替换为分数形式
Grade = Grade.replace("良好", "80")
Grade = Grade.replace("不合格", "60")
Grade = Grade.replace("合格", "60")
Grade = Grade.fillna(value = 0)
Grade.to_csv(baocun)
zhuan2("D:\Python成绩(2).xlsx", "Sheet1", "D:\Python_1.csv")
zhuan1("D:\Python成绩登记信计(1).xlsx", "Sheet1", "D:\Python_2.csv")
结果如图所示
原图:python成绩(2)

转换之后
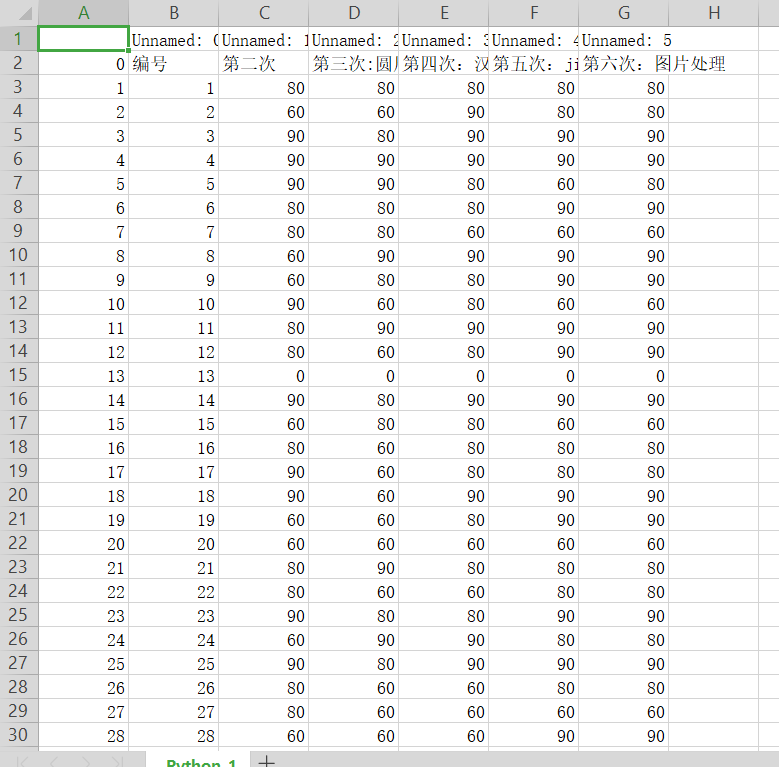
原图:python成绩登记信计(1)
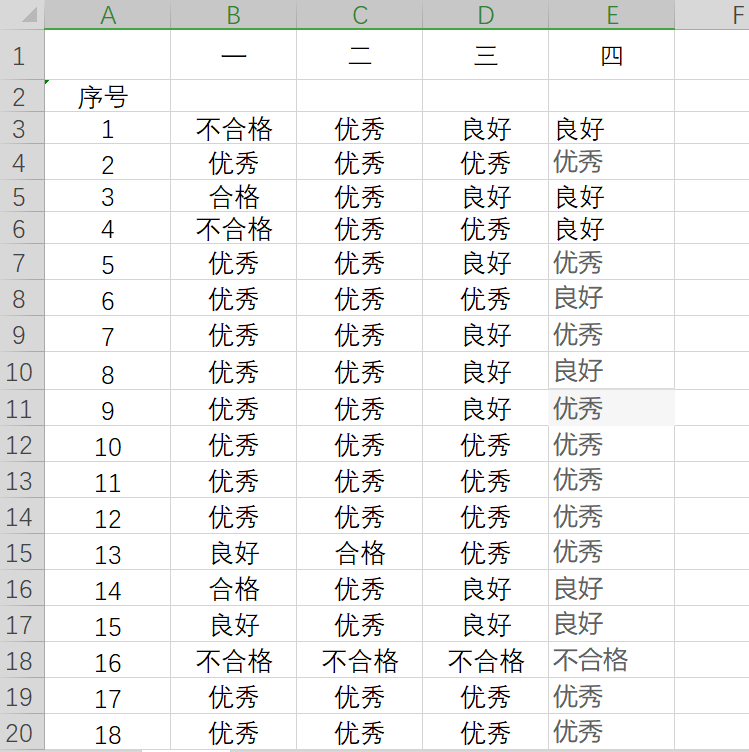
转换之后