决策树是常用的机器学习算法,包括特征选择、决策树的生成以及决策树的剪枝。常用的算法有:ID3、C4.5以及CART。
ID3算法中,特征选择的准则是信息增益,即集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差。
信息增益算法流程:
输入:训练数据集D和特征A;
输出:特征A对数据训练集D的信息增益g(D,A).
(1)计算数据集D的经验熵H(D)
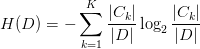
(2)计算特征A对数据集的经验条件熵H(D|A)
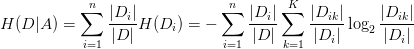
(3)计算信息增益
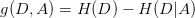
信息增益比:
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题,引入了信息增益比gR(D,A).其定义为信息增益g(D,A)与训练数据集D关于特征A的值的熵 之比,即:
之比,即:

其中, ,n是特征A取值的个数.
,n是特征A取值的个数.
ID3算法流程:
输入:训练数据集D,特征集A,阈值ε.
输出:决策树T.
(1)若D中所有实例属于同一类 ,则T为单结点树,并将类
,则T为单结点树,并将类 作为该结点的类标记,返回T;
作为该结点的类标记,返回T;
(2)若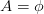 ,则T为单结点树,并将D中实例数最大的类作为该结点的类标记,返回T;
,则T为单结点树,并将D中实例数最大的类作为该结点的类标记,返回T;
(3)否则,按信息增益算法计算A中各特征对D的信息增益,选择信息增益最大的特征 ;
;
(4)如果 的信息增益小于阈值ε,则T为单结点树,并将D中实例数最大的类作为该结点的类标记,返回T;
的信息增益小于阈值ε,则T为单结点树,并将D中实例数最大的类作为该结点的类标记,返回T;
(5)否则,对的每一个可能的值 ,依
,依 将D分割为若干非空子集
将D分割为若干非空子集 ,将
,将 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6)对第i个子结点,以为训练集,以 为特征集,递归地调用步骤(1)-(5),得到子树
为特征集,递归地调用步骤(1)-(5),得到子树 ,返回
,返回 .
.
ID3的缺陷:
(1)ID3没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。这大大限制了ID3的用途。
(2)ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大。如果校正这个问题呢?
(3) ID3算法对于缺失值的情况没有做考虑
(4) 没有考虑过拟合的问题
针对于上述ID3算法的缺陷,又引入了C4.5算法,即采用信息增益比作为特征选择的方式,并解决了ID3的缺点.


上面两张图片取自http://www.cnblogs.com/pinard/p/6050306.html
C4.5算法的缺陷:
(1)由于决策树易发生过拟合,可以采用预剪枝和后剪枝;
(2)在树的生成过程中,需要对数据集多次扫描和排序,因而导致算法的低效.
决策树的剪枝
决策树的剪枝往往是通过极小化决策树整体的损失函数来实现,设树T的叶结点个数为|T|,t是树T的叶结点,该叶结点有 个样本点,其中k类的样本点有
个样本点,其中k类的样本点有 个,k=1,2...K,
个,k=1,2...K, 为叶结点t上的经验熵,
为叶结点t上的经验熵, 为参数,则决策树的损失函数定义为:
为参数,则决策树的损失函数定义为:

其中,经验熵为
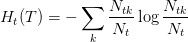
剪枝算法:
输入:生成算法产生的整个树T,参数 ;
;
输出:修剪后的子树 .
.
(1)计算每个结点的经验熵;
(2)递归的从树的叶结点向上回缩;若回缩后的损失函数值小,则进行剪枝;
(3)返回(2),直到不能继续为之,得到损失函数最小的子树.