交叉验证是模型比较选择的一种常用方法,本文对此进行总结梳理。
1.交叉验证的基本思想
交叉验证(cross validation)的基本思想就是重复地利用同一份数据。
2.交叉验证的作用
1)通过划分训练集和测试集,一定程度上减小了过拟合;
2)重复使用数据,尽可能多的从样本集上得到有用的信息。
3.交叉验证的主要方法
3.1 简单交叉验证
简单交叉验证,又称为留出法(hold-out),是指直接将样本集划分成两个互斥的计划,其中一个作为训练集(training set),另外一个作为测试集(testing set)。在训练集中进行学习训练,使用测试集来计算测试误差。
注意:
1)训练集和测试集中的数据分布要尽量与原始样本集一致,因此需要使用分层抽样(stratified sampling)的方式划分。
2)单次划分得到的结果进行学习产生的模型往往不够稳定可能,因此需要多次随机划分、重复进行实验评估后计算平均值来作为评估结果。
3)常用的划分比例为7:3或者8:2。
3.2 K折交叉验证
K折交叉验证(K-fold cross validation),是指将数据集划分成K个大小相近的互斥子集,每次选取其中的一个子集作为测试集,其他K-1个子集作为测试集,这样就可以得到K种选择结果,从而可以进行K次学习和预测,最终返回这K次测试结果的均值。
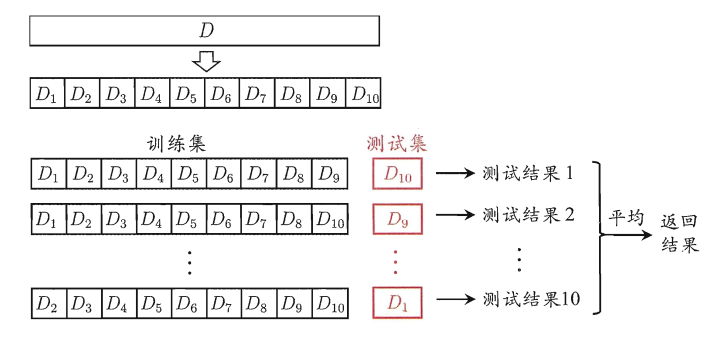
注意:
1)评估结果的稳定性很大程度上取决于K的取值,最常用的取值为10,其次为5和20等;
2)每个子集尽量保持数据分布一致,因此需要使用分层抽样;
3)和简单交叉验证一样,数据集的划分结果会可能影响模型最终的结果,为了减少这种划分带来的差异,可以重复进行p次划分,进行p次K折交叉验证,最终取这p次的平均评估结果。
3.3 留一交叉验证
留一交叉验证法,简称留一法(Leave-One-Out,LOO),它是一种特殊的K折交叉验证,K=样本数N。因为每次只保留一个样本进行测试,因此,留一法不受随机样本划分的影响,构建的模型与原始样本集构建的模型很相似,因此,其评估结果也认为很准确。但是其缺陷是,当样本集很大时,训练N个模型的计算开销将非常大。因此,在数据量相对缺乏时,可以采用。
4.参考与感谢
[1] 机器学习
[2] Python数据分析与数据化运营