一、简介
ELK 由三部分组成elasticsearch、logstash、kibana,elasticsearch是一个近似实时的搜索平台,它让你以前所未有的速度处理大数据成为可能。
Elasticsearch所涉及到的每一项技术都不是创新或者革命性的,全文搜索,分析系统以及分布式数据库这些早就已经存在了。它的革命性在于将这些独立且有用的技术整合成一个一体化的、实时的应用。Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
应用程序的日志大部分都是输出在服务器的日志文件中,这些日志大多数都是开发人员来看,然后开发却没有登陆服务器的权限,如果开发人员需要查看日志就需要到服务器来拿日志,然后交给开发;试想下,一个公司有10个开发,一个开发每天找运维拿一次日志,对运维人员来说就是一个不小的工作量,这样大大影响了运维的工作效率,部署ELKstack之后,开发任意就可以直接登陆到Kibana中进行日志的查看,就不需要通过运维查看日志,这样就减轻了运维的工作。
日志种类多,且分散在不同的位置难以查找:如LAMP/LNMP网站出现访问故障,这个时候可能就需要通过查询日志来进行分析故障原因,如果需要查看apache的错误日志,就需要登陆到Apache服务器查看,如果查看数据库错误日志就需要登陆到数据库查询,试想一下,如果是一个集群环境几十台主机呢?这时如果部署了ELKstack就可以登陆到Kibana页面进行查看日志,查看不同类型的日志只需要电动鼠标切换一下索引即可。
Logstash:日志收集工具,可以从本地磁盘,网络服务(自己监听端口,接受用户日志),消息队列中收集各种各样的日志,然后进行过滤分析,并将日志输出到Elasticsearch中。
Elasticsearch:日志分布式存储/搜索工具,原生支持集群功能,可以将指定时间的日志生成一个索引,加快日志查询和访问。
Kibana:可视化日志Web展示工具,对Elasticsearch中存储的日志进行展示,还可以生成炫丽的仪表盘。
二、安装部署(因为我是测试环境,就将ElasticSearch+Logstash+ Kibana装在一台虚拟机上面了)
1、安装jdk
3、安装kibana
logstash是ELK中负责收集和过滤日志的

编写配置文件如下:

解释:
logstash的配置文件须包含三个内容:
input{}:此模块是负责收集日志,可以从文件读取、从redis读取或者开启端口让产生日志的业务系统直接写入到logstash
filter{}:此模块是负责过滤收集到的日志,并根据过滤后对日志定义显示字段
output{}:此模块是负责将过滤后的日志输出到elasticsearch或者文件、redis等
output直接输出到Elasticsearch
本环境需处理两套业务系统的日志

type:代表类型,其实就是将这个类型推送到Elasticsearch,方便后面的kibana进行分类搜索,一般直接命名业务系统的项目名
path:读取文件的路径

这个是代表日志报错时,将报错的换行归属于上一条message内容
start_position => "beginning"是代表从文件头部开始读取

filter{}中的grok是采用正则表达式来过滤日志,其中%{TIMESTAMP_ISO8601}代表一个内置获取2016-11-05 00:00:03,731时间的正则表达式的函数,%{TIMESTAMP_ISO8601:date1}代表将获取的值赋给date1,在kibana中可以体现出来
本环境有两条grok是代表,第一条不符合将执行第二条
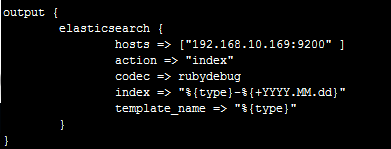
其中index是定义将过滤后的日志推送到Elasticsearch后存储的名字
%{type}是调用input中的type变量(函数)
启动logstash
![]()

5、然后再一次启动 elasticsearch 和 kibana ,并登录kibana:

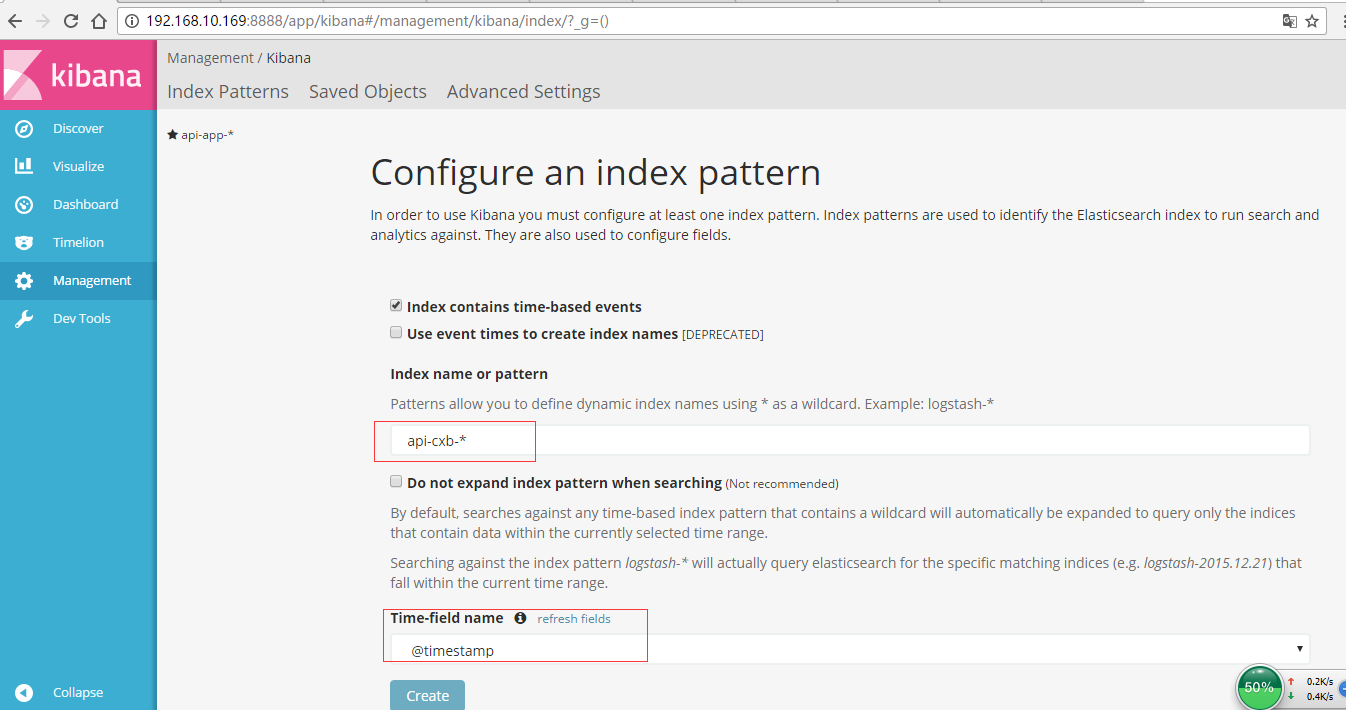
其中api-app-*和api-cxb-*从来的,*代表所有
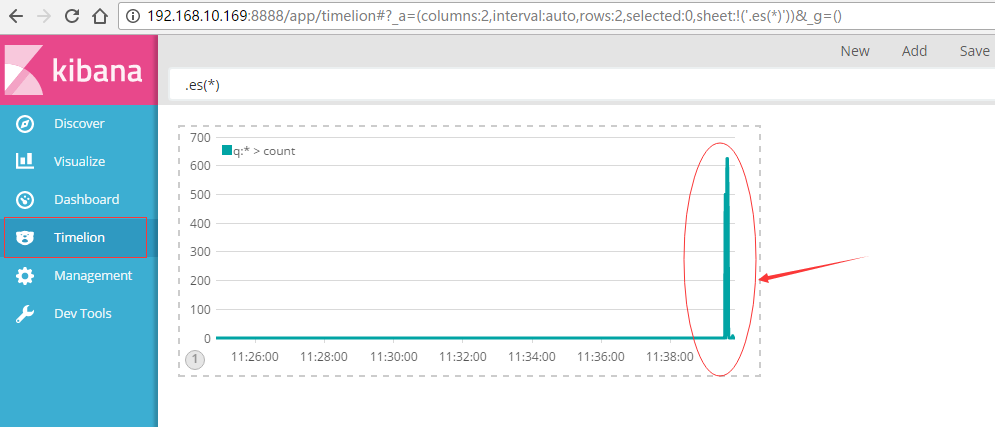
代表实时收集的日志条数
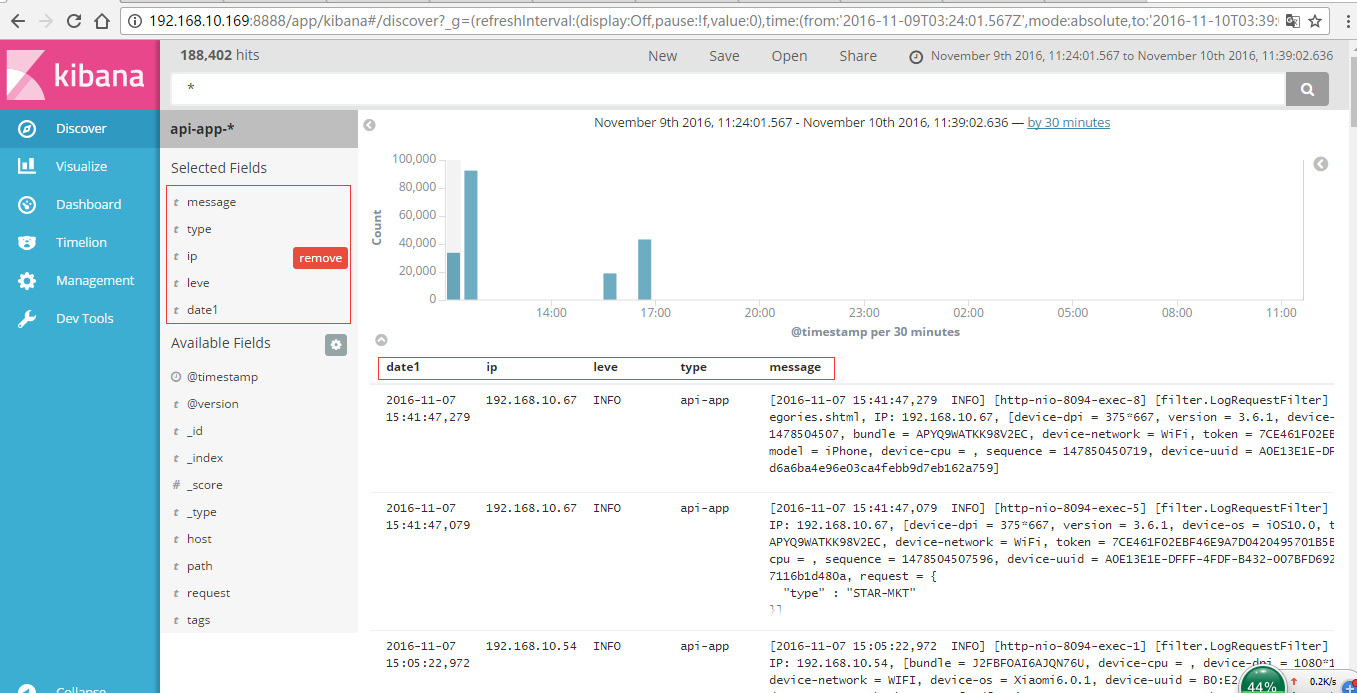
红色框内的就是在刚才filter过滤规则中定义的
三、案例测试
1、测试logstash 收集tomcat上某项目的日志文件:coaLog.conf
1 input { 2 file { 3 type => "coa_msg" 4 path => "/usr/local/tomcat/apache-tomcat-8.0.48/logs/coa/coa_msg.log" 5 start_position => beginning 6 } 7 } 8 filter { 9 10 } 11 output { 12 elasticsearch { 13 hosts => "10.10.10.34:9200" 14 index => "%{type}-%{+YYYY.MM.dd}" 15 template_name => "%{type}" 16 } 17 }
启动logstash:sh logstash -f coaLog.conf &
2、logstash配置mysql数据同步到elasticsearch:我参考的(https://blog.csdn.net/hatlonely/article/details/79945539)
获取 jdbc mysql 驱动:
wget https://cdn.mysql.com//Downloads/Connector-J/mysql-connector-java-5.1.46.zip
unzip mysql-connector-java-5.1.46.zip
可以把解压后的mysql-connector-java-5.1.46-bin.jar复制到bin目录,方便启动
在bin目录新建配置文件 vim mysql-logstash.cnf ,写入:
input {
jdbc {
jdbc_driver_library => "mysql-connector-java-5.1.46-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://ip:3306/db_name"
jdbc_user => "jdbc_user"
jdbc_password => "jdbc_password"
schedule => "* * * * *"
statement => "SELECT * FROM table WHERE 时间字段 >= :sql_last_value"
use_column_value => true
tracking_column_type => "timestamp"
tracking_column => "时间字段"
last_run_metadata_path => "syncpoint_table"
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "索引名称"
document_id => "%{主键字段}"
}
}
需要先把logstash停了,在重启
netstat -ntlp 命令查看端口为9600的进程,
然后kill 线程id,我的是 kill 25437
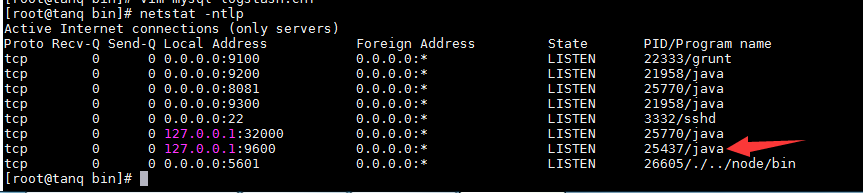
使用命令 sh logstash -f mysql-logstash.cnf --path.data=/home/elk/logstash-6.4.2/logs &
启动logstash
完了在kibana可以看到同步过去的数据,我的是这样的:
另外附上两个教程:
elasticsearch集成head插件查看es的数据:https://blog.csdn.net/mjlfto/article/details/79772848
kibana基础教程:https://www.elastic.co/guide/cn/kibana/current/introduction.html