每当想要根据给定输入预测某个结果,并且还有输入 / 输出对的示例时,都应该使 用监督学习。
分类和回归
监督学习的问题主要分为两种:分类和回归。
分类
分类问题主要分为两种:二分类和多分类。分类问题就是我们定义好了类别标签,将数据进行分类的问题。
二分类:二分类问题我们通常称一个为正类,另一个为反类。比如:垃圾邮件分类问题,只有是和否。
多分类问题:多分类问题,比如我们将成绩分为:优、良好、及格、不及格四个分类,这就是多分类问题。
回归
可能你觉得分类我很容易懂,但这个回归怎么回事?什么是回归?别着急。
数学好的同学可能知道,什么线性回归、回归方程等,没错就是这个回归,分类还是回归,我们是看结果,结果具有连续性我们称作为回归,当然,回归问题也可以作为分类问题处理,比如上面所说的成绩,成绩是在0~100这个区间上的整数,如果我们只看成绩,那么就具有连续性,不过我们可以分类四个区间也就是分类问题啦。
泛化、过拟合与欠拟合
监督学习算法
一些样本数据集
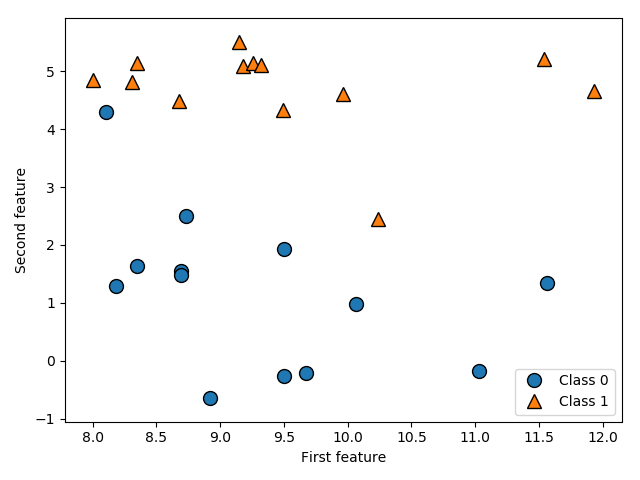
我们将使用一些数据集来说明不同的算法。其中一些数据集很小,而且是模拟的,其目的 是强调算法的某个特定方面。其他数据集都是现实世界的大型数据集。 一个模拟的二分类数据集示例是 forge 数据集,它有两个特征。下列代码将绘制一个散点 图(图 2-2),将此数据集的所有数据点可视化。图像以第一个特征为 x 轴,第二个特征为 y 轴。正如其他散点图那样,每个数据点对应图像中的一点。每个点的颜色和形状对应其 类别:从 X.shape 可以看出,这个数据集包含 26 个数据点和 2 个特征。
import matplotlib.pyplot as plt import mglearn # 生成数据集 X, y = mglearn.datasets.make_forge() # 数据集绘图 mglearn.discrete_scatter(X[:, 0], X[:, 1], y) plt.legend(["Class 0", "Class 1"], loc=4) plt.xlabel("First feature") plt.ylabel("Second feature")
print("X.shape: {}".format(X.shape)) plt.show()
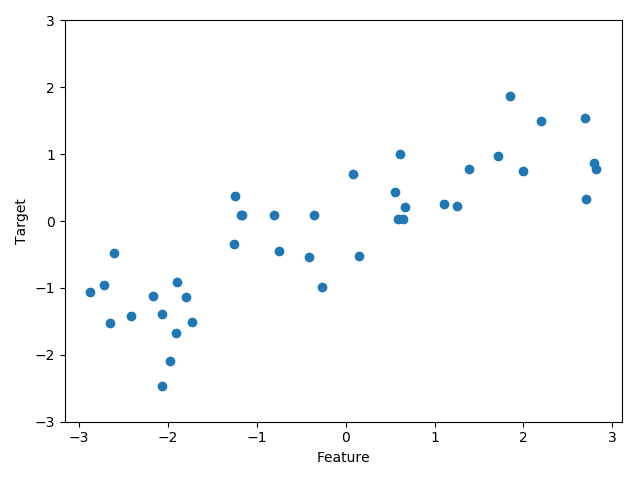
我们用模拟的 wave 数据集来说明回归算法。wave 数据集只有一个输入特征和一个连续的 目标变量(或响应),后者是模型想要预测的对象。下面绘制的图像(图 2-3)中单一特征 位于 x 轴,回归目标(输出)位于 y 轴:
import matplotlib.pyplot as plt import mglearn X, y = mglearn.datasets.make_wave(n_samples=40) plt.plot(X, y, 'o') plt.ylim(-3, 3) plt.xlabel("Feature") plt.ylabel("Target") plt.show()