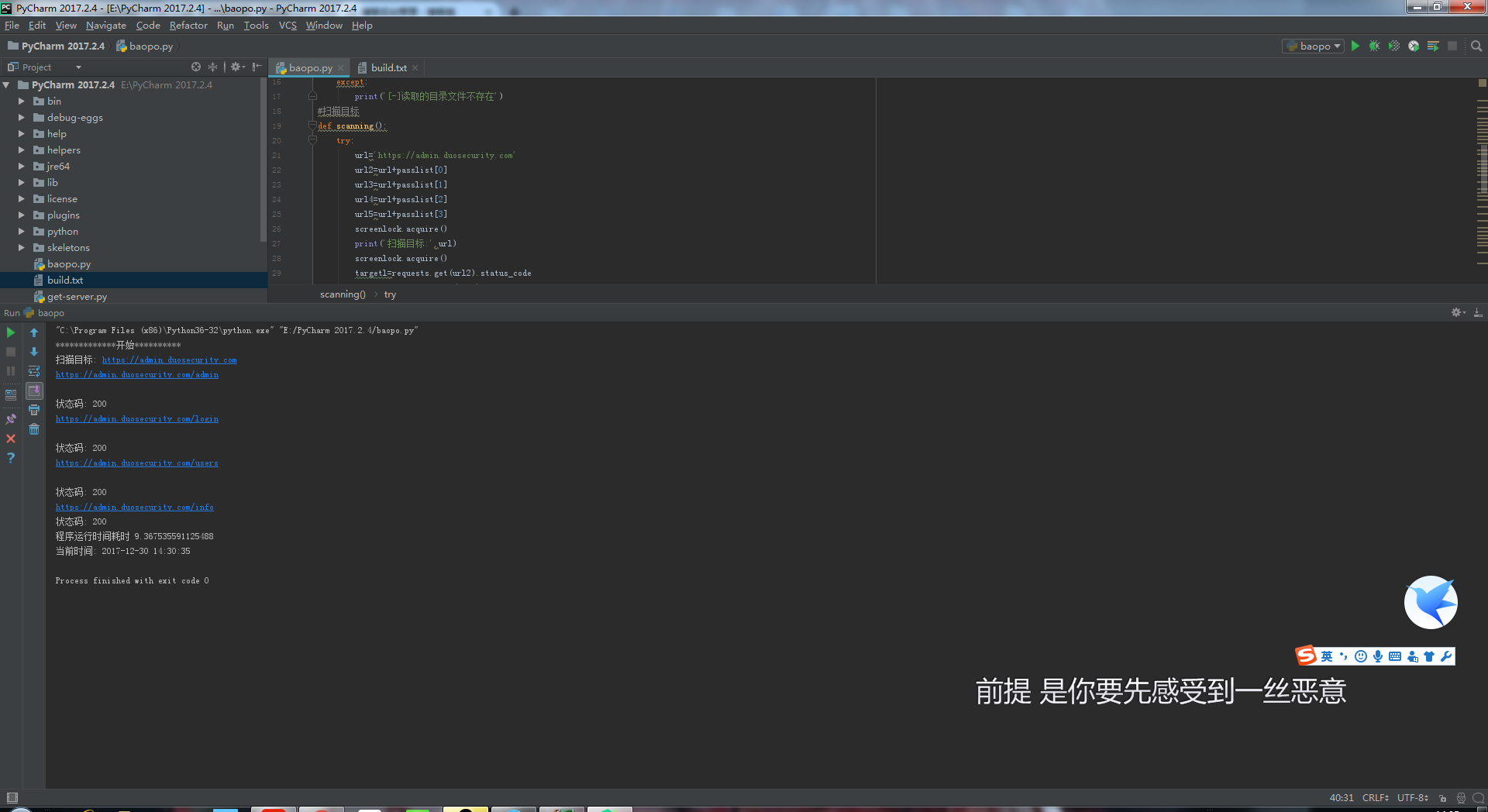
代码如下:
import requests import time from threading import * screenlock=Semaphore(value=500) print('*************开始**********') #打开路径字典 def dlistt(): try: global passlist global start start=time.time() passlist = [] g=open('build.txt','r') for x_line in g.readlines(): passlist.append(x_line) except: print('[-]读取的目录文件不存在') #扫描目标 def scanning(): try: url='https://admin.duosecurity.com' url2=url+passlist[0] url3=url+passlist[1] url4=url+passlist[2] url5=url+passlist[3] screenlock.acquire() print('扫描目标:',url) screenlock.acquire() targetl=requests.get(url2).status_code targetl1=requests.get(url3).status_code targetl2=requests.get(url4).status_code targetl3=requests.get(url5).status_code print(url2) print('状态码:',targetl) print(url3) print('状态码:',targetl1) print(url4) print('状态码:',targetl2) print(url5) print('状态码:',targetl3) end=time.time() print('程序运行时间耗时',end-start) print( '当前时间:',time.strftime('%Y-%m-%d %H:%M:%S')) except: # print('[-]未知错误,请反馈给开发者') print(time.strftime('%Y-%m-%d %H:%M:%S')) dlistt() if __name__ == '__main__': t = Thread(target=scanning, args=()) t.start()
运行结果: