废话不多说,马上开始。
上次我们说到遍历单个域名,今天我们来写一个爬对应词条的脚本,他会遍历整个网址直到爬完对应词条。
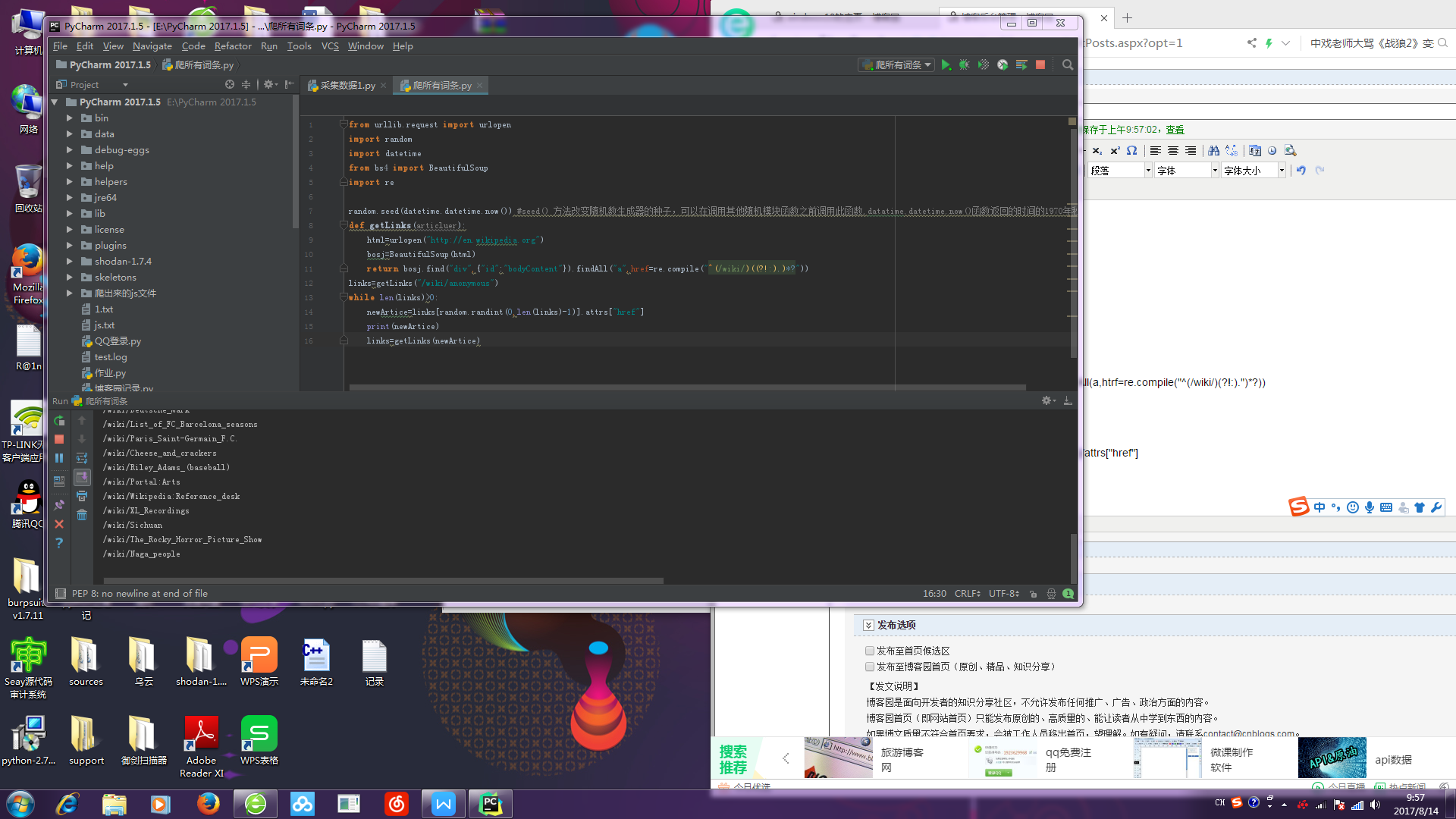
代码:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import random
import datetime
random.seed(datetime.datetime.now())
def geturl(gdfc):
html=urlopen("http://wikipedia.org")
bosj=BeautifulSoup(html)
return bosj.find("div",{"id":"bodyContent"}).findAll(a,htrf=re.compile("^(/wiki/)(?!:).")*?))
links=geturl("/wiki/anonymous")
while len(links)>0:
newArtice=links[random.randint(0,len(links)-1)]/attrs["href"]
print(newArtice)
links=geturl(newArtice)