一、redis简介
redis是一款基于C语言编写的,开源的非关系型数据库,由于其卓越的数据处理机制(按照规则,将常用的部分数据放置缓存,其余数据序列化到硬盘),大家也通常将其当做缓存服务器来使用。
在很多时候,大家还认为其只是一个key-value数据库服务器。然而redis还支持多种数据类型的存储,应用范围也更加广泛
redis支持的数据类型有string字符串。list列表,hash哈希,set集合,及zset(sorted set:有序集合)。
redis支持数据持久化(每隔一段时间会将内存中的数据写入粗盘;如果机器故障重启,还可以将硬盘的数据反写会内存),保证了告诉处理数据操作的同事,增加了数据的安全性;同时也支持数据数据库的主从复制、发布订阅、事务支持、管道和虚拟内存
二、redis优势
和其他nosql相比,redis的性能会更加卓越;同时,支持排名集合计算,消息队列等操作。
三、redis和memcached的区别
1、两者都是内存数据库,效率方面差别不大
2、redis不仅仅支持key-value数据格式,还支持list、set、hash等数据结构的存储
3、memcached是基于内存的key-value缓存服务器,完全基于内存,如果不考虑异常关机造成数据丢失的情况下,可以考虑;但是redis可以做数据持久化,因而数据安全性方面没有redis做的好
4、redis可以做故障恢复,将数据从硬盘恢复到内存
5、redis支持数据备份,即主从备份
四、redis的安装
五、redis数据类型
1、string字符串
string是redis最基本的数据类型,存取方便,可以存储一切可以序列化的数据对象,取出后可以反序列化为存储之前的数据对象进行使用
在实际操作中,通过set存储,get获取;name即为key值,liming为存储对象
注意:value存储最大数据为512M
使用场景:常规key-value缓存应用。常规计数: 微博数, 粉丝数。
127.0.0.1:6379> set name liming OK 127.0.0.1:6379> get name "liming"
2、list列表
list是数据列表格式,按照顺序插入数据,也可以插入数据到列表的头部或者尾部在实际操作中是通过lpust来存储数据列表。lrange来获取数据列表,取出一个值后,则在当前队列中消失
基本语法:存储lpush key value 例如(127.0.0.1:6379> lpush list C#);获取lrange key 查询索引开始 查询索引结束,例如(127.0.0.1:6379> lrange list 0 2)
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
Redis的list是每个子元素都是String类型的双向链表,可以通过push和pop操作从列表的头部或者尾部添加或者删除元素,这样List即可以作为栈,也可以作为队列。
应用场景:list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
127.0.0.1:6379> lpush list redis (integer) 1 127.0.0.1:6379> lpush list rabbitMQ (integer) 2 127.0.0.1:6379> lpush list sql (integer) 3 127.0.0.1:6379> lpush list C# (integer) 4 127.0.0.1:6379> lpush list python (integer) 5 127.0.0.1:6379> lpush list java (integer) 6 127.0.0.1:6379> lrange 0 2 (error) ERR wrong number of arguments for 'lrange' command 127.0.0.1:6379> lrange list 0 2 1) "java" 2) "python" 3) "C#"
3、hash哈希
hash 是一种key-value 键值对集合,类似数据字典,通过hmset 来存储,hget来获取
语法:hmset 哈希名称 key1 value1 key2 value2 …… 例如(127.0.0.1:6379> hmset myhash name1 'licy' name2 'lili' name3 'hanmeimei')
每个 hash 可以存储 232 -1 键值对(40多亿)。
使用场景:存储部分变更数据,如用户信息等。
127.0.0.1:6379> hmset myhash name1 'licy' name2 'lili' name3 'hanmeimei' OK 127.0.0.1:6379> hget myhash1 name1 (nil) 127.0.0.1:6379> hget myhash name1 "licy" 127.0.0.1:6379>
4、set集合
set集合是一种无序的数据集合,添加用 sadd,获取用smembers,添加成功则返回1,已经存在则返回0,添加失败则返回错误信息
语法:存储 sadd 集合名称 数据值(例如:127.0.0.1:6379> sadd myset redis) ;获取smembers 集合名称(例如:127.0.0.1:6379> smembers myset)
注:集合中最大的成员数为 232 - 1(4294967295, 每个集合可存储40多亿个成员)。
应用场景:求交集;求差集;求并集;获取某时间段内的数据去重
127.0.0.1:6379> sadd myset redis (integer) 1 127.0.0.1:6379> sadd myset C# (integer) 1 127.0.0.1:6379> sadd myset java (integer) 1 127.0.0.1:6379> sadd myset python (integer) 1 127.0.0.1:6379> smembers myset 1) "java" 2) "C#" 3) "redis" 4) "python"
5、zset有序集合
zset是一种有序集合,和string类似,多了个增加分数,获取时会按照分数小到大进行数据返回
key值是唯一的,但是分数可以重复
语法:存储 zadd 集合名词 分数 数据值 (例如:127.0.0.1:6379> zadd myzset2 3 sql);获取 ZRANGEBYSCORE 集合名称 索引开始 索引结束(例如:127.0.0.1:6379> ZRANGEBYSCORE myzset2 0 10)
应用场景:显示最新的列表数据项目;排行榜应用获取top N操作;求交集;求差集;求并集;获取某时间段内的数据去重
127.0.0.1:6379> zadd myzset2 3 sql (integer) 1 127.0.0.1:6379> zadd myzset2 1 C# (integer) 1 127.0.0.1:6379> zadd myzset2 2 python (integer) 1 127.0.0.1:6379> zadd myzset2 0 redis (integer) 1 127.0.0.1:6379> ZRANGEBYSCORE myzset2 0 10 1) "redis" 2) "C#" 3) "python" 4) "sql" 127.0.0.1:6379>
六、redis功能
1、发布订阅
redis的发布订阅是一种消息通讯模式,发布者发送消息,接收这接受消息,客户端可以任意定义频道,redis客户端可以任意订阅频道
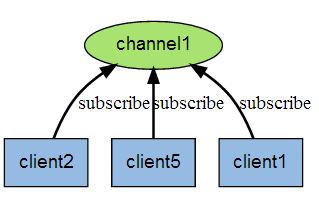
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
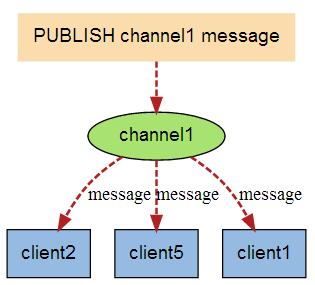
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
实例:订阅者
127.0.0.1:6379> SUBSCRIBE fabu1 Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "fabu1" 3) (integer) 1 1) "message" 2) "fabu1" 3) "my fa bu "
发布者
127.0.0.1:6379> PUBLISH fabu1 'my fa bu ' (integer) 1 127.0.0.1:6379>
2、持久化
由于redis的数据是存放在内存中,如果没有持久化,redis重启或者服务器重启数据会丢失,于是需要开启redis的持久化功能,用于将数据保存在硬盘上,当redis重启后,可以从硬盘中恢复数据。
redis提供两种方式进行持久化,一种是RDB持久化(原理是将redis中在内存中的数据记录定时dump到硬盘上的RDB持久化),另一种是AOD持久化(原理是将redis的操作日志以追加的方式写入文件)
3、redis的主从复制
一般来说,一台redis可以处理的数据是有限的,即使硬件支持很好,也无法满足日益增长的业务需求,因而redis提供了主从集群的功能,可以实现读写分离,极大限度的提高了系统的性能和满足业务的拓展。同时,为了避免一台redis服务器宕机而引起的系统崩溃,redis也提供了启用sentinel(哨兵)服务,在一台服务器宕机是自动切换到另外一台从服务器,同时设置当前的从服务器为主服务器
4、redis事务
在系统中,经常会遇到很多零散的操作有很强的顺序性,一旦中间某个操作异常或者服务器异常等其他情况,因而就需要事务来处理
redis事务可以一次执行多个命令,redis会将事务中的命令序列化,然后按照顺序执行。redis事务不可能在事务执行的过程中插入另外一个客户端发来的命令请求,这样便保证了命令执行的过程中进行隔离单独执行。在redis事务中,要么执行所有命令要么一个都不执行
一个事务从开始到执行共有三个阶段
a、事务开始
b、命令入列
c、执行事务
5、redis管道
6、redis虚拟内存
七、redis总结
redis是高性能的缓存服务器解决方案,可以数据持久化和快速搭建集群,高并发,高可用性
参考地址http://www.cnblogs.com/caokai520/p/4409712.html