本文介绍使用java.util.*包中的HashMap 和 LinkedList 以及 ArrayList类快速实现一个有向图,并实现有向图的深度优先遍历算法。
如何构造图?
本文根据字符串数组来构造一个图。图的顶点标识用字符串来表示,如果某个字符串A的第一个字符与另一个字符串B的最后一个字符相同,则它们之间构造一条有向边<A,B>。比如,字符串数组{"hap","peg","pmg","god"}对应的有向图如下:
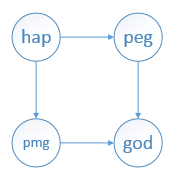
采用图的邻接表 表示法 来实现图。使用Map<String, ArrayList<String>>来代表图的邻接表。
Key 表示顶点的标识,如,"hap","peg"....
Value 表示顶点的邻接表。如,顶点"hap"的邻接表是 <"pmg","peg">
因此,这里就用一个简单的Map来实现了图。而不是像这篇文章:数据结构--图 的JAVA实现(上) 中那样,定义顶点类Vertex.java,边类Edge.java。
构造图的具体代码思路如下:先初始化整个图,将每个顶点添加到图中,并初始化它们的邻接表。
1 Map<String, ArrayList<String>> graph = new HashMap<String, ArrayList<String>>(arr.length);//根据字符串数组arr构造图 2 3 for (String str : arr) { 4 graph.put(str, new ArrayList<String>()); 5 }
对字符串数组中的每个字符串,遍历数组中的其他字符串,判断:某个字符串A的第一个字符与另一个字符串B的最后一个字符 是否相同。若相同,则将字符串B添加到字符串A的邻接表中去。
1 if(start.charAt(startLen-1) == end.charAt(0))//start-->end 2 { 3 adjs = graph.get(start); 4 if(!adjs.contains(end)) 5 adjs.add(end); 6 graph.put(start, adjs); 7 }else if(start.charAt(0) == end.charAt(endLen-1)){//end-->start 8 adjs = graph.get(end); 9 if(!adjs.contains(start)) 10 adjs.add(start); 11 graph.put(end, adjs); 12 }
图的深度优先遍历算法实现
这里实现非递归DFS遍历。用一个LinkedList<String> stack 来模拟递归DFS时用到的栈。用一个HashSet<String>来标记某个顶点是否访问了,如果该顶点被访问了,则添加到HashSet<String>中。用一个ArrayList<String>来保存DFS遍历时经过的顶点路径,最终函数返回该ArrayList<String>表示本次调用DFS遍历得到的访问路径。
1 ArrayList<String> paths = new ArrayList<>(graph.size());//保存访问路径 2 3 HashSet<String> visited = new HashSet<>(graph.size());//用来判断某个顶点是否已经访问了 4 LinkedList<String> stack = new LinkedList<>();//模拟递归遍历中的栈 5 6 stack.push(start); 7 paths.add(start); 8 visited.add(start);
深度优先遍历的思路是:
先将起始顶点入栈--->获取栈顶元素作为当前正在遍历的元素--->获得当前正在遍历的元素的邻接表--->找出它的邻接表中还未被访问的一个顶点--->访问该顶点(将该顶点保存到访问路径中),并将该顶点压栈
如果当前正在遍历的元素的邻接表为空或者该顶点的所有邻接表中的顶点都已经访问了,说明:需要回退了。因此,弹出栈顶元素。
1 while(!stack.isEmpty()) 2 { 3 String next = null;//下一个待遍历的顶点 4 String currentVertex = stack.peek();//当前正在遍历的顶点 5 ArrayList<String> adjs = graph.get(currentVertex);//获取当前顶点的邻接表 6 if(adjs != null) 7 { 8 for (String vertex : adjs) { 9 if(!visited.contains(vertex))//vertex 未被访问过 10 { 11 next = vertex; 12 break; 13 } 14 } 15 }//end if 16 17 if(next != null)//当前顶点还有未被访问的邻接点 18 { 19 paths.add(next);//将该邻接点添加到访问路径中 20 stack.push(next); 21 visited.add(next); 22 }else{ 23 stack.pop();//回退 24 } 25 }//end while
给定一个有向图,如何判断:一定存在着某个顶点,从该顶点进行DFS遍历,能够遍历完图中所有的顶点?
比如上图,从"hap"顶点出发,进行DFS遍历,能够遍历完图中所有的顶点。
而从"pmg"顶点出发,进行DFS遍历,只能从"pmg"访问到"god"顶点。不能遍历完图中所有的顶点。
思路很简单:只要将 每次从某个顶点出发开始遍历的路径 ArrayList<String> 中的元素个数 与 图中顶点个数比较。如果相等,则说明能够遍历完图中所有的顶点,否则不能。
1 //从图中的每一个顶点开始DFS遍历 2 for (String v : vertexs) { 3 paths = dfs(graph, v); 4 5 if(paths.size() == graph.size())//从 顶点 v 遍历 能够遍历完图中所有的顶点. 6 { 7 System.out.println("从顶点: " + v + " 开始DFS遍历能够遍历完所有的顶点,路径如下:"); 8 printPath(paths, graph); 9 result = true; 10 break; 11 } 12 }
另:补充一下DFS的递归实现:
1 public static ArrayList<String> dfs_recu(String start, Map<String, ArrayList<String>> graph) 2 { 3 ArrayList<String> paths = new ArrayList<>();//保存访问路径 4 HashSet<String> visited = new HashSet<>();//保存顶点的访问状态 5 dfsrecuresive(start, graph, paths, visited);//递归DFS 6 return paths;//返回本次DFS的访问路径 7 } 8 private static void dfsrecuresive(String start, Map<String, ArrayList<String>> graph, ArrayList<String> paths, HashSet<String> visited) 9 { 10 visited.add(start);//标记 start 已访问 11 paths.add(start);//将 start 添加到路径中 12 13 ArrayList<String> adjs = graph.get(start); 14 for (String v : adjs) { 15 if(!visited.contains(v))//如果 start顶点的邻接表中还有未被访问的顶点 16 dfsrecuresive(v, graph, paths, visited);//递归访问该未被访问的顶点v 17 } 18 }
总结:使用这种方式而不是“面向对象”的方式(定义顶点类、边类)来实现图,并实现图的DFS算法,感觉是空间复杂度有点大。比如,DFS遍历过程中需要判断某个顶点是否已经访问了,上面的处理是:当某顶点已经访问了时,将之加入到HashSet中。HashSet就是O(N)的空间复杂度。
但是,这种方式编程实现快(个人感觉,哈哈)。
整个程序完整代码实现:


import java.util.ArrayList; import java.util.HashMap; import java.util.HashSet; import java.util.LinkedList; import java.util.Map; import java.util.Set; /** * 有向图的深度优先遍历实现 在深度遍历中,是否存在一条路径包含了图中所有的顶点?? * * @author psj * */ public class DFSOrder { public static Map<String, ArrayList<String>> buildGraph(String[] arr) { Map<String, ArrayList<String>> graph = new HashMap<String, ArrayList<String>>( arr.length); for (String str : arr) { graph.put(str, new ArrayList<String>()); } String start; int startLen; String end; int endLen; for (int i = 0; i < arr.length; i++) { start = arr[i]; startLen = start.length(); if (startLen == 0) continue; ArrayList<String> adjs = null; for (int j = 0; j < arr.length; j++) { end = arr[j]; endLen = end.length(); if (endLen == 0) continue; if (start.charAt(startLen - 1) == end.charAt(0))// start-->end { adjs = graph.get(start); if (!adjs.contains(end)) adjs.add(end); graph.put(start, adjs); } else if (start.charAt(0) == end.charAt(endLen - 1)) {// end-->start adjs = graph.get(end); if (!adjs.contains(start)) adjs.add(start); graph.put(end, adjs); } } } return graph; } /** * 从start顶点开始,对graph进行DFS遍历(非递归) * * @param graph * @param start * @return DFS遍历顺序 */ public static ArrayList<String> dfs(Map<String, ArrayList<String>> graph, String start) { assert graph.keySet().contains(start);// 假设 start 一定是图中的顶点 ArrayList<String> paths = new ArrayList<>(graph.size()); HashSet<String> visited = new HashSet<>(graph.size());// 用来判断某个顶点是否已经访问了 LinkedList<String> stack = new LinkedList<>();// 模拟递归遍历中的栈 stack.push(start); paths.add(start); visited.add(start); while (!stack.isEmpty()) { String next = null;// 下一个待遍历的顶点 String currentVertex = stack.peek();// 当前正在遍历的顶点 ArrayList<String> adjs = graph.get(currentVertex);// 获取当前顶点的邻接表 if (adjs != null) { for (String vertex : adjs) { if (!visited.contains(vertex))// vertex 未被访问过 { next = vertex; break; } } }// end if if (next != null)// 当前顶点还有未被访问的邻接点 { paths.add(next);// 将该邻接点添加到访问路径中 stack.push(next); visited.add(next); } else { stack.pop();// 回退 } }// end while return paths; } // 打印从某个顶点开始的深度优先遍历路径 public static void printPath(ArrayList<String> paths, Map<String, ArrayList<String>> graph) { System.out.println("dfs path:"); for (String v : paths) { System.out.print(v + " "); } System.out.println(); } // 判断有向图中是否存在某顶点,从该顶点进行DFS遍历,能够遍历到图中所有的顶点 public static boolean containsAllNode(Map<String, ArrayList<String>> graph) { boolean result = false; ArrayList<String> paths = null; Set<String> vertexs = graph.keySet(); // 从图中的每一个顶点开始DFS遍历 for (String v : vertexs) { paths = dfs(graph, v); if (paths.size() == graph.size())// 从 顶点 v 遍历 能够遍历完图中所有的顶点. { System.out.println("从顶点: " + v + " 开始DFS遍历能够遍历完所有的顶点,路径如下:"); printPath(paths, graph); result = true; break; } } return result; } // hapjin test public static void main(String[] args) { // String[] words = {"me","cba","agm","abc","eqm","cde"}; String[] words = { "abc", "cde", "efg", "che" }; Map<String, ArrayList<String>> graph = buildGraph(words); System.out.println(containsAllNode(graph)); } }
来源:hapjin blog