kafka 日常使用和数据副本模型的理解
在使用Kafka过程中,有时经常需要查看一些消费者的情况、Kafka健康状况、临时查看、同步一些数据,又由于Kafka只是用来做流式存储,又没有像Mysql或者Redis提供方便的查询方法查看数据。只能通过在命令行执行Kafka 脚本方式操作kafka(当然也有一些第三方的kafka监控工具),这里就主要收集一些常用的Kafka命令。
在看到 kafka ISR 副本时,实在忍不住就多扯了一点背后的原理,将Kafka、Redis、ElasticSearch三者对比起来看各自的存储模型,比如说Redis主要用来做缓存,那采用异步复制能够减少Client的时延,Redis的P2P结构注定了它采用Gossip协议传播集群状态。另外,将Redis里面的基于Raft的选举算法与ES里面的master选举对比,也有助于理解分布式系统的选举理论。当然了,各个原理介绍都浅尝辄止,仅是自己的一些浅见,里面的每一点都值得仔细深究。
1 查看Kafka集群里面都有哪些消费者组 consumer group
./bin/kafka-consumer-groups.sh --new-consumer --bootstrap-server localhost:9092 --list
2 查看 每个consumer 对各个分区的消费情况
找到consumer group后,接下来可查看这个 consumer group的消费情况,比如:比如是否有消费延时(LAG)、一共有多少个consumer(OWNER)、还能看到这个consumer 所消费的TOPIC 各个 分区 的消费情况:
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group GROUP_ID
3 查看Topic的同步情况
在Kafka中数据采用多个副本存储。主副本接收生产者、消费者的请求,从副本(replica)只从主副本那里同步数据。
./bin/kafka-topics.sh --zookeeper ZK_IP:2181 --topic user_update_info_topic --describe
Topic:user_update_info_topic PartitionCount:6 ReplicationFactor:2 Configs:retention.ms=259200000
Topic: user_update_info_topic Partition: 0 Leader: 3 Replicas: 3,2 Isr: 3,2
Topic: user_update_info_topic Partition: 1 Leader: 4 Replicas: 4,3 Isr: 4,3
Topic: user_update_info_topic Partition: 2 Leader: 0 Replicas: 0,4 Isr: 0,4
Topic: user_update_info_topic Partition: 3 Leader: 1 Replicas: 1,0 Isr: 0,1
Topic: user_update_info_topic Partition: 4 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: user_update_info_topic Partition: 5 Leader: 3 Replicas: 3,4 Isr: 3,4
在这里根据Leader、Replicas、Isr 能发现一个Kafka Broker可能存在的一些故障(这些数字是 server.properties配置项 broker.id)。比如某个broker.id没有出现在Isr中,可能这台节点上的副本同步出现了问题。
这里介绍一个Kafka的ISR机制:
要保证数据的可靠性,数据会存储多份,即多个副本。引入多个副本会带来2个难题:一是各个副本之间的数据如何保证一致?二是对Client写性能(写操作)的影响?因为数据有多份时,Client写入一条消息,什么时候给Client返回ACK成功确认呢?是将写入的消息成功"同步"给了所有的副本才返回ACK,还是只要主副本"写入"了就返回ACK?
注意:这里的"写入"、"同步"都加了引号,是因为:它们只是一个抽象的描述。就拿"写入"来说:是写入内存即可、还是写入到磁盘?这里牵涉到一系列的过程,可参考Redis persistent这篇文章。
对于Kafka而言,生产者发送消息时有一个ack参数(ack=0、ack=1、ack=all),默认情况下ack=1意味着:发送的消息写入主副本后,返回ACK给生产者。ack=all 意味着:发送的消息写入所有的ISR集合中的副本后返回ACK给生产者。
某个Topic 的 ISR集合中的副本和它所有的副本是有区别的:ISR集合中的副本是"最新的",这也说明:ISR集合中的副本是动态变化的,比如当发生网络分区时,某个节点上的从副本与主副本断开了连接,这些从副本就会从ISR集合中移除。
生产者发送一条消息给Kafka主副本并且收到了ACK返回确认 和 这条消息已提交是两回事。返回ACK确认的过程上面已经分析了,消息已提交跟参数"min.insync.replicas"息息相关。默认情况下,min.insync.replicas=1,意味着只要主副本写入了消息,就认为这条消息已经提交了。
下面举个例子说明生产者ack参数和服务端min.insync.replicas参数分别所起的作用:假设三个副本、ack=1、min.insync.replicas=2,生产者发送的消息只要写入了主副本就会返回ACK确认给生产者,但是这条消息要成功同步到2个副本之后才算是已提交。若此时ISR集合里面只有主副本(一个),意味着生产者虽然收到了写入消息的ACK确认,但是这些消息都不能被消费者消费到,因为只有已提交的消息才能被消费者消费到。
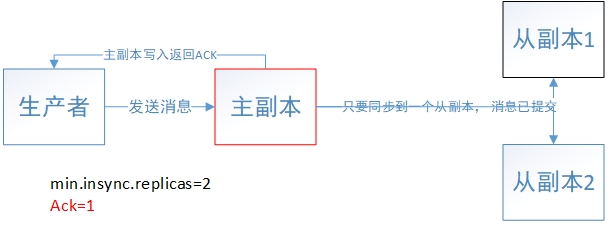
min.insync.replicas可提高消息存储的可靠性:如果ack=1、min.insync.replicas=1,生产者将消息写入主副本,收到返回ACK确认,但主副本还未来得及将消息同步给其他副本时,主副本所在节点宕机了,那么:就会丢失已经返回了ACK确认的消息。(在《Kafka实战》一书提到:ack=all时,min.insync.replicas才有意义,这一点需要读源码才能验证了),看了下Kafka官方文档对 min.insync.replicas 参数的解释:
When a producer sets acks to "all" (or "-1"), min.insync.replicas specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful. If this minimum cannot be met, then the producer will raise an exception (either NotEnoughReplicas or NotEnoughReplicasAfterAppend).
When used together, min.insync.replicas and acks allow you to enforce greater durability guarantees. A typical scenario would be to create a topic with a replication factor of 3, set min.insync.replicas to 2, and produce with acks of "all". This will ensure that the producer raises an exception if a majority of replicas do not receive a write.
根据官方文档可知:ack=-1或者ack=all时,可将min.insync.replicas设置成 brokers 数量的 majority,从而保证:Producer收到写入消息的ack时,就能保证该消息一定在大多数副本中写成功了。
因此,ISR机制加上min.insync.replicas参数就能提高数据的可靠性。当ISR集合里面副本个数大于等于min.insync.replicas时,一切正常。为什么要用ISR机制呢?
ISR机制是基于同步复制和异步复制之间的一种中间状态,Redis Cluster 采用了异步复制策略,其Redis Sentinel 官方文档提到,Redis 里面无法保证已经返回给Client ACK确认的消息不丢失,并推荐了两种补救方案:
- Use synchronous replication (and a proper consensus algorithm to run a replicated state machine).
- Use an eventually consistent system where different versions of the same object can be merged.
而ISR机制较好地兼容了同步复制带来的写性能消耗和异步复制导致的数据可靠性问题。ISR集合里面实时维护着一组副本,即同步副本,这组副本的数据与主副本数据是一致的,在Kafka中:同步副本是指:过去6s内向zookeeper发送过心跳或者过去10s内从首领副本那里同步过消息的副本。
其实,ElasticSearch的数据副本模型也是采用的ISR机制,ES中的primary shard负责接收index操作,然后将index的数据同步给各个replica,ES里面提供了参数:wait_for_actives_shards参数来保证当index操作写入多少个replica后才返回ACK给Client。
Kafka和ElasticSearch的数据副本模型是类似的,只是在Kafka中,生产者写入和消费者读取都是由主副本完成,而ES中数据写入primary shard,但是读取可以读各个replica,ES中读操作存在 read unacknowledged 和 dirty reads。由于ES是个搜索引擎,文档索引到ES后,用户关注的问题是:什么时候能够被搜索到?ES提供的是近实时搜索,因为文档需要刷新成Segment才能被搜索,同时ES又提供了real time GET API,能实时获取刚索引的文档。
此外,ES与Kafka都有一个master节点(这里的master是针对节点而言,不是数据副本的主从),master节点负责集群状态变更(待完善)。而Redis Cluster采用的是P2P结构,通过Gossip协议来传播集群状态,并没有master节点这样的角色。在ES中通过Hash文档ID(murmur3)将文档hash到各个primary shard,而在Redis Cluster中则是 CRC 再 mod 16384 进行数据分片,以固定的"槽数目"为中间桥梁,将键映射到Redis节点上,当动态增删节点时只需迁移部分槽上的键。从数据分布这一点看,ES和Redis是类似的。哈希方式进行数据分布的优势是:不需要存储数据分布的元信息,hash结果均匀的话,也能保证较均匀的数据分布。
从集群(节点的角度)结构上看,ES和Kafka都有一个主节点(不管叫master,还是叫controller),而Redis是去中心化P2P结构,所以在传播集群状态结构时,ES采用的是两阶段提交协议,Kafka的我没有去研究,而Redis采用的是Gossip协议。在讨论"主从"时,要明确指出是基于节点、还是基于数据副本?在ES中,一个节点上既可存储主副本(primary shard),也可存储从副本(replica),ES的 shard allocation 策略是不会把同一个索引的主副本、从副本放在一个节点上,而是说:索引A的主副本在节点1上,索引B的从副本也在节点1上。而对于Redis集群而言,一个主节点存储一部分键空间上的数据,这个主节点可以有若干个从节点,这些从节点从主节点上异步复制数据做副本备份。
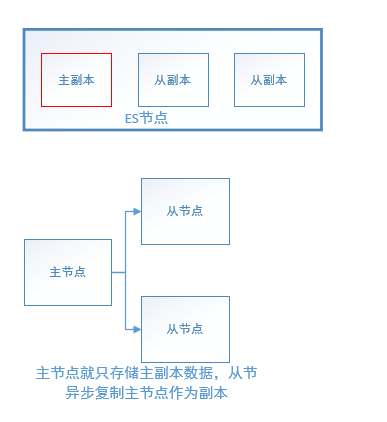
ES的master节点(master-eligible)既可用来存储数据,也可只专心作为master(在配置文件中将node.data配置为false)。因此,ES集群中的节点角色比Redis Cluster要多得多(master-eligible node、data node、coordinating only node)。
4 测试查看一条Kafka消息
由于Kafka的流式特征,在写代码的时候需要先知道一下消息的格式。用下面的命令就可以查看一条Kafka Topic上的消息。
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TOPIC--from-beginning --max-messages 1
5 跨集群数据同步
有个时候,生产环境上的Kafka集群在本地开发环境下不能直接连接导致测试Debug不方便,可采用mirror-make将一部分生产环境上的数据同步到测试环境做测试,^
./bin/kafka-mirror-maker.sh --consumer.config ./config/mirror-maker-consumer.properties --producer.config ./config/mirror-maker-producer.properties --whitelist "TOPIC_NAME"
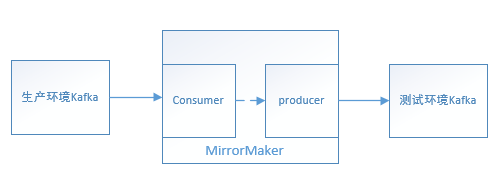
基本的mirror-maker-producer.properties配置参数如下:
bootstrap.servers=测试环境KafkaIP:9092
acks=1
linger.ms=100
batch.size=16384
retries=3
基本的mirror-maker-consumer.properties配置参数如下:
bootstrap.servers=生产环境上的kafka集群BOOT_STRAP_SERVERS
group.id=mirror-maker
auto.offset.reset=earliest
enable.auto.commit=true
auto.commit.interval.ms=1000