为了帮助企业用户寻找更为有效、加快Hadoop数据查询的方法,Apache 软件基金会发起了一项名为“Drill”的开源项目。Apache Drill 实现了 Google's Dremel.
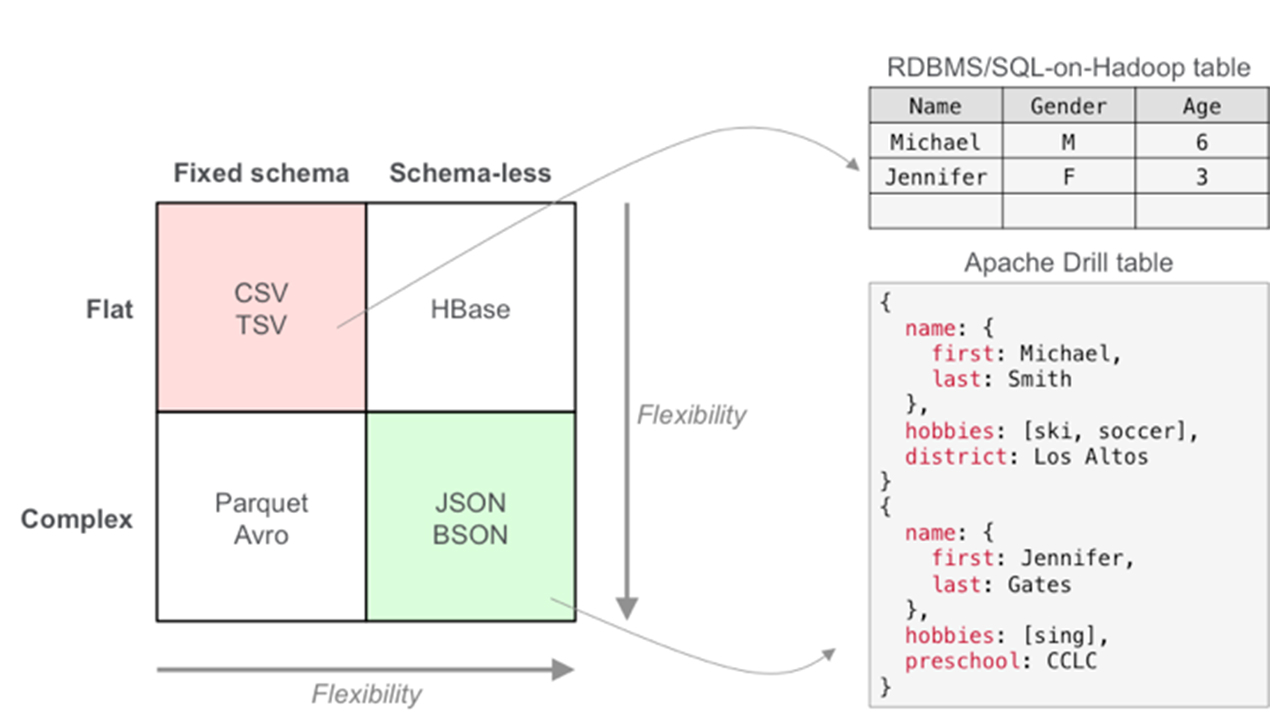
Apache Drill 在基于 SQL 的数据分析和商业智能(BI)上引入了 JSON 文件模型,这使得用户能查询固定架构,演化架构,以及各种格式和数据存储中的模式无关(schema-free)数据。该体系架构中关系查询引擎和数据库的构建是有先决条件的,即假设所有数据都有一个简单的静态架构。
Apache Drill 的架构师独一无二的。它是唯一一个支持复杂和无模式数据的柱状执行引擎(columnar execution engine),也是唯一一个能在查询执行期间进行数据驱动查询(和重新编译,也称之为 schema discovery)的执行引擎(execution engine)。这些独一无二的性能使得 Apache Drill 在 JSON 文件模式下能实现记录断点性能(record-breaking performance)。
该项目将会创建出开源版本的谷歌Dremel Hadoop工具(谷歌使用该工具来为Hadoop数据分析工具的互联网应用提速)。而“Drill”将有助于Hadoop用户实现更快查询海量数据集的目的。
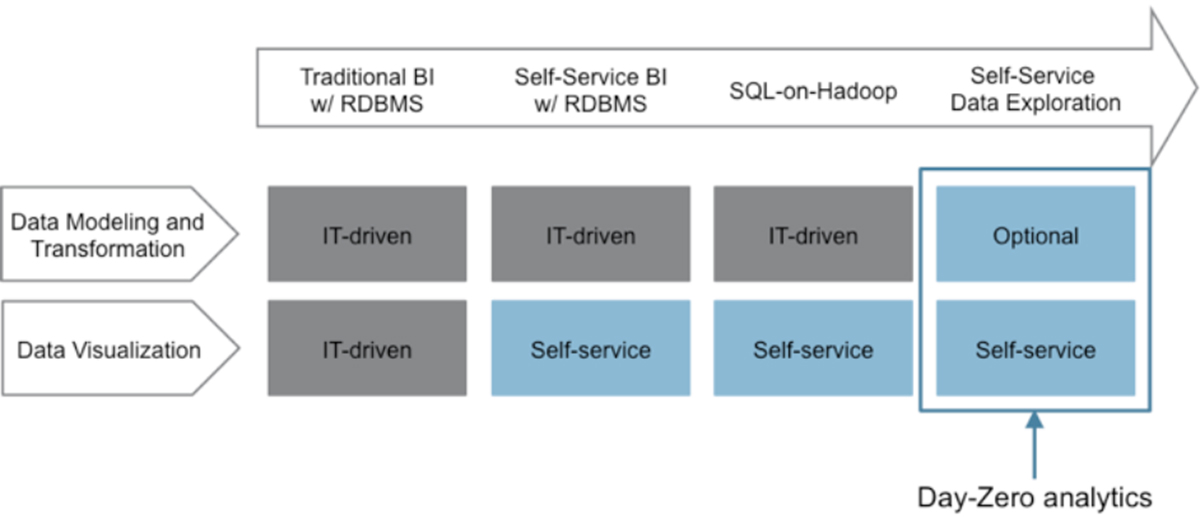
数据结构:
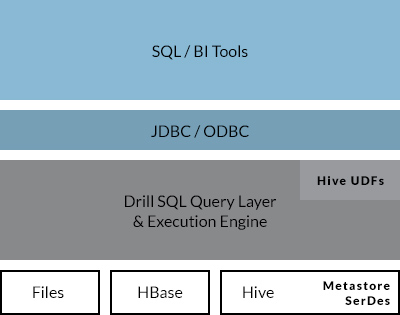
兼容已有的 SQL 环境和 Apache Hive:
“Drill”项目其实也是从谷歌的Dremel项目中获得灵感:该项目帮助谷歌实现海量数据集的分析处理,包括分析抓取Web文档、跟踪安装在Android Market上的应用程序数据、分析垃圾邮件、分析谷歌分布式构建系统上的测试结果等等。
通过开发“Drill”Apache开源项目,组织机构将有望建立Drill所属的API接口和灵活强大的体系架构,从而帮助支持广泛的数据源、数据格式和查询语言。
Drill 查询:
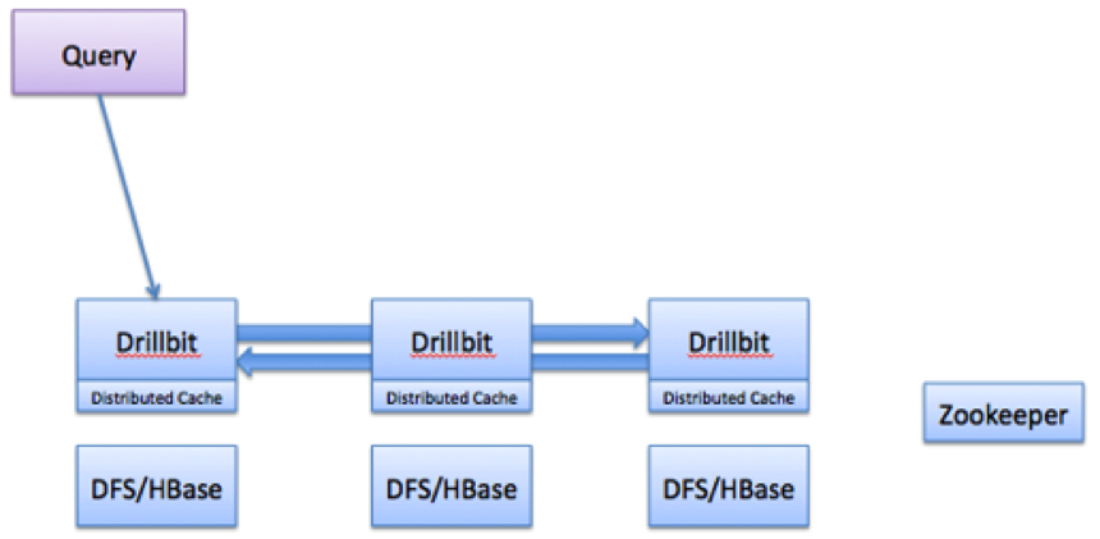
Drillbit 核心模型:
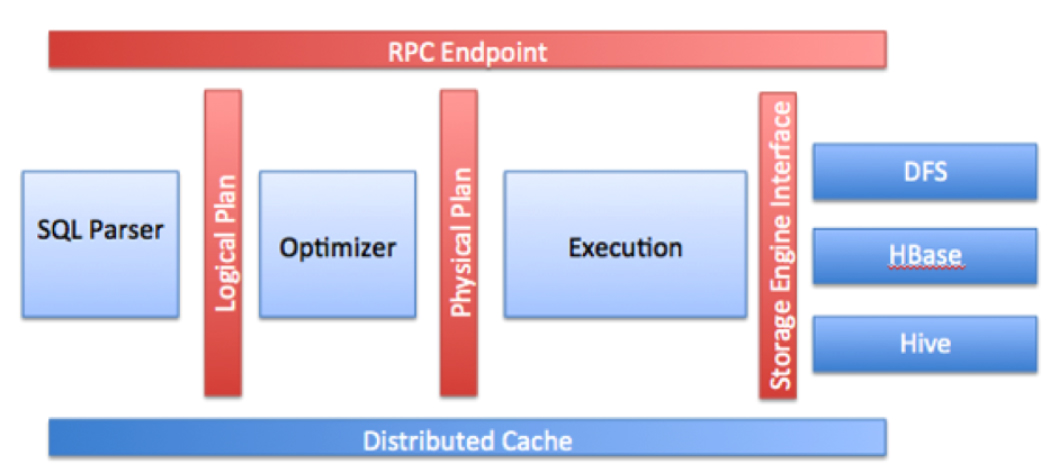
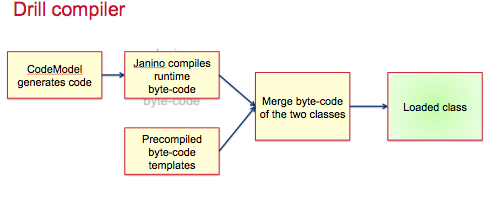
Drill 编译器: