一、Hive 窗口函数(OLAP函数分析函数)
窗口函数最重要的关键字是 partition by 和 order by
具体用法如下:over (parttion by xxx order by xxx)
1、SUM、AVG、MIN、MAX
数据:
cookie1,2018-04-10,1
cookie1,2018-04-11,5
cookie1,2018-04-12,7
cookie1,2018-04-13,3
cookie1,2018-04-14,2
cookie1,2018-04-15,4
cookie1,2018-04-16,4
-- 建表
create table MESSAGE(cookieid string,createtime string,pv int) row format delimited fields terminated by ',';
-- 加载数据
load data local inpath '数据文件的路径' into table message;
-- 开启智能本地模式
set hive.exec.mode.local,quto=true;
pv1: 分组内从起点到当前行的pvde 累积
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtime) as pv1 from message;
pv2: 同pv1
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by creatertime rows between unbounded preceding and current row) as pv2 from message;
pv3 :分组内(cookie1)所有的 pv 累加
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid) as pv3
from itcast_t1;
pv4: 分组内当前行+往前 3 行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows bettween 3 preceding and current row) as pv4
from message;
pv5: 分组内当前行+往前 3 行+往后 1 行,
select cookieid,createtime,pv
sum(pv) over(partition by cookieid order by createtime rows bettween 3 predceding and 1 following) as pv5
from message;
- 如果不指定rows bettween 默认为从起点到当前行
- 如果不指定 order by 将分组内所有所有值累加
- following :往后
- preceding :往前
- current row :当前行
- unbounded :起点
- unbounded preceding :表示从前面的起点
- unbounded following :表示到后面的终点
2、ROW_NUMBER、RANK、DENSE_RANK、NTILE
数据:
cookie1,2018-04-10,1
cookie1,2018-04-11,5
cookie1,2018-04-12,7
cookie1,2018-04-13,3
cookie1,2018-04-14,2
cookie1,2018-04-15,4
cookie1,2018-04-16,4
cookie2,2018-04-10,2
cookie2,2018-04-11,3
cookie2,2018-04-12,5
cookie2,2018-04-13,6
cookie2,2018-04-14,3
cookie2,2018-04-15,9
cookie2,2018-04-16,7
CREATE TABLE mes (cookieid string,createtime string, --daypv INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile;
加载数据:
load data local inpath '/root/hivedata/itcast_t2.dat' into table mes;2.1 ROW_NUMBER()
select cookied,createtime,pv row_number() over(partition by cookieid order by pv desc) as rn from message;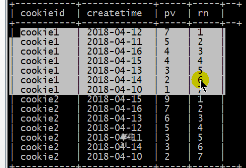
2.2. RANK 和 DENSE_RANK
RANK() 生成数据项在分组中的排名,排名相等会在名次中 留下空位 。
DENSE_RANK()生成数据项在分组中的排名,排名相等会在名次中不会留下空位
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM itcast_t2
WHERE cookieid = 'cookie1';
2.3 ntile 抽样
把有序的数据集合平均分配到指定的数量的桶中,将桶号分配给每一行 如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1
SELECT
cookieid,
createtime,
pv,
NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn1,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2,
NTILE(4) OVER(ORDER BY createtime) AS rn3
FROM itcast_t2
ORDER BY cookieid,createtime;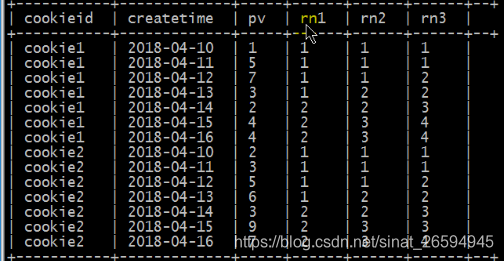
二、压缩
1、优缺点
优点:减少存储磁盘空间、减少网络传输带宽
缺点:需要花费额外的时间/CPU做压缩和解压缩计算
2、压缩分析
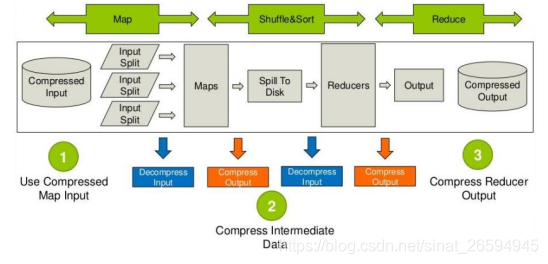
需要分析处理的数据在进入map前可以压缩,然后解压处理,map处理完成后的输出可以压缩,这样可以减
少网络 I/O(reduce 通常和 map 不在同一节点上), reduce 拷贝压缩的数据后进行解压,处理完成后可以压缩存储在 hdfs 上,以减少磁盘占用量。
3、hive的压缩设置
-- 开启hive中间传输数据压缩功能
1) 开启 hive 中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
2) 开启 mapreduce 中 map 输出压缩功能
set mapreduce.map.output.compress=true;
3) 设置 mapreduce 中 map 输出数据的压缩方式
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
-- 开启 Reduce 输出阶段压缩
1) 开启 hive 最终输出数据压缩功能
set hive.exec.compress.output=true;
2) 开启 mapreduce 最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
3) 设置 mapreduce 最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
4)设置 mapreduce 最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;三、存储
1、行式存储和列式存储(压缩快)
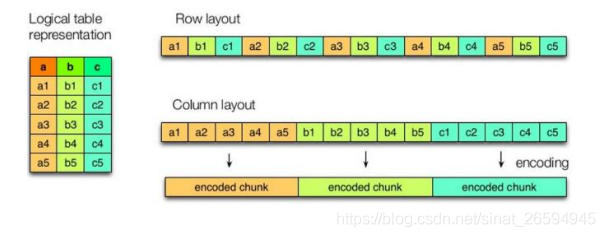
hive 支持的存储数的格式主要有 textfile(行式存储) orc(列式存储,也是以二进制存储的,所以是不可以直接读取,orc文件也是自解析的)
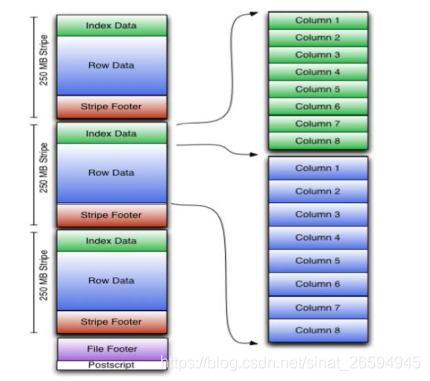
2、了解orc结构
一个orc文件可以分为若干个stripe 一个stripe可以分为三个部分
indexData:某些数据的索引信息 默认是 每隔一万行做一个索引
rowdata:真正的数据存储
stripfooter:stripe的元数据信息
压缩比 ORC>Parquet>textFile
在实际的项目开发当中, hive 表的数据存储格式一般选择: orc 或 parquet。压缩方式一般选择 snappy。
四、调优
1、Fetch抓取机制
hive对某些情况的查询是不必使用mapreduce计算 在这种那个情况下 hive可以简单的读取对应的目录下的文件
然后把结果输出来
在hive——default.xml.template文件中 hive.fetch.task.conversion默认的是more 当为more的时候 在全局查找、字段查找、limit查找等都不走mr;
2、mapreduce本地模式
mr程序除了可以提交到yarn上运行 他也可以在本地模式运行 此时就不是分布式执行的程序了,但是针对小文件小数据处理还是很有效果的;
用户可以自己设置hive.exec.mode.local.auto的值为true,来让hive在适当的时候自动启动这个优化
he total input size of the job is lower than:hive.exec.mode.local.auto.inputbytes.max (128MB by default)
The total number of map-tasks is less than:hive.exec.mode.local.auto.tasks.max (4 by default)
The total number of reduce tasks required is 1 or 0.3、join查询的优化
多个表关联的时候,最好分拆成小段的sql分段执行,避免一个大sql(无法控制中间job)
4、group by优化 -map端聚合
默认情况下, 当进行 group by 的时候, Map 阶段同一 Key 数据分发给一个reduce,当一个 key 数据过大时就倾斜了。
但并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先
在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果。
(1)是否在 Map 端进行聚合,默认为 True
set hive.map.aggr = true;
(2)在 Map 端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
(3) 有数据倾斜的时候进行负载均衡(默认是 false)
set hive.groupby.skewindata = true;
当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一
个 Reduce 中),最后完成最终的聚合操作5、数据倾斜的问题
5.1 maptask个数调整
5.2 reducetask个数调整
6、了解执行计划-explain
7、并行执行机制
8、严格模式
9、vm重用机制
10、推测执行机制