一、消息队列的介绍
消息:网络间传递的数据
消息队列:(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,

二、常用的消息队列介绍
1)RabbitMQ
是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。
2)ActiveMQ
ActiveMQ是由Apache出品,它非常快速,支持多种语言的客户端和协议,而且可以非常容易的嵌入到企业的应用环境中,并有许多高级功能
3)RocketMQ
阿里出品,参考kafka做出的改进,消息可靠性比kafka好。
4)kafka
Apache Kafka是一个分布式消息发布订阅系统,Kafka系统快速、可扩展并且可持久化,它的分区特性,可复制和可容错都是其不错的特性
5)消息队列的对比

三、消息队列的应用场景
1)应用耦合
将多个应用之间进行解耦合

2)异步处理
多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间;
3)限流削峰
广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况;先把流量放入消息队列中,然后再去消费
4)消息驱动的系统
系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理;
四、消息队列的两种模式
1)点对点模式(一个生产者和一个消费者)

消息发送者生产消息发送到queue中,然后消息接收者从queue中取出并且消费消息。消息被消费以后,queue中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
点对点模式特点:
• 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中);
• 送者和接发收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
• 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
2)发布-订阅模式(生产者和多个消费者)
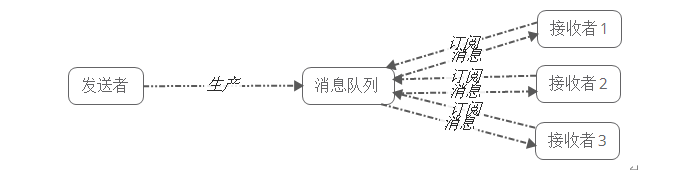
发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
发布/订阅模式特点:
• 每个消息可以有多个订阅者;
• 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
• 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
五、kafka的基本介绍
kafka:一个消息队列,afka是一个分布式,分区的,多副本的,多订阅者的日志系统(分布式MQ系统),使用scala编写。
kafka是顺序读写。
流式处理:flume + kafka + sparksteaming(flink)
六、kafka的架构介绍

1)生产者API
允许应用程序发布记录流至一个或者多个kafka的主题(topics)。
2)消费者API
首先订阅主题,基于主题来消费数据
3)SteamsAPI
流处理针对的主题中的数据,按照流的方式进行处理
4)ConnectAPI
应用连接的API
七、kafka架构内部细节剖析


说明:kafka支持消息持久化,消费端为拉模型来拉取数据,消费状态和订阅关系有客户端负责维护,消息消费完 后,不会立即删除,会保留历史消息。因此支持多订阅时,消息只会存储一份就可以了。
-- Broker:kafka集群中包含一个或者多个服务实例,这种服务实例被称为Broker
-- Topic:每条发布到kafka集群的消息都有一个类别,这个类别就叫做Topic
-- Partition:Partition是一个物理上的概念,每个Topic包含一个或者多个Partition
-- segment:一个partition当中存在多个segment文件段,每个segment分为两部分,.log文件和.index文件,其中.index文件是索引文件,主要用于快速查询.log文件当中数据的偏移量位置
-- Producer:负责发布消息到kafka的Broker中。
-- Consumer:消息消费者,向kafka的broker中读取消息的客户端
-- Consumer Group:每一个Consumer属于一个特定的Consumer Group(可以为每个Consumer指定 groupName)
.log:存放数据文件
.index:存放.log文件的索引数据 稀疏存储

八、kafka主要组件说明
1)producer
producer主要用于生产消息,是kafka当中的消息生产者,生产的消息通过topic分类,保存到kafka的broker里面去
2)topic
kafka将消息以topic为单位进行分类
topic特指kafka处理的消息源的不同分类
kafka主题始终是支持多用户订阅的 ,在kafka集群中,可以有无数的主题,生产者和消费者数据一般以主题为单位
3)partition
一个topic可以有多个分区,每个分区保存部分的topic数据,所有分区当中的数据合并起来就是一个topic当中所有的数据
每一个分区的数据是有序的
partition数量决定了每个Consumer group中并发消费者的最大数量
4)segment
一个partition单重由多个segment文件组成,每个segment文件,包含两部分,一个是.log文件。另外一个是.index文件,
.log文件包含了我们发送的数据存储
.index文件,记录的是我们.log文件的数据索引值,以便我们加快数据的查询速度
5)kafka分区与消费组的关系
消费组:由一个或者多个消费者组成,同一个组中的消费者对于同一条消息只消费一次。
某一个主题下的分区数,对于消费组来说,应该小于等于主题下的分区数
同一个分区下的数据,在同一个时刻,不能同一个消费组的不同消费者消费
总结:分区数越多,同一时间可以有越多的消费者来进行消费,消费数据的速度就会越快,提高消费的性能
6)consumer
kafka中的消费者,任何时刻,一个分区当中的数据,只能被kafka当中同一个消费组下面的一个县城消费
九、kafka的log存储以及查询机制
kafka中log日志目录及组成
kafka在我们指定的log.dir目录下,会创建一些文件夹,名字是 主题名+分区名,在此目录下,会有两个文件夹存在,.log和.index文件
这个文件,会根据log日志的大小进行切分,.log文件的大小为1G的时候,就会进行切分文件
十、数据不丢失机制
1、从生产者的角度来考虑
同步:发送一批数据给kafka,等待kafka返回结果
1、生产者等待10s,如果broker没有给出ack相应,就认为失败。
2、生产者重试3次,如果还没有响应,就报错
异步:发送一批数据给kafka,只是提供一个回调函数。
1、先将数据保存在生产者端的buffer中。buffer大小是2万条
2、满足数据阈值或者数量阈值其中的一个条件就可以发送数据。
3、发送一批数据的大小是500条
说明:如果broker迟迟不给ack,而buffer又满了,开发者可以设置是否直接清空buffer中的数据。ack确认机制
生产者数据发送出去,需要服务端返回一个确认码,即ack响应码;ack的响应有三个状态值
0:生产者只负责发送数据,不关心数据是否丢失,响应的状态码为0(丢失的数据,需要再次发送 )
1:partition的leader收到数据,响应的状态码为1
-1:所有的从节点都收到数据,响应的状态码为-12、kafka的broker中数据不丢失
在broker中,保证数据不丢失主要是通过副本因子(冗余),防止数据丢失3、消费者消费数据不丢失
在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失。十一、CAP理论以及kafka当中的CAP机制(三个指标最多满足两个)
一致性(Consisitency):数据的一致性.
强一致性:分布式系统是有节点可以立即感知数据的变化并更新。
弱一致性:数据有所改变,其他节点很长时间更新甚至不更新。
完全一致性:经过一定时间,最终完成数据的一致
可用性(Availability):
任何一个没有发生故障的节点必须在有限的时间内返回合理的结果
分区容错性(Partition tolerance):
部分节点宕机或者无法与其它节点通信时,各分区间还可保持分布式系统的功能